Extract content from web pages, including link URLs, image URLs and entire web page contents.
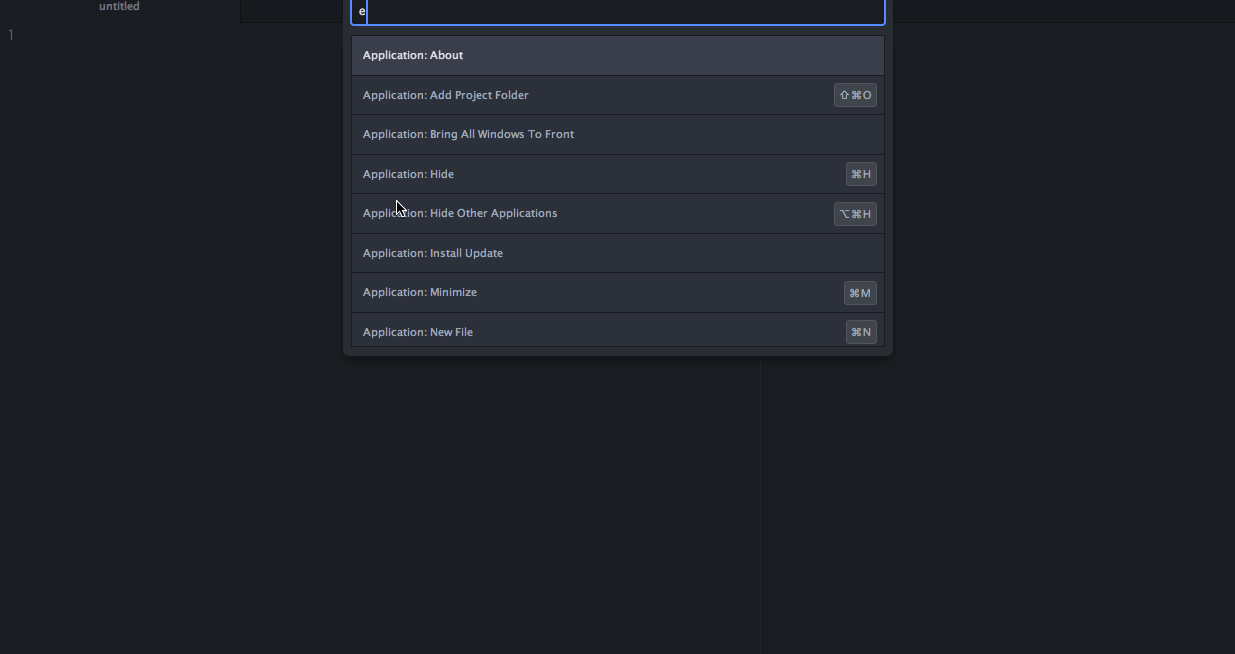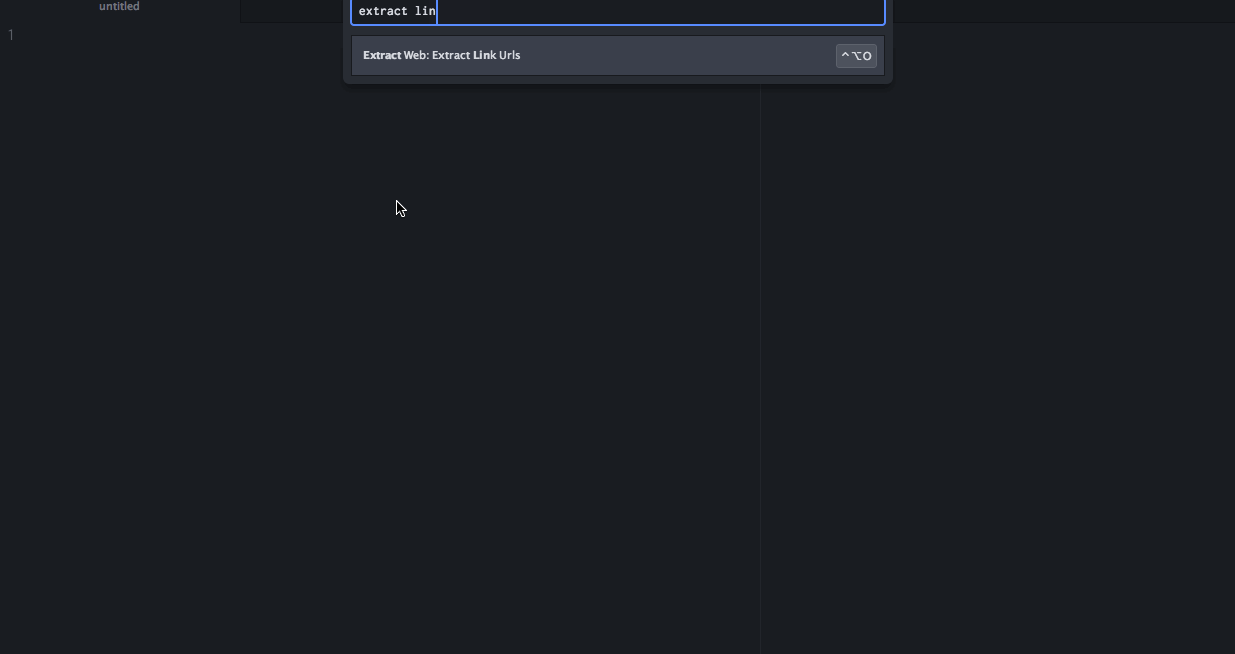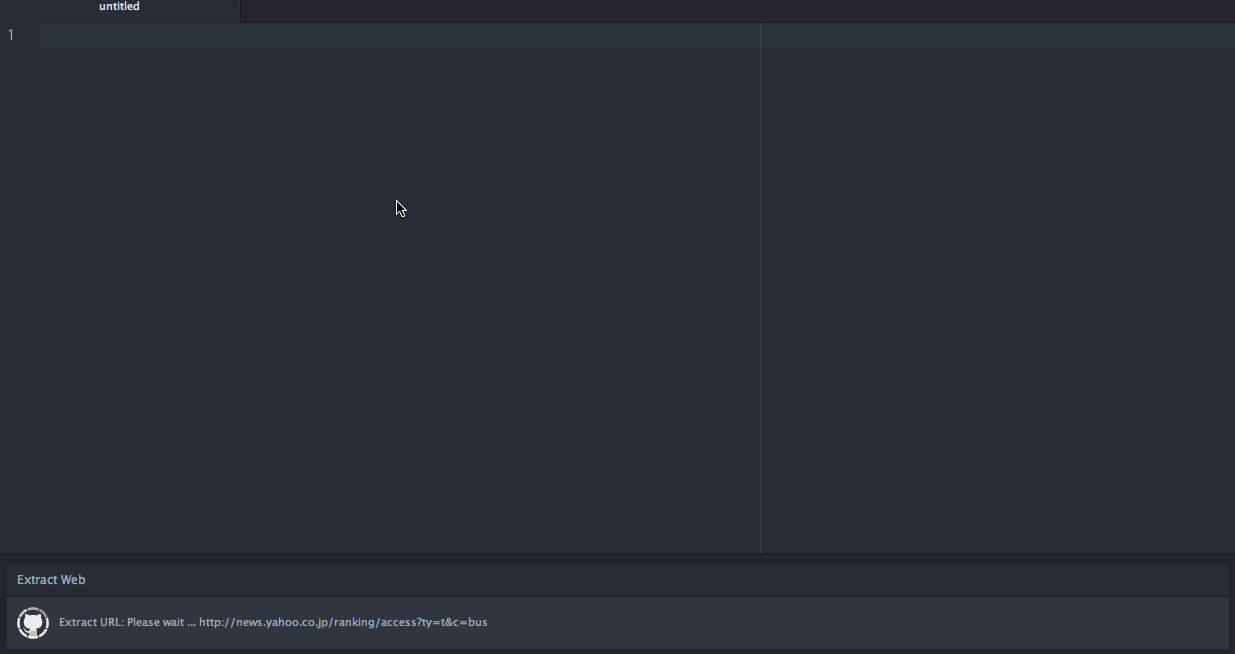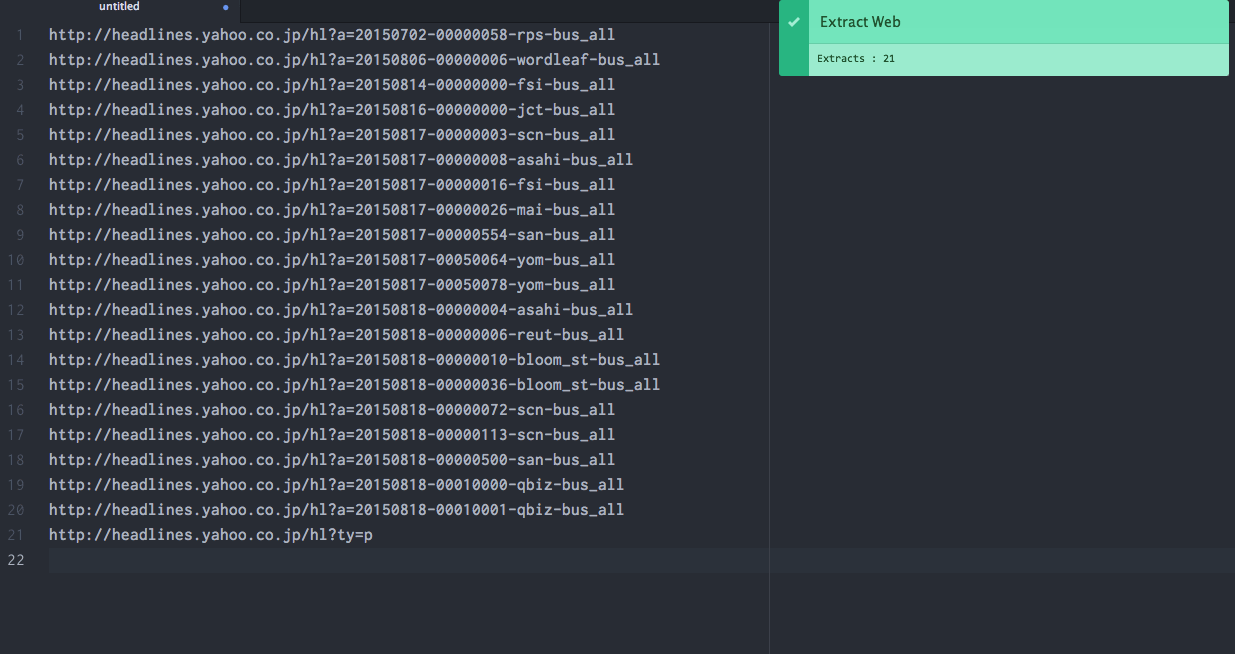
- Extract Web: Extract Link URLs
- Extracts all the URLs from links in the target page.
- Extract Web: Extract Image URLs
- Extracts all the URLs from images in the target page.
- Extract Web: Extract Contents
- Extracts the HTML content of the target page to a JSON or YAML document. Requires a URL list.
