
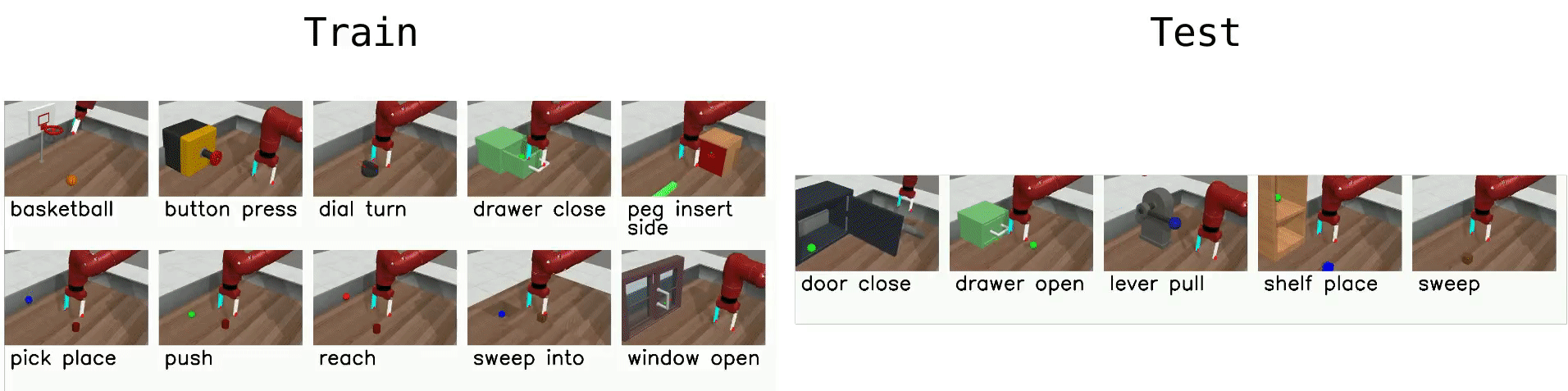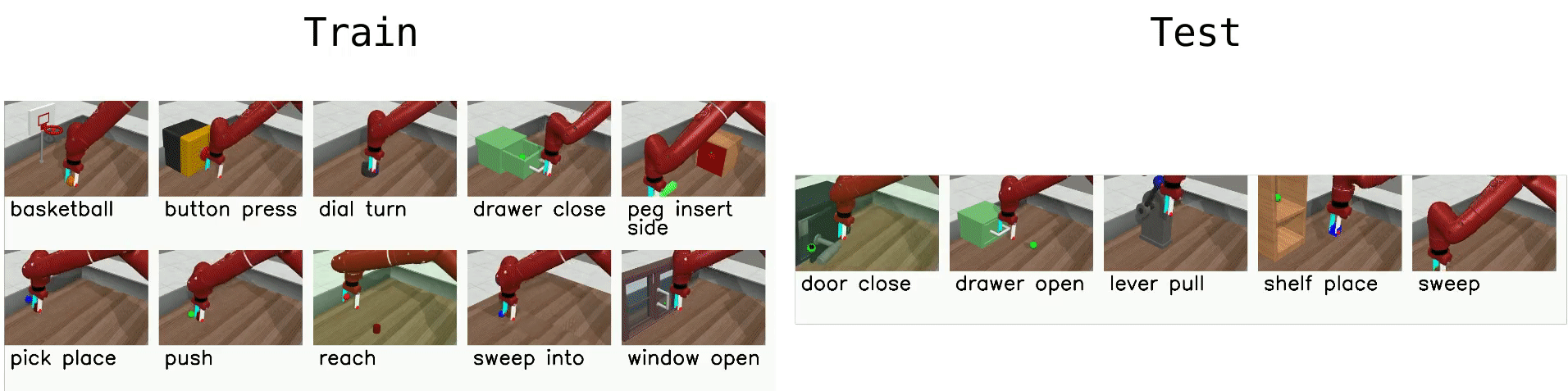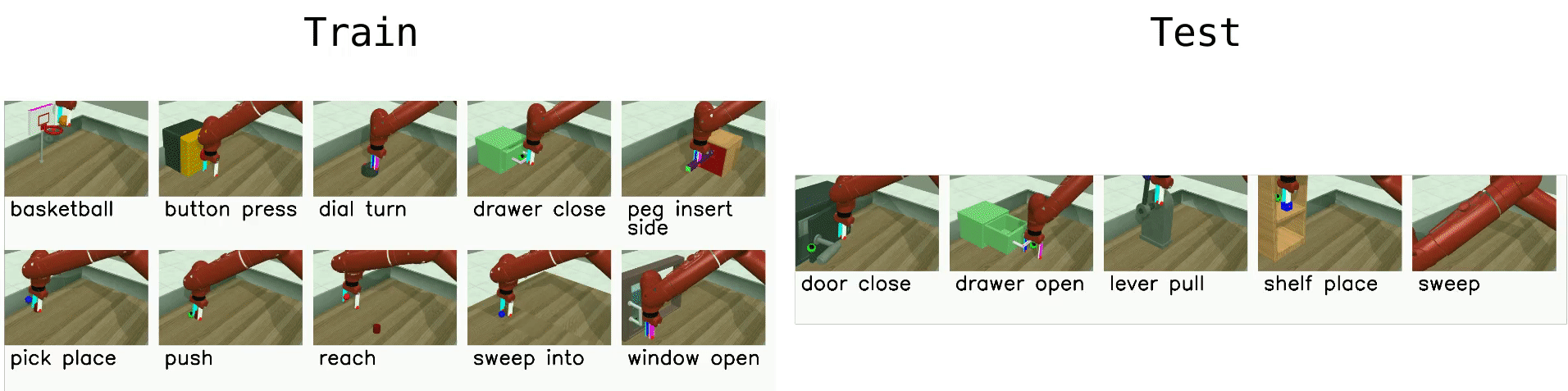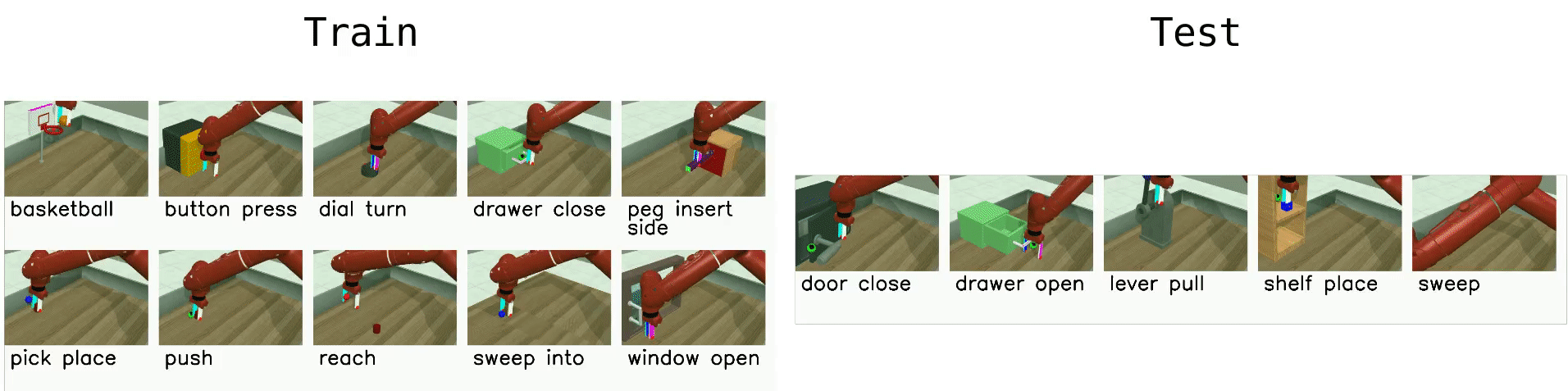
Meta-World is an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks. We aim to provide task distributions that are sufficiently broad to evaluate meta-RL algorithms' generalization ability to new behaviors.
For more background information, please refer to our website and the accompanying conference publication, which provides baseline results for 8 state-of-the-art meta- and multi-task RL algorithms.
Table of Contents
Meta-World is based on MuJoCo, which has a proprietary dependency we can't set up for you. Please follow the instructions in the mujoco-py package for help. Once you're ready to install everything, run:
pip install git+https://github.com/rlworkgroup/metaworld.git@master#egg=metaworld
Alternatively, you can clone the repository and install an editable version locally:
git clone https://github.com/rlworkgroup/metaworld.git
cd metaworld
pip install -e .
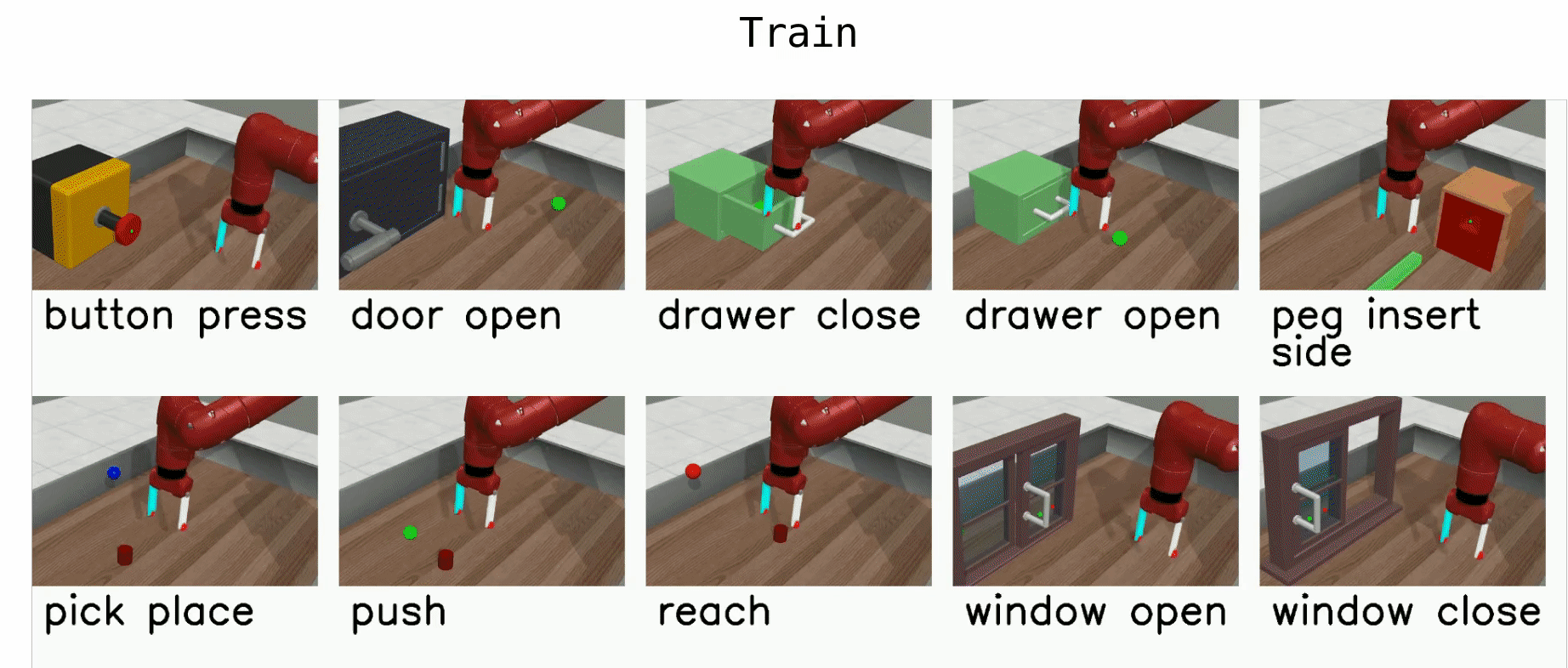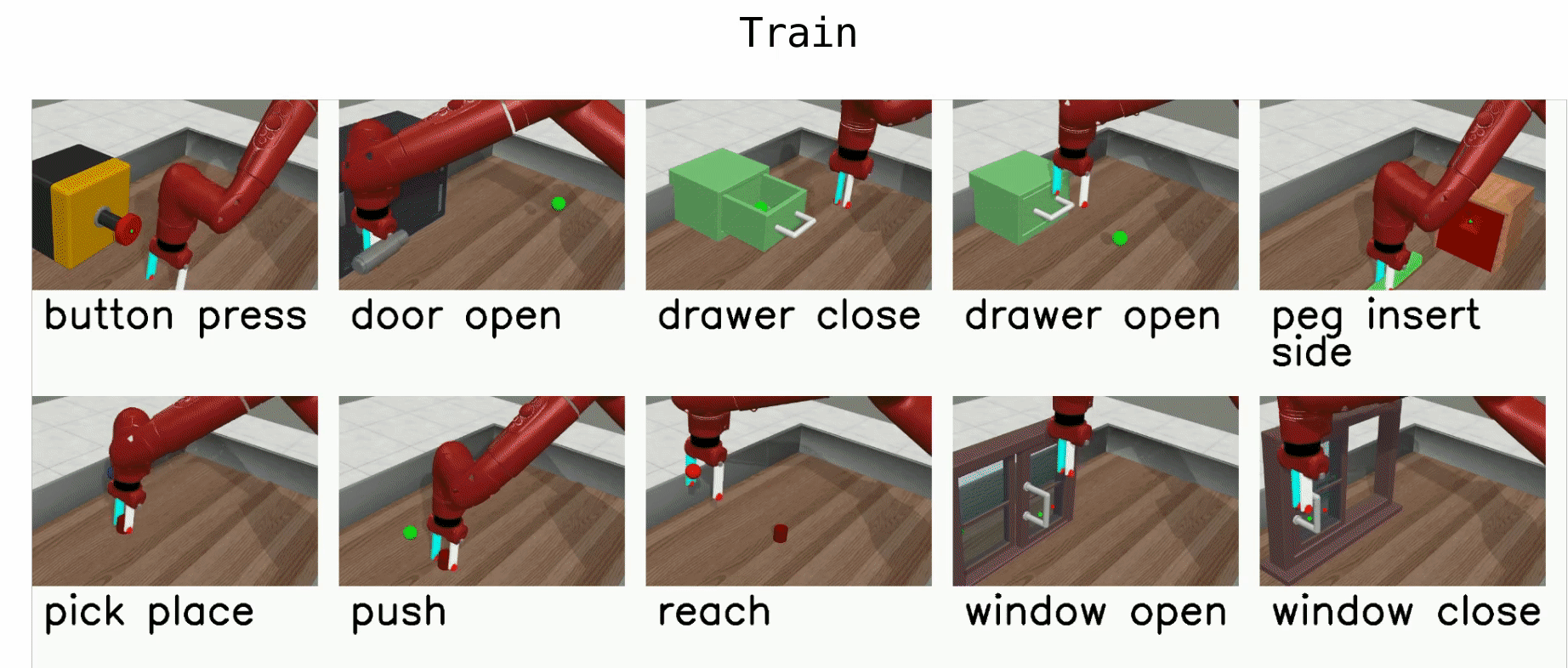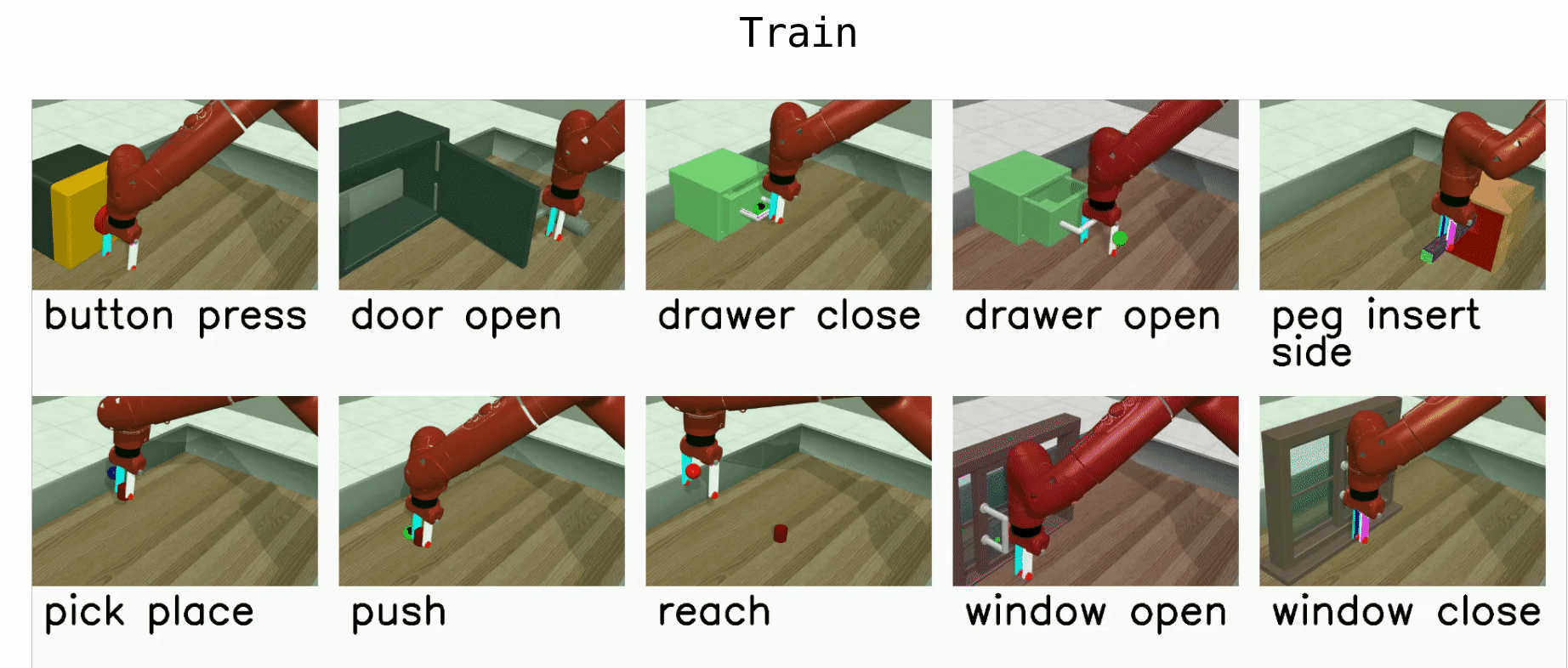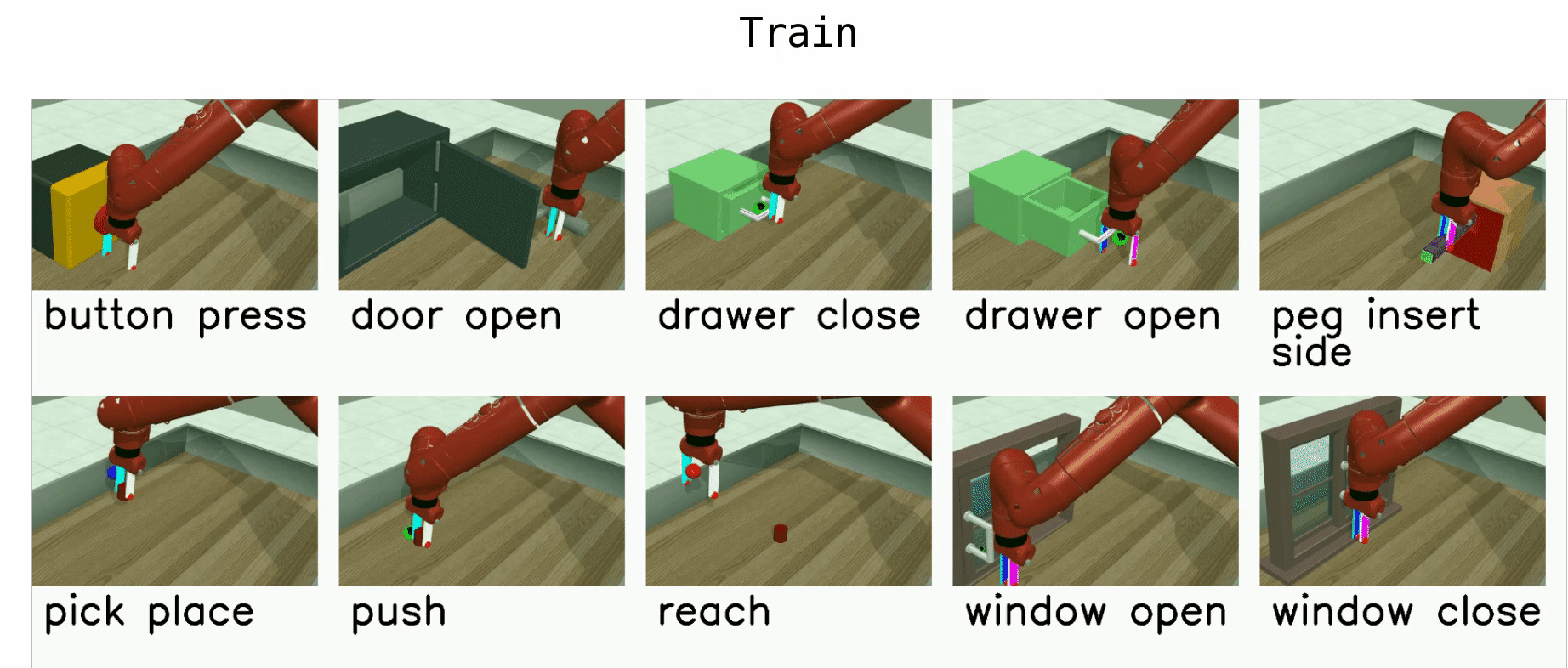
Here is a list of benchmark environments for meta-RL (ML*) and multi-task-RL (MT*):
- ML1 is a meta-RL benchmark environment which tests few-shot adaptation to goal variation within single task. You can choose to test variation within any of 50 tasks for this benchmark.
- ML10 is a meta-RL benchmark which tests few-shot adaptation to new tasks. It comprises 10 meta-train tasks, and 3 test tasks.
- ML45 is a meta-RL benchmark which tests few-shot adaptation to new tasks. It comprises 45 meta-train tasks and 5 test tasks.
- MT10 and MT50 are multi-task-RL benchmark environments for learning a multi-task policy that perform 10 and 50 training tasks respectively. MT10 and MT50 augment environment observations with a one-hot vector which identifies the task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We provide two extra API's to extend a gym.Env interface for meta-RL and multi-task-RL:
sample_tasks(self, meta_batch_size): Return a list of tasks with a length ofmeta_batch_size.set_task(self, task): Set the task of a multi-task environment.
from metaworld.benchmarks import ML1
print(ML1.available_tasks()) # Check out the available tasks
env = ML1.get_train_tasks('pick-place-v1') # Create an environment with task `pick_place`
tasks = env.sample_tasks(1) # Sample a task (in this case, a goal variation)
env.set_task(tasks[0]) # Set task
obs = env.reset() # Reset environment
a = env.action_space.sample() # Sample an action
obs, reward, done, info = env.step(a) # Step the environoment with the sampled random action
Create an environment with train tasks:
from metaworld.benchmarks import ML10
ml10_train_env = ML10.get_train_tasks()
Create an environment with test tasks:
ml10_test_env = ML10.get_test_tasks()
Create an environment with train tasks:
from metaworld.benchmarks import MT10
mt10_train_env = MT10.get_train_tasks()
Create an environment with test tasks (noted that the train tasks and test tasks for multi-task (MT) environments are the same):
mt10_test_env = MT10.get_test_tasks()
Meta-World can also be used as a normal gym.Env for single task benchmarking. Here is an example of creating a pick_place environoment:
from metaworld.envs.mujoco.sawyer_xyz import SawyerReachPushPickPlaceEnv
env = SawyerReachPushPickPlaceEnv()
You use Meta-World for academic research, please kindly cite our CoRL 2019 paper the using following BibTeX entry.
@inproceedings{yu2019meta,
title={Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning},
author={Tianhe Yu and Deirdre Quillen and Zhanpeng He and Ryan Julian and Karol Hausman and Chelsea Finn and Sergey Levine},
booktitle={Conference on Robot Learning (CoRL)},
year={2019}
eprint={1910.10897},
archivePrefix={arXiv},
primaryClass={cs.LG}
url={https://arxiv.org/abs/1910.10897}
}
We welcome all contributions to Meta-World. Please refer to the contributor's guide for how to prepare your contributions.
Meta-World is a work by Tianhe Yu (Stanford University), Deirdre Quillen (UC Berkeley), Zhanpeng He (Columbia University), Ryan Julian (University of Southern California), Karol Hausman (Google AI), Chelsea Finn (Stanford University) and Sergey Levine (UC Berkeley).
The code for Meta-World was originally based on multiworld, which is developed by Vitchyr H. Pong, Murtaza Dalal, Ashvin Nair, Shikhar Bahl, Steven Lin, Soroush Nasiriany, Kristian Hartikainen and Coline Devin. The Meta-World authors are grateful for their efforts on providing such a great framework as a foundation of our work. We also would like to thank Russell Mendonca for his work on reward functions for some of the environments.