This is a work in progress project.
Recent publications from DeepMind like (Mnih et al., 2013) and (Lillicrap et al., 2015) in the fields of deep reinforcement learning opened a new field for robot locomotion. Reinforcement learning is a form of machine learning by trial & error. The Robot can evaluate the quality of a state and is trying to advance in order to maximize its reward. By applying deep neural networks we try to generate more complex robot locomotion.
In order to research in the field of model free gait generation we created a quadrupedal robot. By using deep neural networks we try to generate stable walking gaits and even more complex moving tasks.


The robot has three degrees of freedom per leg and is also completely simulable in V-REP.
After simulation we try to transfer the learned behavior to the real robot that is shown in the picture above.
The aim of this project is to teach an agent how to walk and even to localize itself in relation to an arbitrary aim. As you can see in the following video the trained agent always tries to follow the red dot.
<iframe width="560" height="315" src="https://www.youtube.com/embed/SIs9NMIHulU" frameborder="0" allowfullscreen></iframe>The agents learns by using the deep deterministic policy gradient approach by (Lillicrap et al., 2015). Our approach is called DDPG-Gait and consists of two neural networks. The first neural network (the actor) generates the 12 continuous servo positions directly. It gets judged from the second neural network (the critic), that evaluates the state and actions taken by trying to maximize its reward.

- The Actor-Network consists of two hiddenlayers with relu activation. For the Output-layer a tanh-function is used in order to map the output the servo angles.
We used latin hypercube sampling to obtain the Hyperparameters for our model. For training and tuning the neural networks a single Titan X (pascal) was used.
The following pseudocode shows the DDPG Algorithm by (Lillicrap et al., 2015).
The critic is trained by minimizing the bellman equation in line 11. But in contrast to Deep-Q-Learning it only outpus one Q-value per state-action pair. The actor on the other hand can be trained by directly applying the gradient in line 14.
The equation was derived by (Silver et al., 2014).
However enviornment, actions, state and reward need to be defined:
- The Environment is given by the Simulator.
- The most straigh forward approach is to define the actions by a twelve dimensional vector
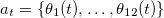
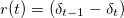
The picture below shows the robot gait pattern.


The next video shows the results for the real robot.
<iframe width="560" height="315" src="https://www.youtube.com/embed/ZHgOhR1QOPs" frameborder="0" allowfullscreen></iframe>We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.
(Mnih et al., 2013), Playing Atari with Deep Reinforcement Learning
(Silver et al. 2014), Deterministic Policy Gradient
(Lillicrap et al., 2015), Continuous control with deep reinforcement learning