Dogen v1.0.31, "Exeunt Academia"

Graduation day for the PhD programme of Computer Science at the University of Hertfordshire, UK. (C) 2022 Shahinara Craveiro.
Introduction
After an hiatus of almost 22 months, we've finally managed to push another Dogen release out of the door. Proud of the effort as we are, it must be said it isn't exactly the most compelling of releases since the bulk of its stories are related to basic infrastructure. More specifically, the majority of resourcing had to be shifted towards getting Continuous Integration (CI) working again, in the wake of Travis CI's managerial changes. However, the true focus of the last few months lays outside the bounds of software engineering; our time was spent mainly on completing the PhD thesis, getting it past a myriad of red-tape processes and perhaps most significantly of all, on passing the final exam called the viva. And so we did. Given it has taken some eight years to complete the PhD programme, you'll forgive us for the break with the tradition in naming releases after Angolan places or events; regular service will resume with the next release, on this as well as on the engineering front <knocks on wood, nervously>. So grab a cupper, sit back, relax, and get ready for the release notes that mark the end of academic life in the Dogen project.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. The demo spends some time reflecting on the PhD programme overall.
Video 1: Sprint 31 Demo.
Deprecate support for dumping tracing to a relational database
It wasn't that long ago Dogen was extended to dump tracing information into relational databases such as PostgreSQL and their ilk. In fact, v1.0.20's release notes announced this new feature with great fanfare, and we genuinely had high hopes for its future. You are of course forgiven if you fail to recall what the fuss was all about, so it is perhaps worthwhile doing a quick recap. Tracing - or probing as it was known then - was introduced in the long forgotten days of Dogen v1.0.05, the idea being that it would be useful to inspect model state as the transform graph went through its motions. Together with log files, this treasure trove of information enabled us to quickly understand where things went wrong, more often than not without necessitating a debugger. And it was indeed incredibly useful to begin with, but we soon got bored of manually inspecting trace files. You see, the trouble with these crazy critters is that they are rather plump blobs of JSON, thus making it difficult to understand "before" and "after" diffs for the state of a given model transform - even when allowing for json-diff and the like. To address the problem we doubled-down on our usage of JQ, but the more we did so, the clearer it became that JQ queries competed in the readability space with computer science classics like regular expressions and perl. A few choice data points should give a flavour of our troubles:
# JQ query to obtain file paths:
$ jq .models[0].physical.regions_by_logical_id[0][1].data.artefacts_by_archetype[][1].data.data.file_path
# JQ query to sort models by elements:
$ jq '.elements|=sort_by(.name.qualified)'
# JQ query for element names in generated model:
$ jq ."elements"[]."data"."__parent_0__"."name"."qualified"."dot"It is of course deeply unfair to blame JQ for all our problems, since "meaningful" names such as __parent_0__ fall squarely within Dogen's sphere of influence. Moreover, as a tool JQ is extremely useful for what it is meant to do, as well as being incredibly fast at it. Nonetheless, we begun to accumulate more and more of these query fragments, glued them up with complex UNIX shell pipelines that dumped information from trace files into text files, and then dumped diffs of said information to other text files which where then... - well, you get the drift. These scripts were extremely brittle and mostly "one-off" solutions, but at least the direction of travel was obvious: what was needed was a way to build up a number of queries targeting the "before" and "after" state of any given transform, such that we could ask a series of canned questions like "has object x0 gone missing in transform t0?" or "did we update field f0 incorrectly in transform t0?", and so on. One can easily conceive that a large library of these queries would accumulate over time, allowing us to see at a glance what changed between transforms and, in so doing, make routine investigations several orders of magnitude faster. Thus far, thus logical. We then investigated PostgreSQL's JSON support and, at first blush, found it to be very comprehensive. Furthermore, given that Dogen always had basic support for ODB, it was "easy enough" to teach it to dump trace information into a relational database - which we did in the aforementioned release.