- User-Agent:
- Valid values:
android,chrome,googlebot,ie,ios,opera,safari - Default value:
chrome
- Valid values:
- Accept-Language:
- Default value:
en
- Default value:
- Extract URL Pattern:
- Filters the URLs returned by the
Extract Link URLsandExtract Image URLscommands using a regular expression. - Default:
https?://.+
- Filters the URLs returned by the
- Extract Contents Config Path:
- The location of a JSON file that determines the setting used by the
Extract Contentscommand. An example is included in the package asdefault-config.json. - Default value:
extract-web/default-config.json
- The location of a JSON file that determines the setting used by the
- Extract Contents Output Format:
- Determines the format of the output of the
Extract Contentscommand. - Valid values:
json,yaml - Default value:
json
- Determines the format of the output of the
- JSON Indent Size
- Sets the indentation used in the output for the
Extract Contentscommand when it is in JSON mode. - Default value:
2
- Sets the indentation used in the output for the
- YAML Indent Size
- Sets the indentation used in the output for the
Extract Contentscommand when it is in YAML mode. - Default value:
2
- Sets the indentation used in the output for the
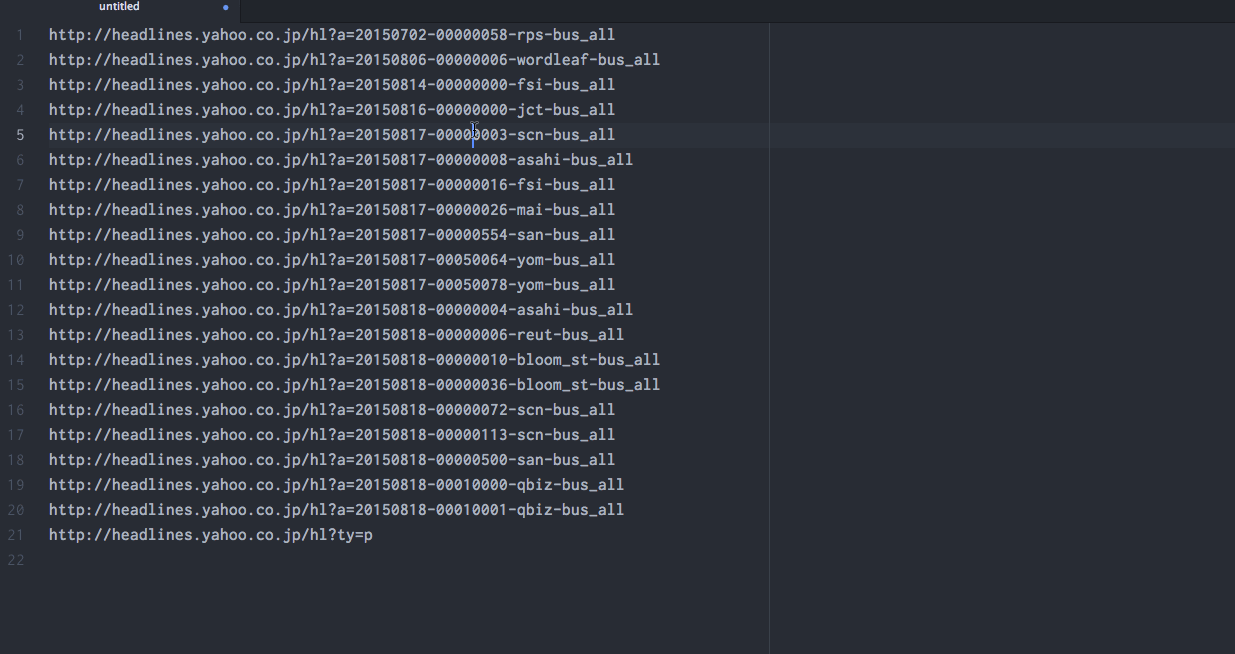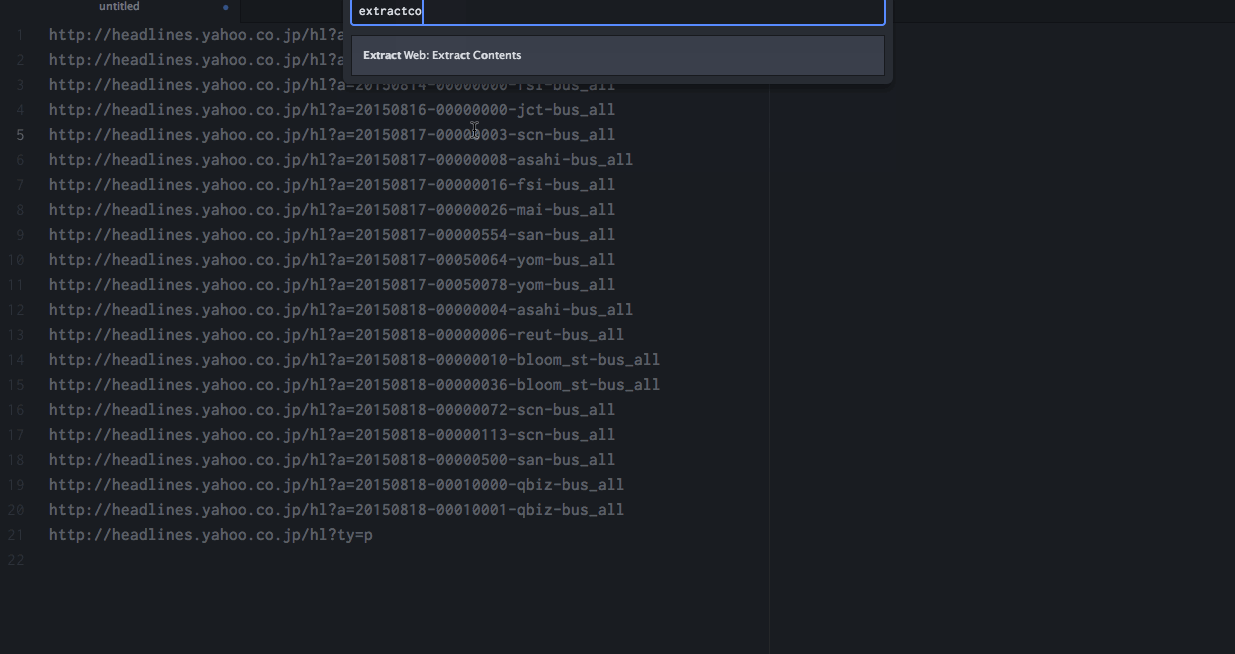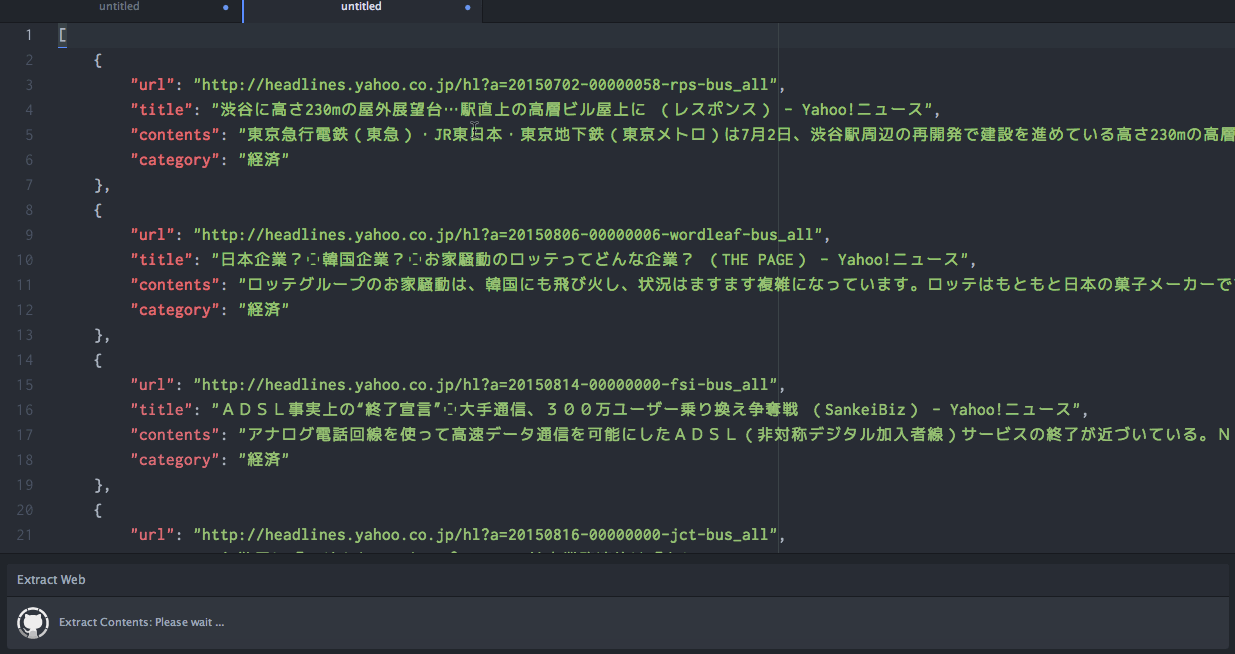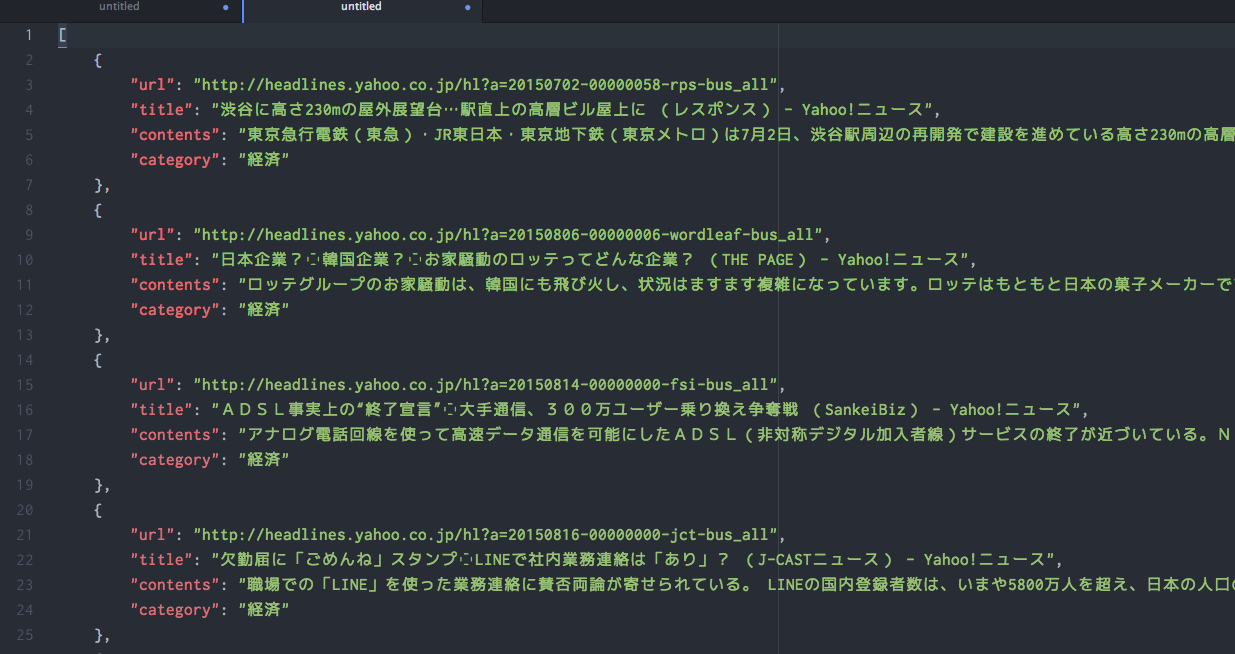
The Extract Contents command outputs a JSON or YAML document containing an array of objects. Each extracted web page is represented by a JSON/YAML object in this array.
The properties object for each extracted web page contains an array of properties extracted from the web page.
If you want to customize the properties extracted from each item, prepare a configuration file similar to the example below. Properties to extract are specified using CSS syntax.
Example:
{
"target": [
{
"pattern": {
"url": "https://atom.io/packages/.*"
},
"properties": {
"title": {
"text": "title"
},
"body": {
"text": "body"
},
"bodyAsHtml": {
"html": "body"
},
"package_meta": {
"text": ".package-meta ul li a",
"isArray": true
},
"meta_description": {
"attr": "meta[name=description]",
"args": ["content"]
},
"domain": {
"default": "atom.io"
}
}
}
]
}