This portfolio consists of several projects illustrating the work I have done in order to further develop my data science skills.




BERTopic is a novel topic modeling technique that leverages BERT embeddings and c-TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions.

KeyBERT is a minimal and easy-to-use keyword extraction technique that leverages BERT embeddings to create keywords and keyphrases that are most similar to a document.
![]()
PolyFuzz performs fuzzy string matching, string grouping, and contains extensive evaluation functions. PolyFuzz is meant to bring fuzzy string matching techniques together within a single framework.
![]()
Repository | Notebook | nbviewer
- Created a package that allows in-depth analyses on whatsapp conversations
- Analyses were initially done on whatsapp messages between me and my fianciee to surprise her with on our wedding
- Visualizations were done in such a way that it would make sense for someone not familiar with data science
- Methods: Sentiment Analysis, TF-IDF, Topic Modeling, Wordclouds, etc.

- Using Reinforcement Learning, entities learn to survive, reproduce, and make sure to maximize the fitness of their kin.
- Implemented algorithms: DQN, PER-DQN, D3QN, PER-D3QN, and PPO


- It leverages clusters of word embeddings (i.e., concepts) to create features from a collection of documents allowing for classification of documents
- Inspiration was drawn from VLAD, which is a feature generation method for image classification
- The article was published in ECML-PKDD 2019

- Created an algorithm allowing for TF-IDF to work on a class-level
- Thereby creating categorical vectors that can be used for:
- Informative Words per Class: Which words make a class stand-out compared to all others?
- Class Reduction: Using c-TF-IDF to reduce the number of classes
- Semi-supervised Modeling: Predicting the class of unseen documents using only cosine similarity and c-TF-IDF
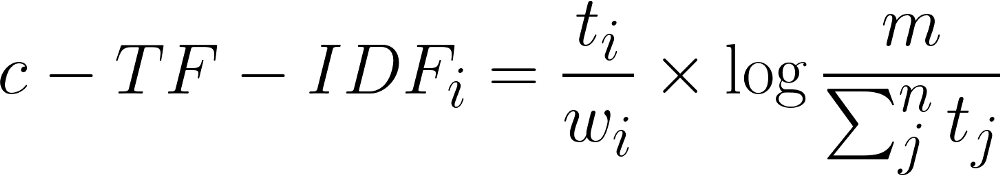
Repository | Notebook | nbviewer
Reviewer can be used to scrape user reviews from IMDB, generate word clouds based on a custom class-based TF-IDF, and extract popular characters/actors from reviews. Methods:
- Named Entity Recognition
- Sentiment Analysis
- Scraper
- BERT

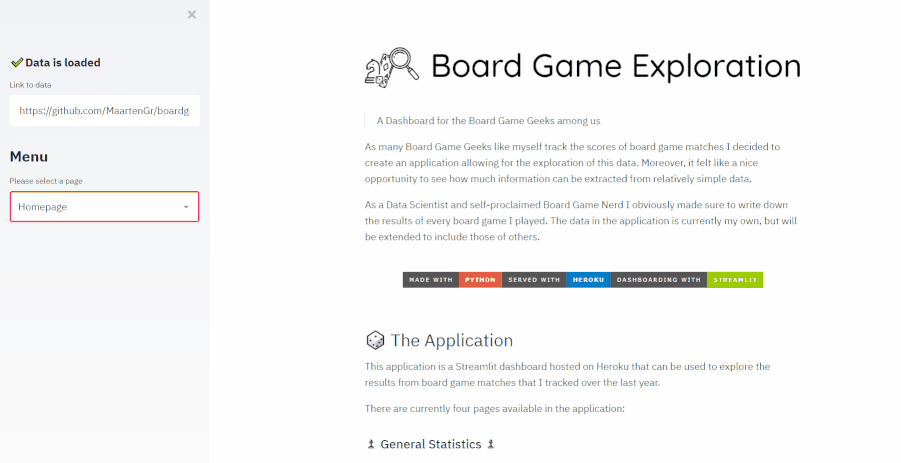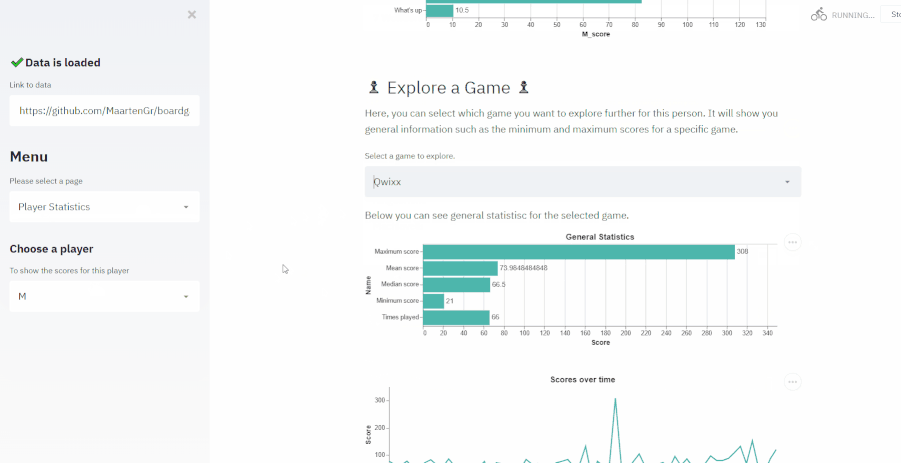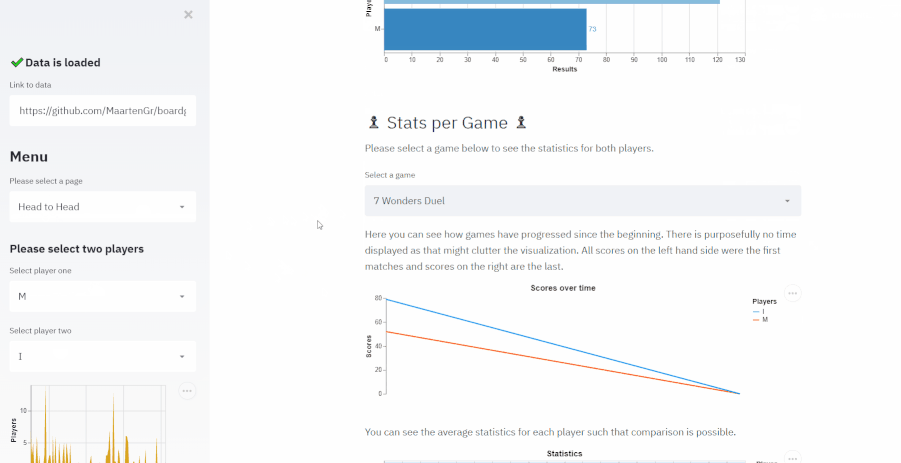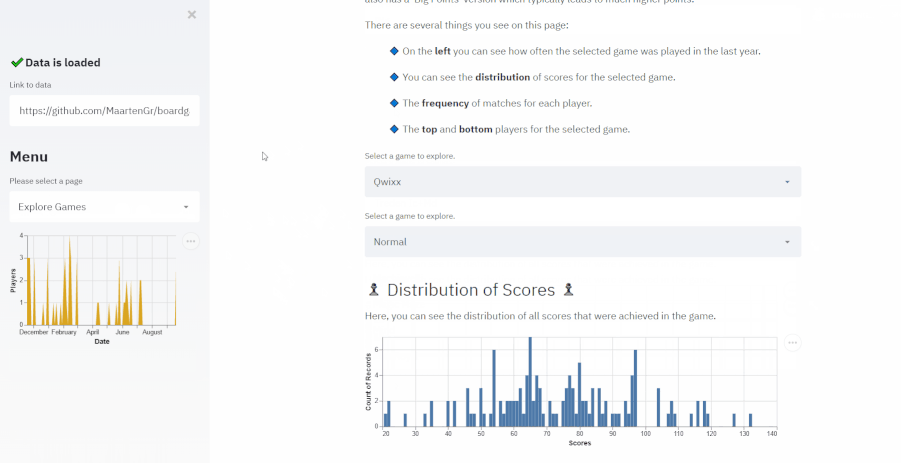
- Created an application for exploring board game matches that I tracked over the last year
- The application was created for two reasons:
- First, I wanted to surprise my wife with this application as we played mostly together
- Second, the data is relatively simple (5 columns) and small (~300 rows) and I wanted to demonstrate the possibilities of analyses with simple data
- Dashboard was created with streamlit and the deployment of the application was through Heroku
- Created a tournament game for a friend of mine
- Tournament brackets are generated based on a seed score calculated through scraping data from IMDB and RottenTomatoes
- Methods: BeautifulSoup

- Project for the course Business Analytics in the master
- Optimization of managers visiting a set of cities
- Total of 133 cities, max distance 400km with time and capacity constraints
- Thus, a vehicle routing problem
- Methods: Integer Linear Programming, Tabu Search, Simmulated Annealing, Ant Colony Optimization, Python

Repository | Notebook| nbviewer
- Image classification of potholes in roads
- Explored different activation functions (Relu, Leaky Relu, Swish, Mish)
- Used EfficientNetB0 and applied transfer learning to quickly get a high accuracy (> 95%)
- Unfreezing certain layers helps with fine tuning the model
- Methods: Deep Learning, TF/Keras, EfficientNetB0

Repository | Notebook | nbviewer | Medium
- Explored several methods for opening the black boxes that are tree-based prediction models
- Models included PDP, LIME, and SHAP

- Developed a set of steps necessary to quickly develop your machine learning model
- Used a combination of FastAPI, Uvicorn and Gunicorn to lay the foundation of the API
- The repository contains all code necessary (including dockerfile)

- An overview of methods for creating state-of-the-art RL-algorithms
- Makes use of Gym, Retro-gym, Procgen, and Stable-baselines

Repository | Notebook | nbviewer | Medium
- Dived into several more in-depth techniques for validating a model
- Statistical methods were explored for comparing models including the Wilcoxon signed-rank test, McNemar's test, 5x2CV paired t-test and 5x2CV combined F test

Repository | Notebook | nbviewer | Medium
- Explored several methods for creating customer segments; k-Means (Cosine & Euclidean) vs. DBSCAN
- Applied PCA and t-SNE for the 3 dimensional exploration of clusters
- Used variance between averages of clusters per variable to detect important differences between clusters

Repository | Notebook | nbviewer | Medium
- Several methods are described for advanced feature engineering including:
- Resampling Imbalanced Data using SMOTE
- Creating New Features with Deep Feature Synthesis
- Handling Missing Values with the Iterative Imputer and CatBoost
- Outlier Detection with IsolationForest

- Data received from an auction house and therefore not made public
- Prediction of value at which an item will be sold to be used as an objective measure
- Optimize starting price such that predicted value will be as high as possible
- Methods: Classification (KNN, LightGBM, RF, XGBoost, etc.), LOO-CV, Genetic Algorithms, Python

- Used Apple Store data to analyze which business model aspects influence performance of mobile games
- Two groups were identified and compared, namley early and later entrants of the market
- The impact of entry timing and the use of technological innovation was analyzed on performance
- Methods: Zero-Inflated Negative Binomial Regression, Hurdle model, Python, R

- Part of the course Data-Driven SCM
- Optimizing order quantity based on predicted demand using machine learning methods
- Simulation model was created to check performance of method calculating expected demand
- Additional weather features were included
- Methods: Regression (XGBoost, LightGBM and CatBoost), Bayesian Optimization (Skopt)

- Analyzing my own data provided by Google Takeout
- Location data, browser search history, mail data, etc.
- Code to analyze browser history is included
- Code to create animation will follow


- Created a dashboard for the cars dataset using Python, HTML and CSS
- It allows for several crossfilters (see below)

- Visualized 16 games I played with my wife
- The result is a heatmap in using the scorecard of Qwixx
- All rights belong to Qwixx (Nuernberger-Spielkarten-Verlag GmbH)
- The scorecard used for this visualization was retrieved from:
{kind=link}

- A visualization of my 9! year academic journey
- My grades and average across six educational programs versus the average of all other students in the same classes.
- Unfortunately, no data on the students’ average grade was available for classes in my bachelor.
- Grades range from 0 to 10 with 6 being a passing grade.
- Lastly, Cum Laude is the highest academic distinction for the master’s program I followed.


- For the course deep learning I worked on a paper researching optimal selection of hidden layers to create the most appealing images in neural style transfer while speeding up the process of optimization
- Code is not yet provided as I used most of the following code from here and I merely explored different layers
![]()
- Project for the course Machine Learning
- Participation of the kaggle competition House Prices: Advanced Regression Techniques
- We were graded on leaderboard scores and I scored 1st of the class with position 33th of the leaderboard
- I used a weighted average of XGBoost, Lasso, ElasticNet, Ridge and Gradient Boosting Regressor
- The focus of this project was mostly on feature engineering

Repository | Github | nbviewer
- My first data science project
- I looked at improving the quality of FitBit's heartrate measurement as I realized it wasn't all that accurate
- Used a simple 10-fold CV with regression techniques to fill missing heart rates
- There are many things that I would do differently now like using other validation techniques that are not as sensitive to overfitting on timeseries

If you are looking to contact me personally, please do so via E-mail or Linkedin: