F-Eval is a bilingual evaluation benchmark to evaluate the fundamental abilities, including expression, commonsense and logic. It consists of 2211 instances in both English and Chinese. Please visit our paper for more details.
The code of F-Eval will be released in the later version of OpenCompass 2.0. This repo only contains the dataset, the backend and the postprocess code of F-Eval.
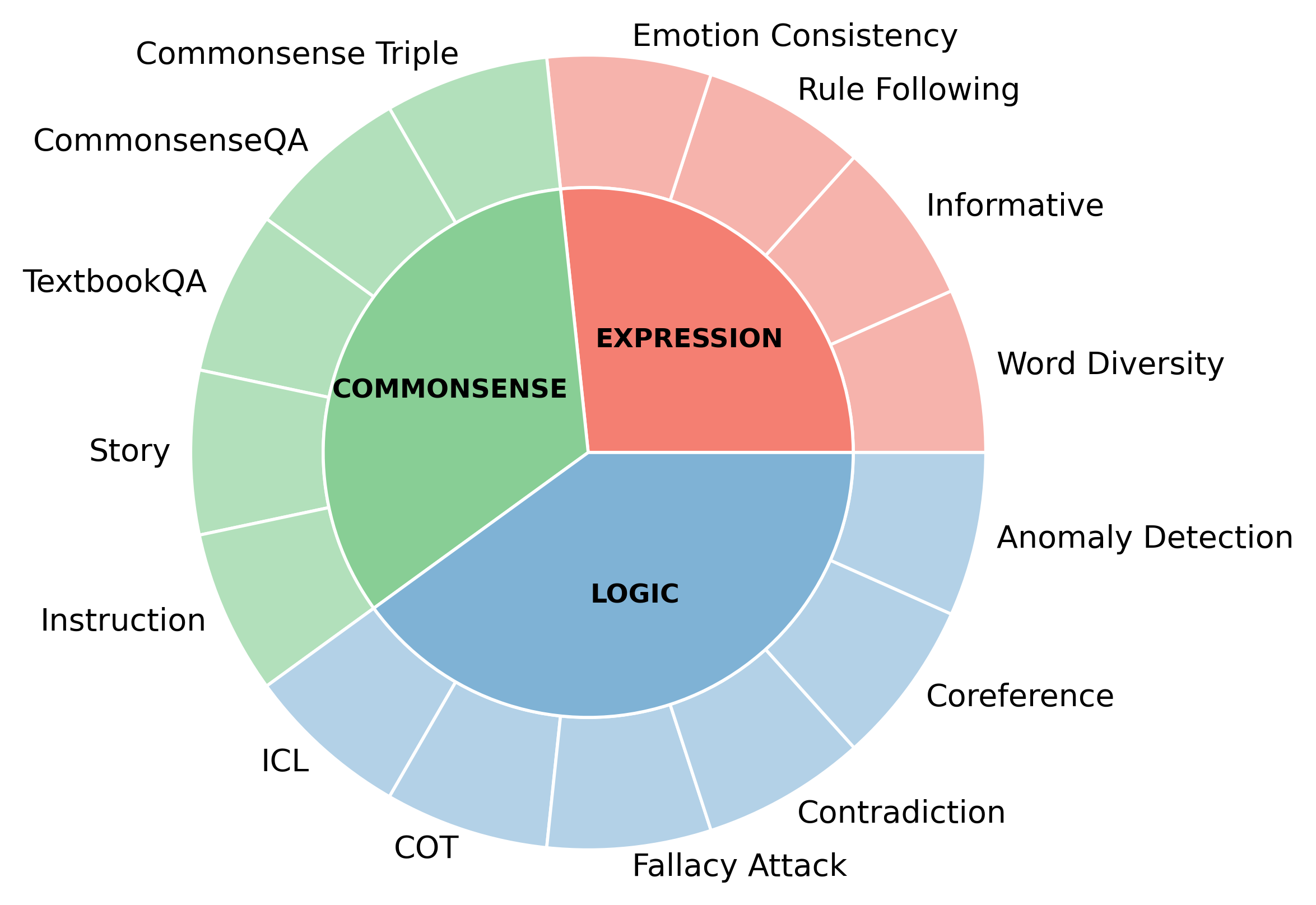
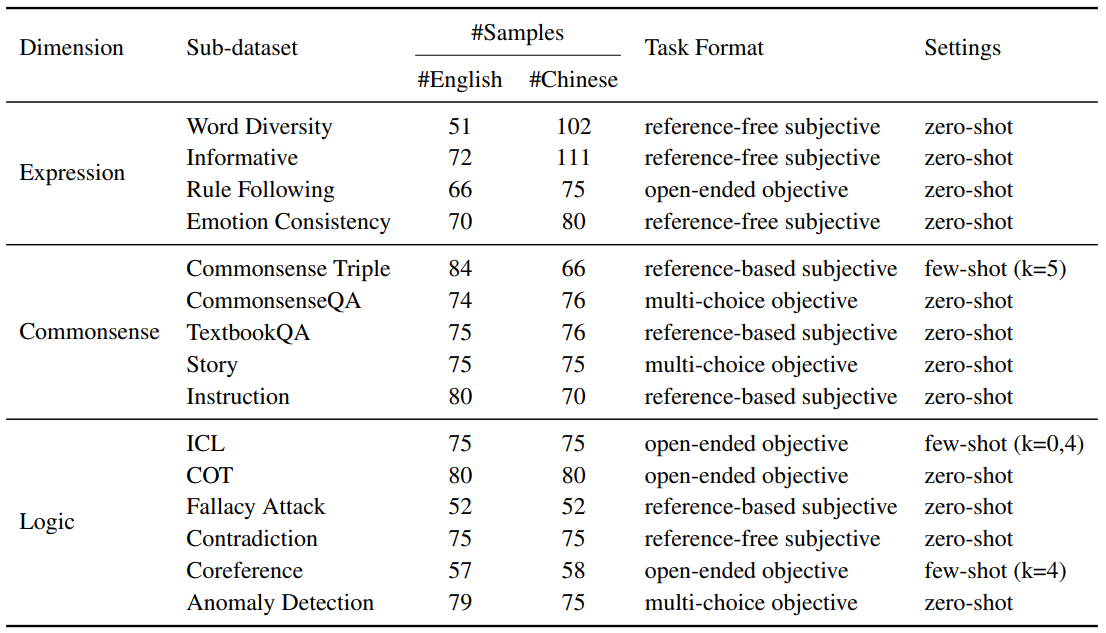
The statistics of the datasets.
An example of the rule-following dataset.
Prompt: last chance,last minute,last name,last laugh,last resort
Output: last word,last straw,last minute
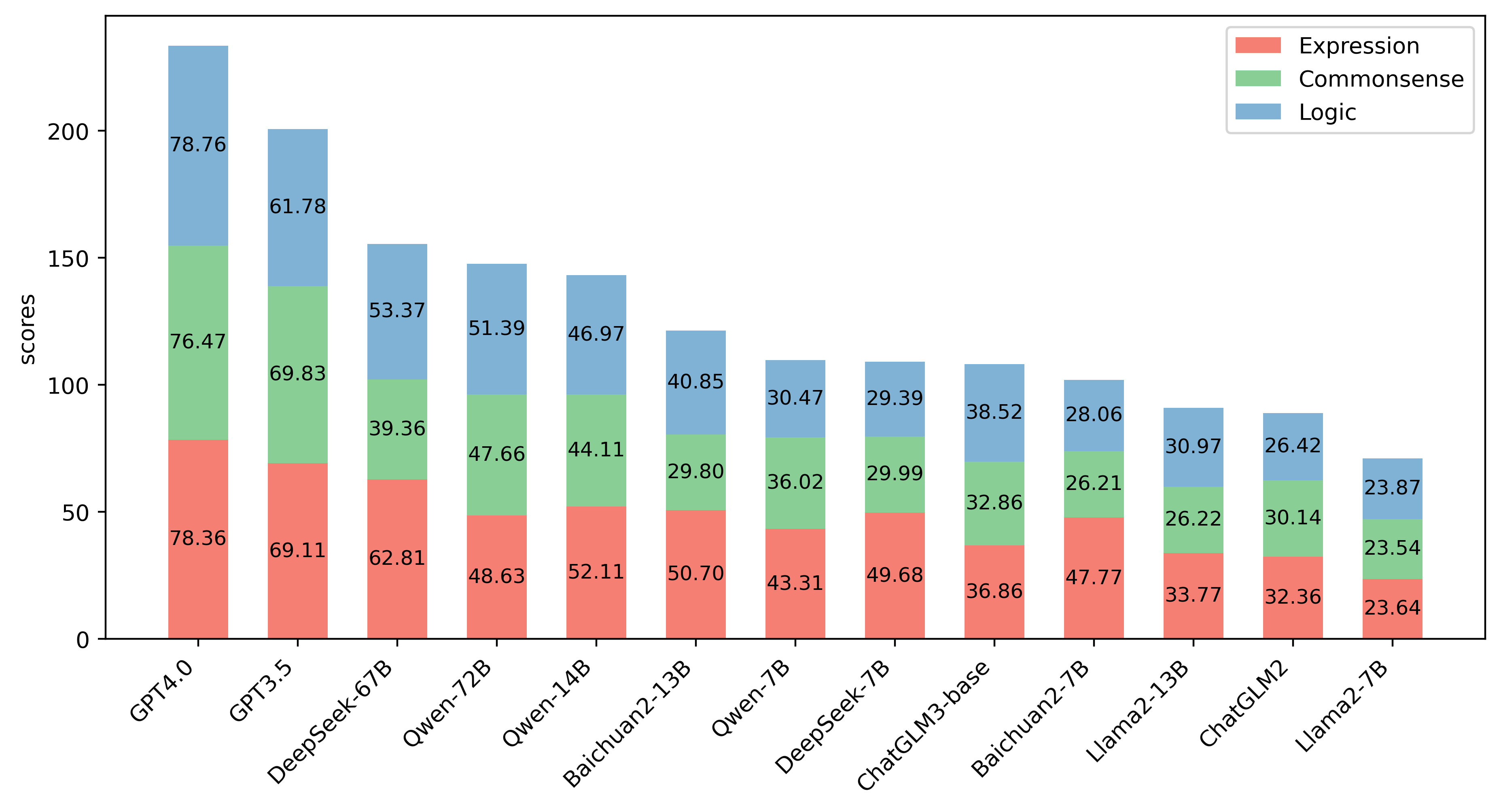
Below are the overall results of F-Eval across three dimensions. More details of the results in each sub-dataset can be found in our paper.
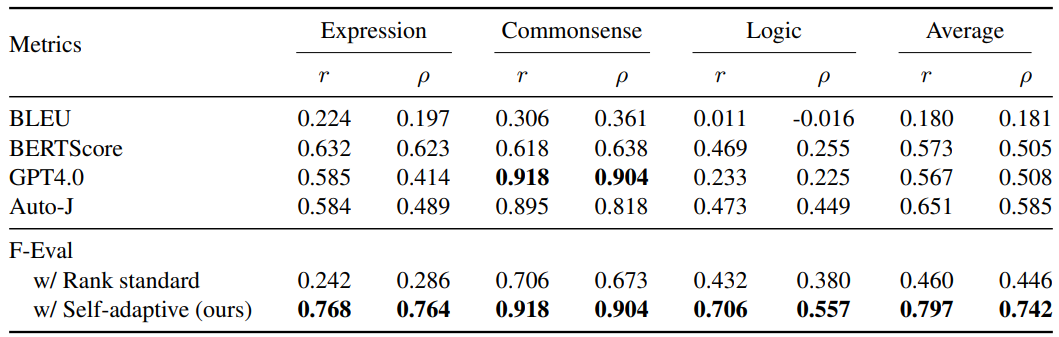
