Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
Source : https://rajpurkar.github.io/SQuAD-explorer/
BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP.
Unsupervised means that BERT was trained using only a plain text corpus, which is important because an enormous amount of plain text data is publicly available on the web in many languages.
In order to learn relationships between sentences, we also train on a simple
task which can be generated from any monolingual corpus: Given two sentences A
and B, is B the actual next sentence that comes after A, or just a random
sentence from the corpus?
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
We then train a large model (12-layer to 24-layer Transformer) on a large corpus (Wikipedia + BookCorpus) for a long time (1M update steps), and that's BERT.
Source : https://github.com/google-research/bert
- Read JSON files and creates samples with this structure:
{
qas_id: the question ID,
question_text: The Question,
doc_tokens: The Document,
start_position: Start position of the response inside the doc (-1 if impossible)
end_position: End position of the response inside the doc (-1 if impossible)
is_impossible: True or False
}
- Convert these previous samples to features in order to use them by BERT
Concatenate the question with the response passage
[CLS] after her second solo album , what other entertainment venture did beyonce explore ? [SEP] ( 2008 ) influenced her third album , i am . . . sasha fierce ( 2008 ) , which saw the birth of her alter - ego sasha fierce and earned a record - setting six grammy awards in 2010 , including song of the year for " single ladies ( [SEP]
Tokenize data
101 2044 2014 2117 3948 2201 1010 2054 2060 4024 6957 2106 20773 8849 1029 102 1006 2263 1007 5105 2014 2353 2201 1010 1045 2572 1012 1012 1012 14673 9205 1006 2263 1007 1010 2029 2387 1996 4182 1997 2014 11477 1011 13059 14673 9205 1998 3687 1037 2501 1011 4292 2416 8922 2982 1999 2230 1010 2164 2299 1997 1996 2095 2005 1000 2309 6456 1006 102
Mask the response passage in order to transform the SQUAD problem to IsNextSentence?
Reminder: BERT is trained to solve IsNextSentence problem.
input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
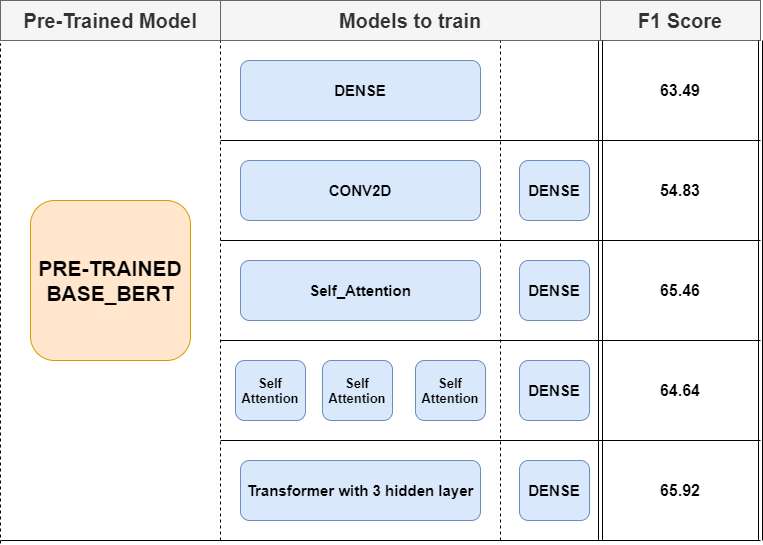
In order to solve the SQUAD V2 problem we decide to fine tune the pre-trained base_bert previously described and the main reason behind this choice is that we don’t have either time or resources to train such model. That’s why we also decide to work only with 45% of the dataset.