RFC: Separate versioning of data types #35
Comments
|
@pavel-kirienko I think I'm close to suggesting a complete system for versioning. This will be the foundation for accepting bit-compatible frames. Take a quick look before I remove the WIP tag (one of the upcoming days) and say if you see contradictions or unspecified behaviour. |
|
Currently, the specification states that the name of a namespace cannot begin with a digit. As such, If the above approach were adopted, it would provide us with an uber convenient way to specify the version of dependencies. Instead of this: ...we could write this: Having the version number encoded in the name has the following advantages over the current proposition:
The response structure of the service The limit could be set at 10 versions. I understand the value of semantic versioning in the context of software versioning, but it is not evident to me why is it required to have the explicit patch version in DSDL. The information conveyed by the patch version is equally accessible via version control systems. I propose to remove the patch version from the RFC and keep only those that affect the semantics and/or the binary layout of data types: major and minor. I think it is perfectly fine to make the version numbers mandatory from the start. That would promote good data type design practices and make the default data type set more consistent. In order to switch to the forced versioning, we would have to go over the existing definitions and manually assign each one a version number, which would be trivial to do. Have you had a chance to work out how exactly different versions should be handled when receiving and emitting transfers? My take on this is that when receiving a transfer, the receiver would compute the data type signature for each known version of the data type until a match is found. Having found a match, the receiver should unmarshal the transfer and do either:
The first approach is the most convenient from the standpoint of the application designer; the second approach is the easiest to implement. When emitting a transfer, the library should select the newest version by default, but the application designer should have a way to specify the version manually. |
Good suggestion, I agree with the advantages from your list. I support this.
I'm not sure if I like it. My problems with it are:
I ended up writing this up a bit different from the original suggestion we talked about. First of all, I split up versioning and backward compatibility into two seperate RFC
Second of all I ended up suggesting something closer to your original proposal. This only requires using 1 signature. Check out #36 for full description.
After thinking about this I fully agree with you. Let's ditch the patch version.
A
Again, my proposal is a bit changed compared to what we were originally discussion. Check out #36 |
Why though. What do we gain by introducing this restriction? By adding it, we condemn ourselves to a far uglier, in my opinion, way of specifying the versions of dependencies. My point is that the restriction has costs.
I just went and re-read the proposition you referred to, and it doesn't seem to address the case when a new version of the data type is not backward compatible with the older one, so that multiple signatures per data type are needed. My proposition still holds. |
You say it's far uglier, I think it's nicer. It's (mostly) just a semantic thing, and both will probably work fine. If the concept of versioning is accepted we can discuss the semantics after?
#36 states "When the dsdl is compiled for a data type, it should always use the data type signature of the oldest compatible message. This is the version on the form We know that when a new incompatible data type is added the major version will be incremented (or minor if unstable). This means that the new data type is now the "oldest compatible" and its signature will be compiled from itself. The proposal is somewhere between my original proposal and your original proposal (from #4). To be more precise it's something like automating your original proposal by using versioning. Should I edit the issues to show the following things?
|
I fully support the proposed concept of versioning, so consider it accepted. Except for the thing below which still needs sorting out.
Complete removal of older definitions when adding a new major version partially defeats the purpose of the whole concept of versioning. Say, we made a new message v2.0, which new nodes can use. There will be older nodes which may continue using v1.x for an indefinite period of time. In order to guarantee compatibility with them, designers of newer applications will want to support both v1.x and v2.0. The current versioning system does not account for that. Therefore it should be possible to define more than one major version of any message type. That means that we're going to need more than one signature per data type. Does that make sense?
Absolutely. |
|
So I'm finally back at this. But it's been a long time. I'll sum up a few things so I know we are still on the same page. @pavel-kirienko shout out if there are unsettled questions or disagreements.
|
|
Seems sensible. Have you thought about the best way to carry the version information over the wire? How does a node know which version of DSDL to use to decode a given transfer? Two things come to mind, not sure if they make sense:
|
|
I've not yet been able to work out all the details around how we should ensure compatibility. I feel certain that we should have a notion of version and that this suggestion not will put us in a worse situation at the uavcan protocol level. What I'm currently thinking is that:
(compatible) frame sends a message to a node supporting an old (compatible) frame the extra fields I will start doing the groundwork with dsdl versioning, and we can discuss message compatibility together with the other protocol changes ("version bit, TAO and CRC changes) |
|
This comment is a bit hasty, I'm going to write up a more thought through proposal later. Consider this as a heads up for something we need to think about for the new version of the uavcan protocol. The reason for initializing the transfer CRC with the data type signature was to ensure that the received message was the exact same message as the one transmitted. As we're aiming to have a notion of compatiblity between messages this is perhaps not what we want anymore. By introducing versioning of messages, a message (with its version) will (should) be immutable once published. This makes it easier to reason about compatibility from the definitions, and should be easy enough to write a checker that enforces some of the properties. This may also make it more acceptable to not enforce compatbility as strictly as it has been for the new version of the protocol. What I'm thinking is instead of initializing the CRC with the normalized message (hashed) we instead initialize it with a structure containing:
@pavel-kirienko can you see anything that in principle won't work with this approach? cc: @thirtytwobits since you're currently working on supporting the new protocol version. |
|
OpenCyphal-Garage/uavcan.github.io#40 and OpenCyphal-Garage/uavcan.github.io#41 proposes how backwards compatibility can be ensured for the new protocol version. This proposal is a bit more "from the ground up" and doesn't feel as much as an afterthought as what we've discussed before. |
|
Here I want to admit that when facing difficult problems, my design workflow may involve a bit of mindless wandering around the campus. Can be quite enlightening. Thanks, Kjetil. It took me some time to rebuild the big picture in my head since I was engaging with completely different matters lately. I believe that part of the reasoning in this and related proposals are based on a false assumption (#35 (comment)):
Our experience indicates that this is an exceptionally rare circumstance. All of the changes that we implemented to the existing data type definitions so far ended up being backward-incompatible at the bit level. Another important idea to keep in mind is that even a bit-compatible change to a data type may still render the resulting definition semantically incompatible with the old definition. An example of that is provided in the current specification where two fields are swapped names (although this is not the only error mode where a semantic incompatibility can be introduced). This is why I don't think the idea to abandon the stricter DSDL signature we have now in favor of a semantic-invariant serialization signature you proposed is a viable one. An automatic way of ensuring semantic compatibility without the unnecessary restrictions of the existing DSDL signature logic is probably possible, but it would require some complex in-depth analysis of data types. I don't think the benefits of that worth the effort, at least not for v1.0. If there ever is a need for a human to squelch a false-positive DSDL incompatibility error, we could (as an easier alternative) consider resurrecting this old proposal: #4. I'm sorry that I failed to recognize this problem with your proposal earlier; as I said, I just got back to UAVCAN-related issues recently, so it was difficult to spot from outside. I suggest keeping only the major version number. As a side effect, this will also eliminate this ugly special case you mentioned earlier (#44 (comment)):