Alas, after the initial enthusiasm, we soon realised that expressing our desired questions as database queries was far more difficult than anticipated. Part of it is related to the complex graph that we have on our JSON documents, which could be helped by creating a more relational-database-friendly model; and part of it is the inexperience with PostgreSQL's JSON query extensions. Sadly, we do not have sufficient time address either question properly, given the required engineering effort. To make matters worse, even though it was not being used in anger, the maintenance of this code was become increasingly expensive due to two factors:
- its reliance on a beta version of ODB (v2.5), for which there are no DEBs readily available; instead, one is expected to build it from source using Build2, an extremely interesting but rather suis generis build tool; and
- its reliance on either a manual install of the ODB C++ libraries or a patched version of vcpkg with support for v2.5. As vcpkg undergoes constant change, this means that every time we update it, we then need to spend ages porting our code to the new world.
Now, one of the rules we've had for the longest time in Dogen is that, if something is not adding value (or worse, subtracting value) then it should be deprecated and removed until such time it can be proven to add value. As with any spare time project, time is extremely scarce, so we barely have enough of it to be confused with the real issues at hand - let alone speculative features that may provide a pay-off one day. So it was that, with great sadness, we removed all support for the relational backend on this release. Not all is lost though. We use MongoDB a fair bit at work, and got the hang of its query language. A much simpler alternative is to dump the JSON documents into MongoDB - a shell script would do, at least initially - and then write Mongo queries to process the data. This is an approach we shall explore next time we get stuck investigating an issue using trace dumps.
Add "verbatim" PlantUML extension
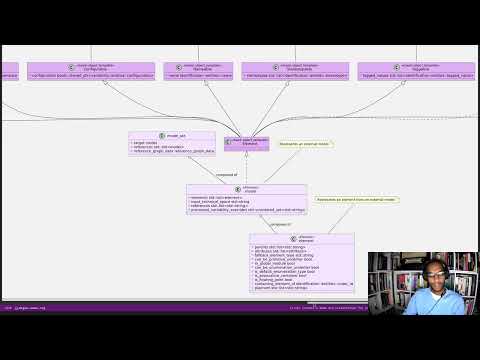
The quality of our diagrams degraded considerably since we moved away from Dia. This was to be expected; when we originally added PlantUML support in the previous release, it was as much a feasibility study as it was the implementation of a new feature. The understanding was that we'd have to spend a number of sprints slowly improving the new codec, until its diagrams where of a reasonable standard. However, this sprint made two things clear: a) just how much we rely on these diagrams to understand the system, meaning we need them back sooner rather than later; and b) just how much machinery is required to properly model relations in a rich way, as was done previously. Worse: it is not necessarily possible to merely record relations between entities in the input codec and then map those to a UML diagram. In Dia, we only modeled "significant relations" in order to better convey meaning. Lets make matters concrete by looking at a vocabulary type such as entities::name in model dogen::identification. It is used throughout the whole of Dogen, and any entity with a representation in the LPS (Logical-Physical Space) will use it. A blind approach of modeling each and every relation to a core type such as this would result in a mess of inter-crossing lines, removing any meaning from the resulting diagram.
After a great deal of pondering, we decided that the PlantUML output needs two kinds of data sources: automated, where the relationship is obvious and uncontroversial - e.g. the attributes that make up a class, inheritance, etc.; and manual, where the relationship requires hand-holding by a human. This is useful for example in the above case, where one would like to suppress relationships against a basic vocabulary type. The feature was implemented by means of adding a PlantUML verbatim attribute to models. It is called "verbatim" because we merely cut and paste the field's content into the PlantUML representation. By convention, these statements are placed straight after the entity they were added to. It is perhaps easier to understand this feature by means of an example. Say in the dogen.codec model one wishes to add a relationship between model and element. One could go about it as follows:

Figure 1: Use of the verbatim PlantUML property in the dogen.codec model.