The following is a comparison of the Pearson (r) and Spearman (ρ) correlation coefficients between subjective evaluation methods used in F-Eval and other subjective evaluation methods.
Step 1. Prepare the dataset.
The overall dataset with 2211 samples is in the data/f_eval folder. The selected dataset that is used for
analysis is in data/select_data.
Please download the dataset from the github repo and put it in the data folder under OpenCompass folder.
Step 2. Run the backend server.
Before running evaluation files in OpenCompass, please ensure a backend server is running.
python backend/freq_flask.pyStep 3. Run the evaluation file in OpenCompass.
The main evaluation python files are in the configs/eval_f_eval folder in the forked OpenCompass. f_eval_api.py is
used to evaluate the reference-based subjective datasets which are evaluated by API
models. f_eval_other.py is used to evaluate the other datasets.
You can directly run the following commands to get the results of F-Eval. Detailed usage of evaluation on OpenCompass can be found in the OpenCompass repo.
python -u run.py configs/eval_f_eval/f_eval_api.py -s -r
python -u run.py configs/eval_f_eval/f_eval_other.py -s -rStep 4. Postprocess the results.
After getting original results by OpenCompass, you should first
run postprocess/merge_results.py to get the merged results of each dataset (merge English and Chinese).
Then you can run postprocess/normalize.py to get the uniform results of each dataset.
python postprocess/merge_results.py
python postprocess/normalize.pyIf you find this repo useful, please cite with the following bibtex:
@misc{sun2024feval,
title={F-Eval: Asssessing Fundamental Abilities with Refined Evaluation Methods},
author={Yu Sun and Keyu Chen and Shujie Wang and Qipeng Guo and Hang Yan and Xipeng Qiu and Xuanjing Huang and Dahua Lin},
year={2024},
eprint={2401.14869},
archivePrefix={arXiv},
primaryClass={cs.CL}
}