Then, as far as serialization/deserialization logic is concerned, different versions of a data type are to be treated as completely different data types, at least for now. Eventually, it would be quite interesting to explore the possibility of automatic data type promotion from older versions to the newer versions upon reception, but that would be a local node-specific change that doesn't need to reflect in the protocol specification whatsoever. Consider it a bit of syntax sugar for users of high-level libraries like libuavcan or uavcan.rs. A remaining issue, as I see it, is how do we convey the version information over the wire? In the case of CAN FD, I suggest to add a single byte per transfer, containing the version number of the encoded data type. The byte should be probably allocated either before the payload or after the padding bytes. It might be sensible to use only 6 of the 8 bits for the version number (assuming that 64 versions are enough for everybody?) and keep the two major bits reserved for future use. That will eliminate the need for the trial-and-error approach to decoding, and also alleviate the problem with single-frame transfers which do not carry any DSDL signature information (because they don't have CRC). The case of CAN 2.0 is trickier because the extremely limited amount of data per frame does not easily permit us just to throw away a whole byte. I expect CAN FD to completely displace CAN 2.0 eventually, so it might be sensible to view CAN 2.0 as a semi-deprecated transport that eventually is going to fall out of use. In that spirit, it might be acceptable to resort to the trial-and-error approach to decoding, starting with the newest available version and going to the older versions if the deserializer runs out of data, encounters too much data, or the CRC ends up being incorrect. Do you think I am thinking in the right direction? |
|
I've taken some time to think through all of this once more. I came to a different conclusion than what you did. Let's discuss.... First of all, we're really discussing two separate things here. One of them is whether minor version is a useful concept, and the other is whether populating a void field should be possible to do while being compatible with the former data type. I think the minor version have value even if we do not allow compatible population of void fields. I've split my reasoning up in two parts. Why we should have a minor versionStability guaranteesSince consts are not being included in the data type signature a change of a const value or name can break compatibility without changing the data type signature. This means that the data type signature is not enough on it self to argue for compatibility. This versioning proposal gives the complete toolbox required to reason about compatibility, if we follow some rules. One of these rules needs to be that a released version of a data type can never change without changing its version number. If this is not true, it would be possible to have incompatible definitions for the same version and that means that versioning doesn't make sense at all. This means that editing comments or adding consts can not be done without releasing a new version. If no minor version existed there would suddenly exist two incompatible versions that really should have been compatible (only differed by a const definition). Furthermore, if a const were to change in a way that was incompatible we could bump up the major version. This would express that semantic compatibility had been broken in a way that would not be possible if there existed no versioning, or every change bumped the major version. Experimentation before stabilizationAnother important part of this proposal is the ability to experiment with data types before stabilizing them. This requires a way to distinguish between stable versions and unstable versions. Even though versions with major version 0, like 0.1, also will be guaranteed immutable they will also convey information that we will not be reluctant to push new experimental versions. Once a 1.0 version is published the datatype should be tested and most faults should be fixed. This matches the observation that "compatible changes" are more rare than breaking changes. This do not imply that the few small changes are of little value, I see a lot of value in being able to reformulate comments, add consts and populate explicitly reserved void fields. This allow us to fix small details in hindsight. Only in the few cases where big mistakes were made, or the future makes the original data type obsolete a 2.0 version should be published. Some numbers
To gather some data on this, I went through all the commits in the DSDL repo and checked those named "Merge pull request...". I counted the number of changes to a datatype requiring a major or minor version based on bit layout or semantic differences. I found:
I think that these numbers alone makes it attractive to have a way to change things without breaking anything. But more importantly i believe looking at the current number of changes may be misleading for two reasons. The first on is simple, there will always be more big changes in the start. The second one is that when these changes were made there was no way of making any significant changes without breaking stuff (due to the restrictive nature of data type signature). Perhaps there was changes that would have been desirable to do but not important enough to justify breakage. Why we should initialize CRC with something that allow us to populate void fieldsThe current data type signature does not guarantee compatibility.The most important argument for not relaxing the signature used for initializing CRC is that it cannot be used a a proof for compatibility. However, the assumption that equal data type signatures guarantees compatibility is not correct as consts are not included in the data type signature. It would be easy to break semantic compatibility (while retaining the same data type signature) by changing the value of two error code consts. I believe this example is quite close to the example (from the previous comment) for field names. What we should do instead is to manually enforce some simple rules. One of those we currently have to follow is that const names are not to be swapped. It would be quite simple to follow the equivalent rule for field names when merging PRs. And with the dsdl linter/checker (mentioned below) this would be automated. The current compatibility checks only work for some types.A lot of the data types are being sent without any compatibility checking, either static or dynamic. And what data types are being checked corresponds to the arbitrary condition if it's a multi frame transfer. Single frame transfers are currently always being sent without any explicit checking. When using CAN-FD most of the transfers will fit in a single frame transfer and almost none of the transfers will have the data type signature verified. This means that by keeping a strict data type signature in the CRC we sacrifice a lot of flexibility to verify (allegedly in an overly strict way) compatibility for only a few of the data types. This also mean that we cannot rely on the current mechanisms for compatibility checks. This means in turn that we either have to add dynamic checking to single frame transfers or do more verification statically. The current compatibility checks hinder simple future proofingIf we want to be able to stabilize definitions without shooting ourself in the foot we are going to want as much flexibility in future proofing as possible. Reserving a field as a void and populating it at a later point is one of the most important ways to do this (together with adding consts at a later point). I do not think we gain enough safety by keeping the current strictness to justify this loss in future proofing capabilities. Writing the dsdl checker tool is not hard.The current rust uavcan parser works fine for all happy paths. But if you try to parse dsdl that are not adhering to specs, all bets are off. This was super to get things running, but not acceptable in the long run. Improving error handling in the parser is the only difficult thing about writing such dsdl linter. The good thing is that I know how to do it, and actually already did half the work last week. This was something that had to done anyway. Once the parser is up to speed, I consider writing the following checks trivial. This would also leave us in a better condition to detect compatibility between dsdl than with the current data type signature since it also works for consts and single frame transfers.
The capabilities of good error reporting is also useful when compiling custom dsdl for use with uavcan.rs. The work done with dsdl linting will with a reasonable amount or work benefit uavcan.rs and the uavcan ecosystem as a whole. If we decide that static checking is the way to go, I can have a couple of these lints up and running (on the old parser) in just a day or two. And have all of them, including the new parser up and running in about 2 weeks, this also leaves the required time to update uavcan.rs to the new protocol (a lot of this work is done). OtherConvey dsdl version number of the wire
I do not think we should include message definition version numbers over the wire every time the message is being sent. Remember that once the message definitions are stabilized they're only supposed to be broken in rare cases. And i do not think adding a byte to handle this is worth the overhead. In the rare cases they're broken we have the following mechanisms to handle this:
CAN 2.0 deprecation
I think this is overly optimistic. I think realistically CAN 2.0 is going to be around for a long time, and we should support it as best we can. I think we should to as little extent as possible differentiate between the transfer protocol. I think we also should be conservative with the CAN-FD data usage, even though its much cheaper than CAN 2.0 we should stay on the "as low overhead as possible" side. |
|
I'm both coming into this conversation very, very late and also trying to learn enough about UAVCAN to be a useful participant so please be gentle. CAN 2.0 deprecation2.0 isn't going anywhere anytime soon as FD is only just now (i.e. 2018) becoming available for large-scale production and with the massive existing deployments of this protocol it may not go away for decades if ever. While the UAV space is much less encumbered with legacy it borrows heavily from automotive (in civilian sectors) and is currently too small to support its own hardware ecosystem. Because of that we will inherent automotive's legacy and will continue to see 2.0 (and LIN) peripherals available in microprocessor lines that we otherwise find useful. Convey dsdl version number of the wireI'm definitely against a per-message versioning scheme. There just isn't enough bandwidth to handle this in 2.0 and it's even onerous in FD. I'd recommend an approach where the node allocation operation was expanded to also include a protocol level negotiation. For some safety-critical systems the node id server would want to decline to enable nodes that were not compatible with it. This could be used to ensure a system remained inactive unless/until all safety-critical nodes were found to be running a compatible version of the protocol. This doesn't help for systems that statically allocate node identifiers so this proposal requires more thought. I'll float it here and develop it more if the group thinks there's merit to a service-based approach. Writing the dsdl checker tool is not hard.Perhaps not but even it if were hard it is extremely valuable. I'm all for developing a tool suite that could analyze DSDL at compile-time and also be evolved into a static CAN network analyzer going forward. The current compatibility checks hinder simple future proofingSo @kjetilkjeka , my understanding is that the following is still your recommendation? :
|
What you're against is sending message version number over the wire for every transfer, right? I agree in beeing as low overhead as possible. And such, my proposal for seperate versioning of data types do not require any extra bandwidth except for when explcitly running the checking sequence. This will of course only be done as part of debugging/initialization.
Is your idea that this will check protocol versioning, datatype versioning or both? It might very well be a good idea to be able to do datatype compatibility checks in the ID allocator. Just remember that the protocol also have to work smoothly with static node IDs. And since uavcan gui tool is the official debugging tool i think it would make sense to enable this tool to do checks as a first priority.
Yes it is. More specifically my proposal is to init CRC with something that give us the flexibility to populate void fields at a later point. My proposal is that this should be one of the two following things depending on whether it's valuable to check serialization compatibility dynamically.
|
Yep.
What if we added a
For proprietary commercial systems, especially safety-critical systems, determining compatibility statically is ideal but it seems like the UAVCAN ecosystem has different requirements? Specifically, do we want to support the use-case where a new off-the-shelf part is integrated into an existing vehicle system? If so then dynamic compatibility seems like a hard requirement even if that means an initialization-time check rather than a per-message "runtime" check. |
|
I have taken some time to rethink the changes we are discussing starting from the core design goals. I have also taken some time to re-read relevant chapters of the CANopen specification documents to see if there are any pertinent ideas that can be borrowed for our benefit. In order to steer this conversation away from dead-end paths, let me say now that any design decisions that focus on bus masters, centralized activities of any kind, or stateful/context-dependent communication go directly against the core design principles of the protocol. As such, things like protocol version negotiation at the time of dynamic node ID allocation, or centralized data type compatibility checking are not going to happen. In particular, the dynamic node ID allocation feature was developed to accommodate two rather specific use cases - in-field on-vehicle node firmware updates and a plug-and-play capability for simplified design and development workflows. It was understood from the day one that this feature is poorly aligned with the rest of the protocol; I have taken steps to rectify this misalignment by making the dynamic node ID allocation feature decentralized from the start (it is based on a distributed consensus algorithm that allows the network to continue functioning even in the event of a single or dual allocator failure or in the event of undetected network partitioning). Compared to the rest of the specification, the dynamic node ID allocation feature stands out not only due to its centralized nature but also due to its hideous complexity and poor predictability. It is a mistake to think that safety-critical applications mentioned earlier in this discussion are likely to leverage that feature; to the contrary, using existing vehicle networks as a reference, it can be observed that safety-concerned systems tend to avoid variable parameters. The reason why statefulness and context-dependency I mentioned above are evil and are to be avoided is that they introduce significant complexity and make node behaviors harder to design, validate, and predict. Each independent interaction between agents shall have as few dependencies on the past states as possible. This simplifies the analysis, makes the overall system more robust, and makes it tolerant to a sudden loss of state (e.g., unexpected restart/reconnection of a node). Additionally, in a decentralized setting, maintenance of a synchronized shared state information can be a severe challenge. Decentralization by itself is extremely important as it allows the network to implement complex behaviors while avoiding excessive concentration of decision-making logic in a single node, thus contributing to overall robustness and ease of system