As you can see, the property masd.codec.plantuml is extremely simple: it merely allows one to enter valid PlantUML statements, which are subsequently transported into the generated source code without modification, e.g.:

Figure 2: PlantUML source code for dogen.codec model.
For good measure, we can observe the final (graphical) output produced by PlantUML in Figure 3, with the two relations, and compare it with the old Dia representation (Figure 4). Its worth highlighting a couple of things here. Firstly - and somewhat confusingly - in addition to element, the example also captures a relationship with the object template Element. It was left on purpose as it too is a useful demonstration of this new feature. Note that it's still not entirely clear whether this is the correct UML syntax for modeling relationships with object templates - the last expert I consulted was not entirely pleased with this approach - but no matter. The salient point is not whether this specific representation is correct or incorrect, but that one can choose to use this or any other representation quite easily, as desired. Secondly and similarly, the aggregation between model_set, model and element is something that one would like to highlight in this model, and it is possible to do so trivially by means of this feature. Each of these classes is composed of a number of attributes which are not particularly interesting from a relationship perspective, and adding relations for all of those would greatly increase the amount of noise in the diagram.

Figure 3: Graphical output produced by PlantUML from Dogen-generated sources.
This feature is a great example of how often one needs to think of a problem from many different perspectives before arriving at a solution; and that, even though the problem may appear extremely complex at the start, sometimes all it takes is to view it from a completely different angle. All and all, the feature was implemented in just over two hours; we had originally envisioned lots of invasive changes at the lowers levels of Dogen just to propagate this information, and likely an entire sprint dedicated to it. To be fair, the jury is not out yet on whether this is really the correct approach. Firstly, because we now need to go through each and every model and compare the relations we had in Dia to those we see in PlantUML, and implement them if required. Secondly, we have no way of knowing if the PlantUML input is correct or not, short of writing a parser for their syntax - which we won't consider. This means the user will only find out about syntax errors after running PlantUML - and given it will be within generated code, it is entirely likely the error messages will be less than obvious as to what is causing the problem. Thirdly and somewhat related: the verbatim nature of this attribute entails bypassing the Dogen type system entirely, by design. This means that if this information is useful for purposes other than PlantUML generation - say for example for regular source code generation - we would have no access to it. Finally, the name masd.codec.plantuml is also questionable given the codec name is plantuml. Next release we will probably name it to masd.codec.plantuml.verbatim to better reflect its nature.

Figure 4: Dia representation of the dogen.codec model.
A possibly better way of modeling this property is to add a non-verbatim attribute such as "significant relationship" or "user important relationship" or some such. Whatever its name, said attribute would model the notion of there being an important relationship between some types within the Dogen type system, and it could then be used by the PlantUML codec to output it in its syntax. However, before we get too carried away, its important to remember that we always take the simplest possible approach first and wait until use cases arrive, so all of this analysis has been farmed off to the backlog for some future use.
Video series on MDE and MASD
In general, we tend to place our YouTube videos under the Development Matters section of the release notes because these tend to be about coding within the narrow confines of Dogen. As with so many items within this release, an exception was made for one of the series because it is likely to be of interest to Dogen developers and users alike. The series in question is called "MASD: An introduction to Model Assisted Software Development", and it is composed of 10 parts as of this writing. Its main objective was to prepare us for the viva, so the long arc of the series builds up to why one would want to create a new methodology and ends with an explanation of what that methodology might be. However, as we were unsure as to whether we could use material directly from the thesis, and given our shortness of time to create new material specifically for the series, we opted for a high-level description of the methodology; in hindsight, we find it slightly unsatisfactory due to a lack of visuals so we are considering an additional 11th part which reviews a couple of key chapters from the thesis (5 and 6).
At any rate, the individual videos are listed on Table 1, with a short description. They are also available as a playlist, as per link below.