analysis. The above should be sufficient motivation for complete avoidance of network initialization procedures of any kind. There will be no mandatory data types besides the already existing In regards to the CAN 2.0 deprecation: as I see it, yes, it is going away. This is according to CiA publications and also according to our encounters with CiA on social networks (how did it come to this?). There are CAN FD enabled MCUs on the market from all major chip vendors: Microchip, STM, NXP, Intel/Altera, etc. Thankfully, the unmanned vehicle and robotic fields that we are at the moment catering to are mostly unencumbered with legacy CAN hardware, so I expect CAN FD to take off in this specific field much faster than in the automotive segments. This is why we should be focused on CAN FD in the first order - because this is the future. Having sorted out the basic ideas, let's switch back to the problem-solving side of the discussion. For now, let's pretend that CAN 2.0 doesn't exist - we are going to get back to it later. Following the requirement of context-free communication, every data transfer should carry sufficient information for its interpretation by receiving nodes. With the introduction of data type versioning, the only way of adhering to that requirement that I can see is to include the version information in the payload, as I suggested earlier, sacrificing one byte per transfer. I am open to new propositions, but I don't think there can be other ways of doing this. Limiting the number of major version numbers to a reasonable value like 24 should leave 4 bits free for future use (version numbers ≥24 can wrap around, we probably don't want to keep more than that many older versions at the same time). On the subject of the minor version number:
There was some misunderstanding concerning my proposition to abandon the minor version number; allow me to explain it in a more detailed way. Bit-compatible changes are rare; however, Kjetil is right to point out that there is a selection bias involved: having no way of introducing bit-compatible changes without breaking backward compatibility, we introduce no such changes. The empirical evidence we have might have been different if it were possible to implement simple changes in a backward-compatible way. My proposition is to keep the same major version number as long as the bit-level compatibility and semantic compatibility are not affected; when a bit-incompatible change or a semantically-incompatible change is introduced, the major version number should be increased. When a new major version is published, it is added alongside older major versions of this data type. Eventually, older versions may be removed in order to force their deprecation; this should be done with great care as not to break rarely-updated legacy nodes. I see no practical benefits in releasing a new minor version whenever a small change (like comment changes) is introduced. There are source version control systems in place like git which solve this problem already; doing the same thing at the protocol level is unnecessary. Likewise, adding/removing consts can never affect the binary compatibility; however, semantic compatibility can be compromised. Therefore, shall the semantic compatibility be not altered, const modifications can be done directly within the same version number; otherwise, a new major version will have to be released. This seems to pretty much repeat Kjetil's proposition, so we seem to be aligned here. It makes sense to add special treatment rules for the major version of zero as Kjetil suggested: in this case, within the framework of my proposition, a zero-versioned data type can be changed in a completely arbitrary way without any regard for compatibility. I support the idea of writing a static compatibility checking tool as Kjetil described; it can be used to ensure that no bit-incompatible changes are introduced within the same major version (detecting semantic compatibility violations is going to be much harder). The following diagnostics suggested by him do not make sense with my approach to versioning:
Published definitions are allowed to change as long as the changes are bit- and semantically-compatible.
Constant/field names should be allowed to change. It may or may not break semantic compatibility; in order to detect that, the tool must be able to reason at a level similar to that of us humans. Doesn't sound like something one can code overnight (I wonder if cognitive computing services like Watson can be of any help here).
Again, this may or may not break semantic compatibility. It might be better to downgrade these diagnostics to Warning in order to let humans decide whether the new definition is semantically compatible or not. Now let's switch to DSDL signatures. In the beginning, I said that I spent some time rethinking the design from the core principles and reading up on other protocols. Consider the following data points:
The above considerations induce me to suggest a radical new idea: let's untangle the transport CRC from the data type compatibility problem completely. The transfer CRC will be exclusively a transport-level feature with no side relations. UAVCAN v1.0 could well be released without any sort of dynamic compatibility checking whatsoever. In the future, it would be possible to add some dynamic compatibility check using a short four-bit hash allocated in the four reserved bits of the data type version byte. The advantage of this approach is that it provides compatibility checking for all transfers (not only multiframe) and it is free from leaky abstractions. None of the suggestions made above are to be considered final. Please let me know what you think. |
What if we did enable the 4-bit hash as an FD-only feature? |
|
I will try to address the issues brought up by @pavel-kirienko seperately, the second section will also address @thirtytwobits comment. Stateless (context free protocol).Agree on every point! But i do not agree that the following things go against this:
Oh well, the next section proposes a better(?) solution anyway. Conveying version info over the wire.I understand the desire of being explicit very well. Being able to detect incompatible messages would be a totally awesome feature to have in uavcan. But I'm not sure it's worth the extra overhead of 1 byte for every message. I might have a solution where we can eat our cake and have it too. The proposalWe've already split between multi-frame and single-frame transfers in regards to several things before. We will continue to do so for this proposal. The motivation for doing this is that multi-frame and single-frame transfers have different needs in terms of efficiency and robustness. More specifically there is a lot more things that may go wrong with a multi frame transfer, being able to check these things is essential. Both since single-frame transfers are shorter (less payload/overhead ratio) and there are more of them (with CAN-FD almost every frame is a single frame transfer) efficiency is essential in these kinds of frames. This is of course the same reasoning that motivated CRC for multi frame transfers only in the first place. Single frame transfersThis proposal is made under the assumption that single frame transfers do not need a Transfer ID or toggle bit. If this is not correct, there are still ways to achieve the same effect (for instance by using no toggle and shorter transfer ID). It is based around giving a different meaning to the tail byte depending on the SOT and EOT bits. If both SOT == true and EOT == true then the tail byte will be decoded as this.
where reserved will be sent as 0 (compatible with previous made toggle in single frame transfers) and mv will be a bit in the major version number (mod 16 hash) Multi frame transfersThis is the place where the extra overhead is worth it. We keep tail byte exactly as it was and add a End-of-multi-frame-transfer-byte (we need to come up with a better name though). This byte will be placed directly before the tail byte of a frame where SOT == false and EOT == true. It will not go into CRC. The byte will encoded as (much like Pavel suggested in the previous comment) this.
where reserved will be sent as 0 (compatible with reserved bits for single frame transfers in case some of them wants to be used the same way) and mv will be a bit in the major version number (mod 16 hash)
I think this is an excellent idea, and since we now have major version information to detect incompatibilities we are free to do it. Let's go for it! Only using versions for FD frames
I generally think we should try to keep as much consistency between CAN 2.0B and CAN-FD frames as possible. I also think we should be as careful to bloat CAN-FD frames as we are with CAN2.0B frames. I therefore think that if it makes sense to make the same decision for both types of frames. Minor versions and dsdl checks.I'm still absolutely certain that immutable definitions and minor versions are the way to go. I've prioritized thinking about statelessness and conveying version info over the wire the last days. Please give me a bit more time to do a writeup of the minor version and dsdl checks. |
|
Edit: This would of course not work. Please discard it. Perhaps it would be better to always keep the tail byte as:
The new "end of multi frame transfer byte" would be:
Or if we wanted to use the reserved bits to increase the robustness of toggle/tid we could extend toggle to a wrapping sequence number and/or extend TID bitlength:
We would still have 2 bits in the tail-byte reserved for future use. Edit: This would of course not work. Please discard it. |
|
Perhaps this alternate scheme (growing from right) is more inntuitive? (just speculations)
|
Agree. But as these parts are to be optional, the protocol must be able to function without them. Interfaces for deep node inspections should be discussed separately later; right now I suggest to stay focused on the core functionality.
The toggle bit is indeed not needed for single-frame transfers, but the transfer ID field is required for all types of transfers, and I don't think we can safely reduce its dynamic range because that would affect the transfer reception logic, automatic redundant interface switching logic, and make the protocol prone to failing to detect a transfer ID wraparound. The decision to use just 5 bits for the transfer ID wasn't an easy one, going any further would be a mistake. That pretty much means that the format of the tail byte cannot be changed much at this point (unless there is some clever use for the Toggle bit for single-frame transfers, but I don't think there is). Speaking of the toggle bit, I've been meaning to suggest using it as a protocol version 1.0 detection bit. As you have pointed out earlier, right now it's fixed at 0 when SOT=1; I propose to flip it to 1 when SOT=1 (and invert the subsequent toggle pattern for multi-frame transfers) in UAVCAN v1.0 in order to provide a clear and simple way for newer nodes to detect when they are dealing with pre-v1.0 nodes on the bus. Consider it a tentative feature for the transitory phase until all of the fielded hardware has converged to UAVCAN v1.0. We can't start using the proper version bit reserved in the CAN ID field because it is still being used as a part of the priority field by the existing nodes.
Okay, that would be helpful. While working on the elaboration, please also consider this: imagine that there are several minor versions of a certain data type with the same major version. Suppose a node which has access to these definitions received a transfer with the matching major version. Which minor version should the node use to decode the transfer? Always the highest available minor version? Which minor version should it use when encoding? As in the case of receiving, always the highest available version? That approach (always pick the newest with the same major version) seems intuitive and makes sense (because they are all bit compatible and semantically compatible by virtue of sharing the same major version), but doesn't it defeat the purpose of having the minor version? Perhaps I'm missing something. Once we've reached some consensus about the minor version and the version reporting, it will be time to talk about CAN 2.0. |
|
Pavel, i really like your last proposal. I feel both avoiding the extra byte with overhead while keeping the protocol very simple is very in line with the problems we try to solve. And the improvements to how priority is set can make systems using the protocol both more reliable and efficient than what they could before. Here are some comments. Changing the header without adding a version bit means that there is no trivial way to put nodes with different protocols on the same network. I'm on board with this. If you want to retain the possibility of doing some non-trivial compatibility checking that will not be part of the core spec, I think it's totally fine to change the initial value of the toggle bit. I'm also totaly fine with keeping the old toggle scheme for simplicity. I really think 2 version bits is enough. The turnover time for versions should be long enough that this is not a problem. Most messages will hopefully not reach a version 4 ever. I'm really happy with making everything more predictable in regards to services/messages. Ensuring a predictable I totally agree to the placement of the type version bits. It is not possible to determine wether old or new versions should "always" have higher priority so making it "undetermined" is fine. If this is important it is possible to override with the priority field. Making it count the least for arbitration priority is also the right choice. The only thing I'm not that crazy about is the 4 priority bits for messages. For me, the most intuitive solution would be to use your first scheme but extend Message type ID to include the I think that first and foremost priority should be based on request/reponse + ID, and the priority field is a way to override these defaults. I wonder if more predictibility in regards to message/service and chosing ID's wisely can render 3 bits enough for both service frames and message frames. It would be interesting to see what cases priority bits are currently used and if these changes (and other things like swapping source node with destination node in services) can be used to relieve the need for an extra priority bit. I will think some more about all this, but all in all I'm very happy with this proposal and really think it's the right direction to move in. |
I think we can easily agree on the following middle ground then. The reserved bit should be set to 1 when emitting and ignored when receiving. We will be able to repurpose it later, perhaps in UAVCAN v1.1, in a mostly backward-compatible way with an easy migration path.
Is it not the perfect time to talk about anonymous frames?