Video 2: Playlist "MASD: An introduction to Model Assisted Software Development".
| Video | Description |
|---|---|
| Part 1 | This lecture is the start of an overview of Model Driven Engineering (MDE), the approach that underlies MASD. |
| Part 2 | In this lecture we conclude our overview of MDE by discussing the challenges the discipline faces in terms of its foundations. |
| Part 3 | In this lecture we discuss the two fundamental concepts of MDE: Models and Transformations. |
| Part 4 | In this lecture we take a large detour to think about the philosophical implications of modeling. In the detour we discuss Russell, Whitehead, Wittgenstein and Meyers amongst others. |
| Part 5 | In this lecture we finish our excursion into the philosophy of modeling and discuss two core topics: Technical Spaces (TS) and Platforms. |
| Part 6 | In this video we take a detour and talk about research, and how our programme in particular was carried out - including all the bumps and bruises we faced along the way. |
| Part 7 | In this lecture we discuss Variability and Variability Management in the context of Model Driven Engineering (MDE). |
| Part 8 | In this lecture we start a presentation of the material of the thesis itself, covering state of the art in code generation, and the requirements for a new approach. |
| Part 9 | In this lecture we outline the MASD methodology: its philosophy, processes, actors and modeling language. We also discuss the domain architecture in more detail. |
| Part 10 | In this final lecture we discuss Dogen, introducing its architecture. |
Table 1: Video series for "MASD: An introduction to Model Assisted Software Development".
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Milestones and Éphémérides
This sprint marks the end of the PhD programme that started in 2014.

Figure 5: PhD thesis within the University of Hertfordshire archives.
Significant Internal Stories
From an engineering perspective, this sprint had one goal which was to restore our CI environment. Other smaller stories were also carried out.
Move CI to GitHub actions
A great number of stories this sprint were connected with the epic of returning to a sane world of continuous integration; CI had been lost with the demise of the open source support in Travis CI. First and foremost, I'd like to give an insanely huge shout out to Travis CI for all the years of supporting open source projects, even when perhaps it did not make huge financial sense. Prior to this decision, we had relied on Travis CI quite a lot, and in general it just worked. To my knowledge, they were the first ones to introduce the simple YAML configuration for their IaC language, and it still supports features that we could not map to in our new approach (e.g. the infamous issue #399). So it was not without sadness that we lost Travis CI support and found ourselves needing to move on to a new, hopefully stable, home.
Whilst where at it, a second word of thanks goes out to AppVeyor who we have also used for the longest time, with very few complaints. For many years, AppVeyor have been great supporters of open source and free software, so a massive shout out goes to them as well. Sadly, we had to reconsider AppVeyor's use in the context of Travis CI's loss, and it seemed sensible to stick to a single approach for all operative systems if at all possible. Personally, this is a sad state of affairs because we are choosing to support one large monolithic corporation in detriment of two small but very committed vendors, but as always, the nuances of the decision making process are obliterated by the practicalities of limited resourcing with which to carry work out - and thus a small risk apetite for both the demise of yet another vendor as well as for the complexities that always arrive when dealing with a mix of suppliers.
And so our search begun. As we have support for GitHub, BitBucket and GitLab as Git clones, we considered these three providers. In the end, we settled on GitHub actions, mainly because of the wealth of example projects using C++. All things considered, the move was remarkably easy, though not without its challenges. At present we seem to have all Dogen builds across Linux, Windows and OSX working reliably - though, as always, much work still remains such as porting all of our reference products.

Figure 6: GitHub actions for the Dogen project.
Related Stories: "Move build to GitHub", "Can't see build info in github builds", "Update the test package scripts for the GitHub CI", "Remove deprecated travis and appveyor config files", "Create clang build using libc++", "Add packaging step to github actions", "Setup MSVC Windows build for debug and release", "Update build instructions in readme", "Update the test package scripts for the GitHub CI", "Comment out clang-cl windows build", "Setup the laptop for development", "Windows package is broken", "Rewrite CTest script to use github actions".