The reserved area can be reused later for the upper bits of the message type ID, shall such need arise. |


|
I'm on board with your last proposal (including anonymous frames). Since ID range 20_000.. was reserved for future use i assume there will be no need to change any default IDs. Just a last nit that i briefly mentioned in the last comment as well. For messages, if priority and message type ID is the same the arbitration will be decided by the source node ID. If we swap the dst node ID and src node ID fields in the service frame header this behaviour will be consistent between message frames and service frames. I believe this predictibility in prioritization is worth more than having the source node field on the same bit pattern for all transfer types. I'm also OK with keeping it as is if you have strong feelings towards that. |
Just swapping src and dst doesn't make a lot of sense, since they switch roles between request and response transfers, but I see what you mean. If we were to pursue maximum determinism, we should do this:
The service initiator (the client) should dictate the priority of the transfers it initiates. As such, the client node ID should go first, meaning that the source and destination fields should swap places depending on the state of the request-not-response bit. The question is, do we want to add this extra bit of complexity for the sake of a minor improvement in determinism? |

|
I think much of the akwardness comes from using src/dst terminology. If we instead use the phrasing server/client (or server/requester), we will end up with coherency between request and response. We also end up not breaking coherency between messages and services, as messages is concerned with a "sender" while services are concerned with "client/servers". This also has the added benefit of response-ids being completely equal to request ID except for the one relevant bit (bit 24). This is a nice feature both for keeping priorities deterministic and if someone were to manually look at IDs. With that said, I do not think it's much extra complexity. It may even be more intuitive with the changes. I think it's at least just as easy to internatlize the scheme based on client/server as src/dst. Nothing to crucial, but i think the protocol would overall be a small bit better with these changes. Off topic: What sw do you use to create the figures? |
|
The latest changes bring us to the following:
Google Sheets. |

|
I have an objection, however. Fixing client/server ID instead of source/destination ID makes hardware filtering harder, because the bit offset of the destination address becomes variable. For example, the following simple snippet (from Kocherga) would no longer work, requiring at least two hardware acceptance filters for the same task: // Accept only correctly addressed service requests and responses
// We don't need message transfers anymore
IUAVCANPlatform::CANAcceptanceFilterConfig filt;
filt.id = 0b00000000000000000000010000000UL |
std::uint32_t(confirmed_local_node_id_ << 8U) | CANARD_CAN_FRAME_EFF;
filt.mask = 0b00000000000000111111110000000UL |
CANARD_CAN_FRAME_EFF | CANARD_CAN_FRAME_RTR | CANARD_CAN_FRAME_ERR; |
|
Your objection is valid. I agree that we want to support services on units with very limited amount of hardware filters. The predictability still holds for messages, which is the prefered way of communication for everything with RT demands anyway. I agree that HW filtering is a valid reason for keeping it dst/src, and I'm on board with this decision. Let's leave this discussion for a couple of days giving @thirtytwobits and others following it a chance to raise concerns. I created OpenCyphal/specification#2 to keep track of "whats next". I think we should try to complete the list and then find out what we need to discuss next. |
|
sigh, this is a very big change from v0 indeed. Let me mull this over. |
|
I've sort of lost track of what this issue was about in the long list of comments. I had thought we were concerned with versioning the protocol (i.e. the UAVCAN layers on top of CAN but below the presentation layer). For that I expected we might allow for a single future change that would itself have to account for a future change (in a similar manner to CAN's r0 bit and the new reserved bit added in FD after it changed r0 to FDF). This is where I thought we were going with bit 24. The proposal we're discussing now (and, indeed, the proper title of this issue => RTFT, me!) is the versioning of datatypes. I think the latest proposal is trying to solve this at the Data Link layer when the solution should be found up at the presentation layer or even at the application layer. Let me make a counter proposal:
Learning from the early mistakes of IPv4 subnets let's avoid overdefining the CAN identifer and instead leave more room to allow the higher layers more flexability in defining how to version their types.
Remember that some people will be interested in using UAVCAN's core specification while ignoring the vehicle specific types altogether. Let's not reduce the flexibility of the core technology to support a scheme that some users will not be interested in employing. |

Maintaining total separation between layers is challenging with CAN because the CAN ID arbitration rules affect the highest levels of abstraction. I agree that it is tempting to decouple the typing logic from the transport, but maybe CAN is not the best-suited protocol for rigorous layering?
Versioning is useless unless it is supported by the transport. We have to come up with a tenable solution now, before freezing the CAN ID for v1.0. Losing the ability to version the protocol with a reserved bit is bad news, but not a disaster since there will be other (although seemingly less straightforward) ways of version identification, such as using the toggle bit. We are going to use the toggle bit approach to migrate from v0 to v1; likewise, it can be used to mark the migration from v1 to v2 (breaking compatibility with rogue v0 nodes should not concern us at that point). |
Yes this was the original thought. I'm also very sad that we were not able to put a version bit in the header. This makes the protocol a lot less "future proof" but we're currently trying to put a lot of (in my opinion) important features into a very tight pack.
I do not think we have the luxury of doing so completely. I think the following three reasons to tightly pack the can header outweighs the flexibility argument. One of the problems (and the benefits) of using CAN as a transfer protocol is that hw filters works on the can header. This means, that if we want to be able to stay compatible for resource constrained devices, we must give priority to things that are convenient to filter on inside the can header. The next reason is that the header is used for priority. Can is deterministic in what messages that will be sent in what order. To make uavcan deterministic as well, we need to put the relevant stuff inside the can header. We already use a 29 bits header. I think it's not responsible in regards to overhead to put extra header bytes in the data part of can if we can do without. When working with can, it's very common to be conscious and responsible with the utilization of the can bus. This is both to keep transfer times (in practice queuing delays) low, and that can is a very limited resource. If uavcan would not do the same, I think it would quickly lose attractiveness from systems where this was a priority. I do not think that this tightly packed can header is fundamentally incompatible with layering. If one wants to split uavcan into layers one would have to do so for both the data part and the header part. For the header part, one could say that Message type ID, priority and type version can be regarded as "defined at a higher abstraction layer". And only service/message response/request and node IDs are defined on the the lowest level. (Priority must in fact be an application level convention as it's relative to all other nodes on the network and can only truly make sense compared to these).
Will these people use messages, services and dsdl? If so, all parts of the header should be relevant. If they do not wish to use dsdl then they would be free to use message iD and data type version freely for something else.
Like i said in your "profiles" proposal, I think it's an excellent idea to be able to use only the convinient parts of the message definitions. And i also think it's a good idea to provide full flexibility in using custom definitions. I think that custom data type designers should follow the same "good practice" as the core data types follow. If they do they will get the static checking tool for free. They are also always free to put the major version to 0 and allow the minor version to grow. Then they will be in the "rapid prototype mode" and escape all safety checks. Why do you assume that custom data types should be handled any different than the core ones? |
|
Should we discuss the possibility to sacrifice one service type ID bit (and using a reserved bit in the message headers) to keep the protocol version bit? This would not be compatible with the old protocol but make everything more future proof. My suggestion would then to use bit 0 for protocol version. And skew all relevant bits one to the left from Pavel's proposal. |
I don't but there may be different type versioning schemes in use by the designers of custom types that aren't compatible with the type versioning scheme used by the core UAVCAN types. |
I like using a high bit but defining it recessive. This says "we expect to know better in the future and that future should be more important" (a bit of philosophical engineering perhaps?) |
|
Perhaps I'm just arguing semantics. Try this proposal:
Details:
|

|
So I squinted some more at my bit layout diagrams and decided that wasting a whole bit just for the sake of future proofness would not be a wise decision. Because of the protocol version bit we end up losing one bit either from the service type ID field or from the priority field, neither of which I find acceptable. Looking at the way other protocols evolve, UAVCAN v2.0 might end up being different enough from v1.0 to render our forward compatibility efforts futile. Also keep in mind that we still get to keep the toggle bit trick for less drastic protocol upgrades.
I think it's just the question of wording. We'll see what's the best way to define that in the specification. My suggestion is to stick to an earlier proposition without the version bit. Allow me to provide it here once more for extra clarity:
There is a glorious Estonian joke about a dead cow on a roadside which is highly pertinent to the current discussion. Do you happen to know that one? |
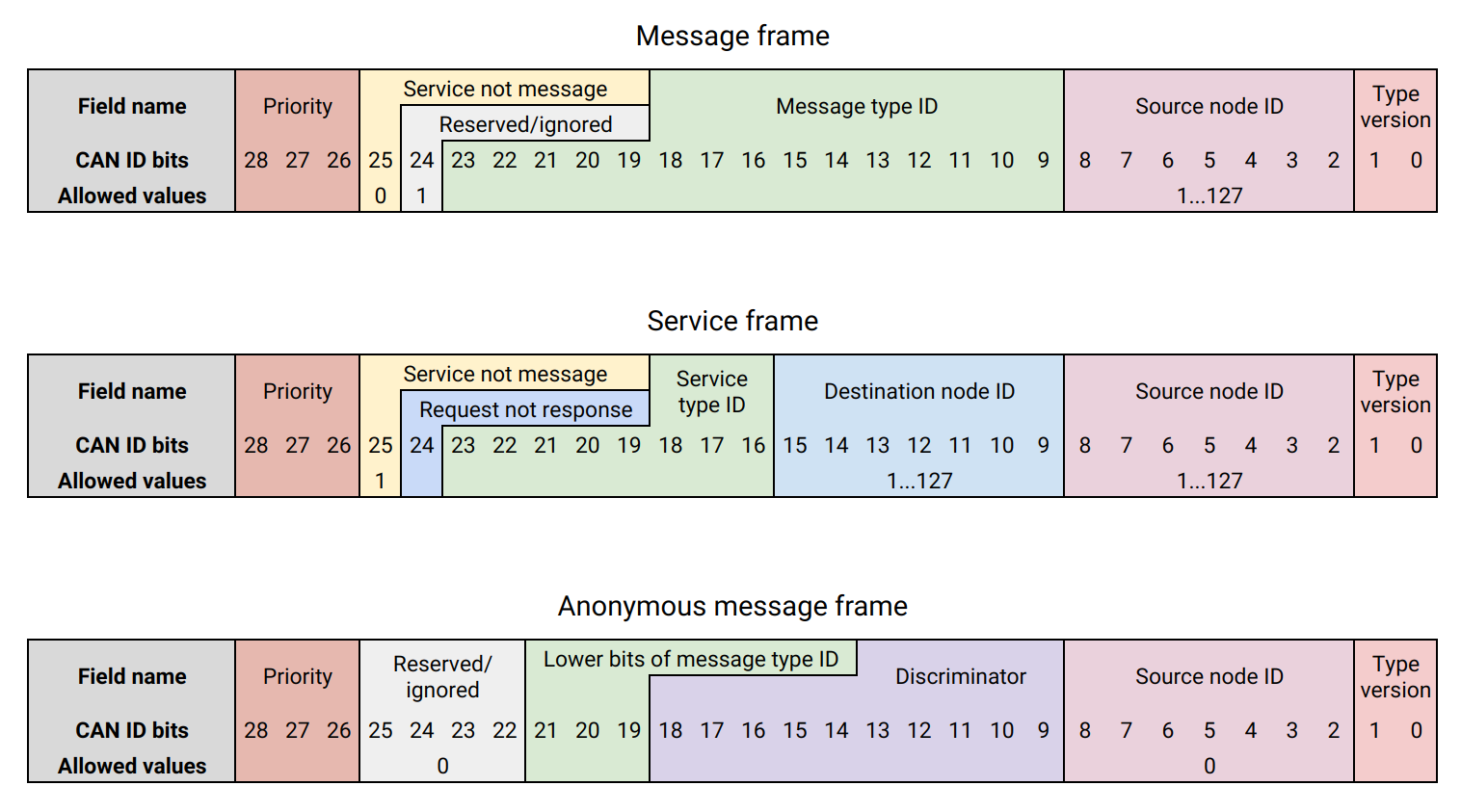
|
If we settle this discussion we're going to be able to cross of the last items concerning the core protocol in OpenCyphal/specification#2 which will unblock a lot of things in the reference implementations. This means that we should strive to move the discussion further or reach a decision. I'm happy with either of the two last ID layouts. Perhaps somewhat more with Pavels alternative due to the uncertainty of profitability around the version bit and the certainty of profitability around the 8 bit service type ID. I really just want to bikeshed a bit around bit 24. In Pavels last proposal we're not using bit 24 for anything. Since we're not going to be able to use it for protocol version later (as it won't work with service frames) and I don't see what specific to message frames we would want to use it for. Wouldn't it be better to just keep the 16 bit message type ID but reserve the ID space (same as before) or are there any special reasons why you want to reserve it as a |
This is a valid argument and I did just that in the current spec draft:
Absolutely. I don't expect anybody else to read through all of this thread at this point, so there's only three of us; let's finalize the decisions we made here and close the ticket: |

|
Thanks @kjetilkjeka , I meant to make a similar comment but forgot and lost track of our most favorite bit! I like where we're at except that I still don't like that the standard requires bit 1 and 0 to be used for data type versioning. I'd like to have the flexibility to use these bits to increase the message identifier space for custom messages if a versioning scheme wasn't required. I guess what I'm missing is how the transport layer would consume these two bits as version? Would this not be something that is up to the application layer to handle? I agree we should use them for versioning the standard datatypes but don't agree that we should require/enforce their use as versioning for all datatypes. That all said, I can agree to disagree on this point if we cannot come to consensus. P.S. We should paint the shed green. Definitely green with, perhaps, a touch of blue? |
The two bits are communicated to the serialization/deserialization layer to let it decide which data type definition version to use. It is outlined in the section 3.6.4.3 of the current draft:
I don't think this is a solid idea. We should strive to reduce the amount of implementation-specific behaviors and other variances for the sake of simplicity and unification. Therefore, if we decided to keep the version bits as they are now, they will be kept regardless of the application at hand. Besides, are you really sure your application won't require data type versioning in the long run? Sounds like a tough prediction to make. P.S. I respectfully disagree, it is well known that red is the best color |

|
I've crossed out my ticky box, as all my big concerns are essentially answered for in this solution.