Improvements to vcpkg setup
As part of the move to GitHub actions, we decided to greatly simplify our builds. In the past we had relied on a massive hack: we built all our third party dependencies manually and placed them, as a zip, on DropBox. This worked, but updating these dependencies was a major pain and so done very infrequently. In particular, we often forgot the details on how exactly those builds had been done and where all of the libraries had been sourced. As part of the research on GitHub actions, it became apparent that the cool kids had moved en masse to using vcpkg within the CI itself , and employed a set of supporting actions to make this use case much easier than before (building on the fly, caching, and so on). This new setup is highly advantageous because it makes updating third party dependencies a mere git submodule update, like so:
$ cd vcpkg/
$ git pull origin master
remote: Enumerating objects: 18250, done.
remote: Counting objects: 100% (7805/7805), done.
remote: Compressing objects: 100% (129/129), done.
remote: Total 18250 (delta 7720), reused 7711 (delta 7676), pack-reused 10445
Receiving objects: 100% (18250/18250), 9.05 MiB | 3.07 MiB/s, done.
Resolving deltas: 100% (12995/12995), completed with 1774 local objects.
...
$ cmake --build --preset linux-clang-release --target rat
While we were there, we took this opportunity and simplified all dependencies; sadly this meant removing our use of ODB since v2.5 is not available on vcpkg (see above). The feature is still present on the code generator, but one wonders if it should be completely deprecated next release when we get to the C++ reference product. Boost.DI was also another victim of this clean up. At any rate, the new setup is a productivity improvement of several orders of magnitude, since in the past we had to have our own OSX and Windows Physicals/VM's to build the dependencies whereas now we rely solely on vcpkg. For an idea of just how painful things used to be, just have a peek at "Updating Boost Version" in v1.0.19
Related Stories: "Update vcpkg to latest", "Remove third-party dependencies outside vcpkg", "Update nightly builds to use new vcpkg setup".
Improvements to CTest and CMake scripts
Closely related to the work on vcpkg and GitHub actions was a number of fundamental changes to our CMake and CTest setup. First and foremost, we like to point out the move to use CMake Presets. This is a great little feature in CMake that enables packing all of the CMake configuration into a preset file, and removes the need for the good old build.* scripts that had littered the build directory. It also means that building from Emacs - as well as other editors and IDEs which support presets, of course - is now really easy. In the past we had to supply a number o environment variables and other such incantations to the build script in order to setup the required environment. With presets all of that is encapsulated into a self comntained CMakePresets.json file, making the build much simpler:
cmake --preset linux-clang-release
cmake --build --preset linux-clang-release
You can also list the available presets very easily:
$ cmake --list-presets
Available configure presets:
"linux-clang-debug" - Linux clang debug
"linux-clang-release" - Linux clang release
"linux-gcc-debug" - Linux gcc debug
"linux-gcc-release" - Linux gcc release
"windows-msvc-debug" - Windows x64 Debug
"windows-msvc-release" - Windows x64 Release
"windows-msvc-clang-cl-debug" - Windows x64 Debug
"windows-msvc-clang-cl-release" - Windows x64 Release
"macos-clang-debug" - Mac OSX Debug
"macos-clang-release" - Mac OSX Release
This ensures a high degree of regularity of Dogen builds if you wish to stick to the defaults, which is the case for almost all our use cases. The exception had been nightlies, but as we explain elsewhere, with this release we also managed to make those builds conform to the same overall approach.
The release also saw a general clean up of the CTest script, now called CTest.cmake, which supports both continuous as well as nighly builds with minimal complexity. Sadly, the integration of presets with CTest is not exactly perfect, so it took us a fair amount of time to work out how to best get these two to talk to each other.
Related Stories: "Rewrite CTest script to use github actions", "Assorted improvements to CMake files"
Smaller stories
In addition to the big ticket items, a number of smaller stories was also worked om.
- Fix broken org-mode tests: due to the ad-hoc nature of our org-mode parser, we keep finding weird and wonderful problems with code generation, mainly related to the introduction of spurious whitelines. This sprint we fixed yet another group of these issues. Going forward, the right solution is to remove org-mode support from within Dogen, since we can't find a third party library that is rock solid, and add instead an XMI-based codec. We can then extend Emacs to generate this XMI output. There are downsides to this approach - for example, the loss of support to non-Emacs based editors such as VI and VS Code.
- Generate doxygen docs and add to site: Every so often we update manually the Doxygen docs available on our site. This time we also added a badge linking back to the documentation. Once the main bulk of work is finished with GitHub actions, we need to consider adding an action to regenerate documentation.
- Update build instructions in README*: This sprint saw a raft of updates to our REAMDE file, mostly connected with the end of the tesis as well as all the build changes related to GitHub actions.
- Replace Dia IDs with UUIDs: Now that we have removed Dia models from within Dogen, it seemed appropriate to get rid of some of its vestiges such as Object IDs based on Dia object names. This is yet another small step towards making the org-mode models closer to their native representation. We also begun work on supporting proper capitalisation of org-mode headings ("Capitalise titles in models correctly"), but sadly this proved to be much more complex than expected and has since been returned to the product backlog for further analysis.
- Tests should take full generation into account: Since time immemorial, our nightly builds have been, welll, different, from regular CI builds. This is because we make use of a feature called "full generation". Full generation forces the instantiation of model elements across all facets of physical space regardless of the requested configuration within the user model. This is done so that we exercise generated code to the fullest, and also has the great benefit of valgrinding the generated tests, hopefully pointing out any leaks we may have missed. One major down side of this approach was the need to somehow "fake" the contents of the Dogen directory, to ensure the generated tests did not break. We did this via the "pristine" hack: we kept two checkouts of Dogen, and pointed the tests of the main build towards this printine directory, so that the code geneation tests did not fail. It was ugly but just about worked. That is, until we introduced CMake Presets. Then, it caused all sorts of very annoying issues. In this sprint, after the longest time of trying to extend the hack, we finally saw the obvious: the easiest way to address this issue is to extend the tests to also use full generation. This was very easy to implement and made the nightlies regular with respect to the continuous builds.
Video series of Dogen coding
This sprint we recorded a series of videos titled "MASD - Dogen Coding: Move to GitHub CI". It is somewhat more generic than the name implies, because it includes a lot of the side-tasks needed to make GitHub actions work such as removing third party dependencies, fixing CTest scripts, etc. The video series is available as a playlist, in the link below.
Video 3: Playlist for "MASD - Dogen Coding: Move to GitHub CI".
The next table shows the individual parts of the video series.
| Video | Description |
|---|---|
| Part 1 | In this part we start by getting all unit tests to pass. |
| Part 2 | In this video we update our vcpkg fork with the required libraries, including ODB. However, we bump into problems getting Dogen to build with the new version of ODB. |
| Part 3 | In this video we decide to remove the relational model altogether as a way to simplify the building of Dogen. It is a bittersweet decision as it took us a long time to code the relational model, but in truth it never lived up to its original promise. |
| Part 4 | In this short video we remove all uses of Boost DI. Originally, we saw Boost DI as a solution for our dependency injection needs, which are mainly rooted in the registration of M2T (Model to Text) transforms. |
| Part 5 | In this video we update vcpkg to use latest and greatest and start to make use of the new standard machinery for CMake and vcpkg integration such as CMake presets. However, ninja misbehaves at the end. |
| Part 6 | In this part we get the core of the workflow to work, and iron out a lot of the kinks across all platforms. |
| Part 7 | In this video we review the work done so far, and continue adding support for nightly builds using the new CMake infrastructure. |
| Part 8 | This video concludes the series. In it, we sort out the few remaining problems with nightly builds, by making them behave more like the regular CI builds. |
Table 2: Video series for "MASD - Dogen Coding: Move to GitHub CI".
Resourcing
At almost two years elapsed time, this sprint was characterised mainly by its irregularity, and rendered metrics such as utilisation rate completely meaningless. It would of course be an unfair comment if we stopped at that, given how much was achieved on the PhD front; alas, lines of LaTex source count not towards the engineering of software systems. Focusing solely on the engineering front and looking at the sprint as a whole, it must be classified as very productive, since it was just over 85 hours long and broadly achieved its stated mission. It is always painful to spend this much effort just to get back to where we were in terms of CI/CD during the Travis CI golden era, but it is what it is. If anything, our modernised setup is a qualitative step up in terms of functionality when compared to the previous approach, so its not all doom and gloom.

Figure 7: Cost of stories for sprint 31.
In total, we spent just over 57% working on the GitHub CI move. Of these - in fact, of the whole sprint - the most expensive story was rewriting CTest scripts, at almost 16% of total effort. We also spent a lot of time updating nightly builds to use new vcpkg setup and performing assorted improvements to CMake files (9.3% and 7.6% respectively). It was somewhat disappointing that we did not manage to touch the reference products, which are at present still CI-less. Somewhat surprisingly we still managed to spend 13.3% of the total resource ask doing real coding; some of it justified (for example, removing the database options was a requirement for the GitHub CI move because we wanted to drop ODB) and some of it more of a form of therapy given the boredom of working on IaC (Infrastructure as Code). We also clocked just over 11% on working in the MDE and MASD video series, which is more broadly classified as PhD work; since it has an application to the engineering side, it was booked against the engineering work rather than the PhD programme itself.
A final note on the whopping 18.3% consumed on agile-related work. In particular, we spent an uncharacteristically large amount of time refining our sprint and product backlogs: 10% versus the 7% of sprint 30 and the 3.5% of sprint 29. Of course, in the context of thee many months with very little coding, it does make sense that we spent a lot of time dreaming about coding, and that is what the backlogs there are for. At any rate, over 80% of the resourcing this sprint can be said to be aligned with the core mission of the sprint, so one would conclude it was well spent.
Roadmap
We've never been particularly sold on the usefulness of our roadmaps, to be fair, but perhaps for historical reasons we have grown attached to them. There is little to add from the previous sprint: the big ticket items stay unchanged, and given our day release from work for the PhD will cease soon, it is expected that our utilisation rate will start to slow down correspondingly. The roadmap remains the same, nonetheless.


Binaries
As part of the GitHub CI move, the production of binaries has changed considerably. In addition, we are not yet building binaries off of the tag workflow so these links are against the last commit of the sprint - presumably the resulting build would have been identical. For now, we have manually uploaded the binaries into the release assets.
| Operative System | Binaries |
|---|---|
| Linux Debian/Ubuntu | dogen_1.0.31_amd64-applications.deb |
| Windows | DOGEN-1.0.31-Windows-AMD64.msi |
| Mac OSX | DOGEN-1.0.31-Darwin-x86_64.dmg |
Table 3: Binary packages for Dogen.
A few important notes:
- the Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
- as before, all binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
- a final note on the assets present on the release note. These are just pictures and other items needed by the release note itself. We found that referring to links on the internet is not a particularly good idea as we now have lots of 404s for older releases. Therefore, from now on, the release notes will be self contained. Assets are otherwise not used.
- we are not testing the OSX and Windows builds (e.g. validating the packages install, the binaries run, etc.). If you find any problems with them, please report an issue.
Next Sprint
The next sprint's mission will focus on mopping up GitHub CI - largely addressing the reference products, which were untouched this sprint. The remaining time will be allocated to the clean up of the physical model and meta-model, which we are very much looking forward to. It will be the first release with real coding in quite some time.
That's all for this release. Happy Modeling!