Using DSDL should be our 1st priority, but if we can do this without losing anything we probably should. What about calling it "data type id lower bits (DSDL data type version)" and first say that this field is for the message type arbitration for the "representation layer" and then concertize how it's used in DSDL? |
I don't fully grasp yet what is the best way to reflect that in the specification. Adding an extra bit of indirection doesn't seem to contribute to clarity. The specification is flexible, we can change its wording and formulations later while keeping its implementations fully compatible. Meaning that if there is a need to decouple the lower bits from versioning, it can be done in v1.1 rather than in v2.0. |
|
Okay. As long as we paint it blue I'm in. I'll back away with this one nit-pick: Should we require reserved bits to be recessive? I know the standard prefers dominant reserved bits but for bits in the identifier, if we always have the reserved (i.e. older) version dominant then these bits will always be higher priority then any new uses. It seems like we would want the newer versions to be higher priority. Again, a real nit-pick since these aren't priority bits in the specification and we're looking into the future here which is always dangerous. Either way I'm good. |
|
I proposed zero because I expect that in the future we may want to re-use them for upper bits of the message data type ID. In that case, nodes that leverage an older version of the protocol will be implicitly compatible with the newer protocol by setting the higher bits always to zero. The fact that zero=dominant is a side effect here that has no practical purpose. |
|
🎉 |
Summary
Instead of talking about DSDL versions and stabilization of DSDL as a whole, this RFC suggests the alternative of versioning data types individually. This will ease the task of stabilization, allowing it to happen sooner, giving a more flexible way to describe compatibility between DSDL, and enabling a way to accept bit compatible data types without freezing data type signatures [#4]. Some robustness is also gained by having ways to check if single frame data types have conflicting definitions.
Motivation
There is an obvious need to stabilize DSDL. Every time a message is changed every software depending on it breaks. There is also a need to not prematurely stabilize. Being stuck with badly functioning data types will be the consequence, and it won't be fixable until next major version.
With the current system (waiting for dsdl 1.0) no stabilization is realistically within reach. For every battle proven data type, there is a data type that is not yet ready as well. By keeping on adding data types when it is convenient a dsdl stabilization is further pushed in the future as well.
By accepting separate versioning of data types, these problems should be much easier to handle. The proven parts of dsdl can be stabilized while allowing rapid development of the non-stabilized parts. This also allows software that only relies on stable messages to be stabilized, this is a huge advantage for uavcan users.
The data type signatures are really great! They let you know when you're using the same data types, and even enforce this programmatically for multi frames. The problem is that when you do have a miss match, it's not trivial to find out which unit is erroneous. Separate versioning of data types give us tools to talk about the version of the messages. For instance, if a unit (outside our control) states that it sends 0.2 frames and we know that we currently accept 0.3 frames, we will be much closer to fix the problem. It will also make it possible to (non-automatically) detect different single frame transfers, this would not otherwise be noticed as no CRC is used.
There are a lot of things that can go wrong when stabilizing DSDL. By stabilizing one data type at a time we make eventual "screw ups" less possible and more handleable. By combining this with using gained knowledge from previous stabilizations to stabilize new data types, stabilization should have a much lower chance of causing headaches.
Explanation
The approach to versioning is based upon the proven idea of semantic versioning but adapted to make sense for dsdl. The version information is encoded directly in the name of the file where the definition is contained such as
<ID>.<Name>.<Major version>.<Minor version>.uavcan. For example341.NodeStatus.1.0.uavcanExamples
Let's use the following frame as an example
If we were to add a comment we would have to increment the minor version (this doesn't change data type signature nor bit compatibility)
In the same way, adding constants would only require an increment of the minor version
But removing/changing a constant would require a major version (since it breaks backward compatibility)
Changing the name of fields or constants would not retain code compatibility and will also require a major version increment.
Removing/editing a comment will both keep data type signature and code compatibility, thus only requiring minor version increment
Using new fields in a bit compatible way or changing the name of void fields only require a minor version update.
Implementation
This feature should be regarded as a low impact feature. The feature itself will not change the generated code. Meaning that by treating files without version as 0.0 (and forbidding explicit version 0.0) this change will be fully backward compatible. This means that for example
341.NotStatus.uavcan"really" means341.NodeStatus.0.0.uavcan, while explicitly writing341.NodeStatus.0.0.uavcanwill result in an error.Open questions
How do we handle versioning of data types that uses other data types?
In some way or another we will have to specify the exact version the data type is dependent on. One way to do this would be as following
Another alternative would be
The following rules must be adopted
Further work
The text was updated successfully, but these errors were encountered: