![]()
marginalia is an opinionated python library for structured data generation at scale with open LLMs like Mistral or Llama. With proper instructions, marginalia will transform any list of texts into structured data.
The easiest way to discover marginalia is to test it Google Colab:
- Original demo for [text classification] with Mistral OpenHermes 2.5 that requires an A100 (available for colab pro).
- Light demo running on the free version of Google Colab: text generation is done by a "quantized" LLM (autoawq), which results in slower inference and lower quality overall, but still a good way to discover marginalia.
In contrast with other json libraries and frameworks for LLM, marginalia does not rely on controlled generation but on bootstrap generation: instead of selecting LLM output at the token level, marginalia retains or rejects an entire generation.
marginalia is closely integrated with vllm, and takes advantage of its generation speed. Depending on the prompt and the data constraints, a significant share of the generated annotations will not be compliant, either because they are not valid json, because they cannot be unambiguously associated to the original text or because they fail to satisfy some explicit conditions. marginalia will re-generate every non-compliant data until the output is complete.
Other choices include:
- Sending the pieces of data as "batch" (10 elements by default). Previous trials show that hading more than one sample helps the LLM to identify recurring patterns. It may also speed up structured data generation.
- Maintaining consistent numeric identifier for text.
- Fully customizable prompt, which is especially needed when working on non-English languages. The best open LLM are heavily English-focused and will tend to return translated results in English if they are not prompted in the languages of the source.
- Support for open weights LLM by default with vllm. ChatGPT and other API-only solution may be integrated at some point in the future, but they are generally not meeting the requirements for running at scale.
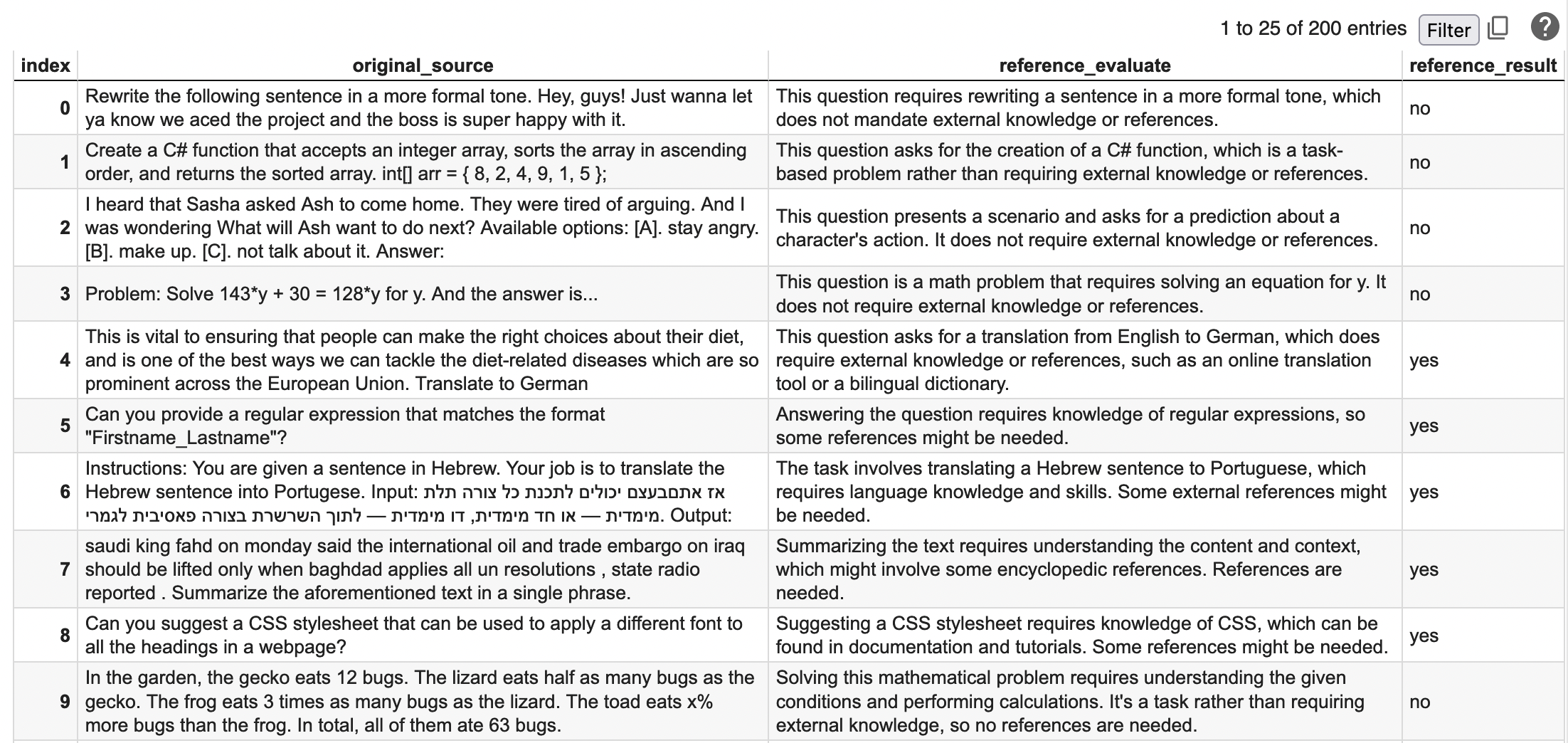
The classification demo starts by attempting to classify rather a question from the OpenHermes dataset requires some external reference to back them up or not. This is a very concrete issue for Retrieval-Generated Augmentation (RAG), as an LLM can be used for a variety of tasks that do not always involve looking for references.
marginalia works with any list of unstructured texts. It will generate id on the fly simply based on the index of the text, as well as return the unprocessed text as part of the json output.
import pandas as pd
unstructured = pd.read_json("https://github.com/Pleias/marginalia/raw/main/notebook/open_hermes_instruction_select.json")["instruction"].tolist()marginalia aims to recover data scheme. They are creating by initiating a list of data entity objects with fields, definitions and data constraints. Basically, you want to apply the data scheme to your unstructured set of text everytime fits.
While they need to be used carefully and in close accordance with the prompt, data constraints are powerful tool to ensure the LLM will generate the data that match your expectations. For now, marginalia support two constraints:
- choices: a limited range of options for the answer. If it exists, the compliant answer will be extracted by marginalia using a regex.
- answer length: a threshold in a number of words for the answer. This is especially practical when you want to add a free-commenting field.
from marginalia import data_entity
data_scheme = [data_entity(field = "reference_evaluate",
definition = "argument whether answering the question is about knowledge and require some references rather than a task like translation, with a few concise sentences",
min_length = 7),
data_entity(field = "reference_result",
definition = "indicate by yes, no or non applicable if references are needed",
choice = ["yes", "no", "non applicable"])]In this example we use both constraints for two different fields:
- "reference_evaluate": has to be a text with at least 7 words.
- "reference_result" has to be a binary answer ("yes" or "no") as well as the option or not being applicable, for instance due to the analysis not being conclusive.
Strong data constraints and unsufficiently clear prompts will result in longer generation and potentially the dataset not being fully annotated.
The core of marginalia functionality is instruction_set. That's where you are going to pass the unstructured text, the data scheme and the prompt instructions.
from marginalia import instruction_set
instructions = instruction_set(data_scheme = data_scheme,
unstructured = unstructured,
system_prompt = "You are a powerful evaluator of user inputs",
input_prompt = "Assess whether theses questions require some encyclopedic references to back them up. References would be typically needed if the answer mandates external knowledge rather than a task to perform like translating two languages, reformulation or solving a math problem based on the element present in the instruction.",
definition_prompt = "Your answer should include the following fields:",
structure_prompt = "Return the results as a json structured like this :",
data_prompt = "Here is the list of questions :",
name_id = "question",
size_batch = 5)As you can notice the prompt has seven parts:
- System prompt: basically defining what kind of the tool LLM is, in a very broad way.
- Input prompt: the actual task at hand.
- Definition prompt: the introductory prompt for the list of definitions stored in the data scheme.
- Structure prompt: the introductory prompt for an empty sample of the json structure.
- Data prompt: the introductory prompt for the list of unstructured text sample.
- Name id: the name used to qualify each unstructured text sample
- Size of the batch: marginalia groups text in batch for quicker inference and enhanced accuracy. Overall your text sample are, the smaller your batch should be to not overload the context window. Here the questions can be long so we settle for a batch of size of 5 instead of the default 10.
Before launching the actual LLM-powered annotation, it is advisable to give a look the data and check if everything is fine. You can do it with test_prompt:
instructions.test_prompt()
print(instructions.prompts[0])Which should return something like:
<|im_start|>system
You are a powerful evaluator of user inputs
<|im_end|>
<|im_start|>user
Assess whether theses questions require some encyclopedic references to back them up. References would be typically needed if the answer mandates external knowledge rather than a task to perform like translating two languages, reformulation or solving a math problem based on the element present in the instruction.
Your answer should include the following fields: the question id ("id"), argument whether answering the question is about knowledge and require some references rather than a task like translation, with a few concise sentences ("reference_evaluate"), indicate by yes, no or non applicable if references are needed ("reference_result")
Return the results as a json structured like this : {"id": "…", "reference_evaluate": "…", "reference_result": "…"}
Here is the list of questions :
question 0: Rewrite the following sentence in a more formal tone. Hey, guys! Just wanna let ya know we aced the project and the boss is super happy with it.
question 1: Create a C# function that accepts an integer array, sorts the array in ascending order, and returns the sorted array. int[] arr = { 8, 2, 4, 9, 1, 5 };
question 2: I heard that Sasha asked Ash to come home. They were tired of arguing. And I was wondering What will Ash want to do next? Available options: [A]. stay angry. [B]. make up. [C]. not talk about it. Answer:
question 3: Problem: Solve 143*y + 30 = 128*y for y. And the answer is...
question 4: This is vital to ensuring that people can make the right choices about their diet, and is one of the best ways we can tackle the diet-related diseases which are so prominent across the European Union. Translate to German
<|im_end|>
<|im_start|> assistant
Then to use the LLM, you need to load it with vllm.
from vllm import LLM, SamplingParams
import os
new_model_name = "mistral-7b-hermes-2.5"
llm = LLM(new_model_name)
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=8000, presence_penalty = 0)At this point, the actual annotation is one command:
instructions.llm_generate_loop(llm, sampling_params)You'll notice that marginalia does several pass on vllm to send again any non-compliant json.
By the end of this process you can check your json:
instructions.valid_jsonOr, since it's a flat json, immediately convert it to a tabular format.
import pandas as pd
result = pd.DataFrame(instructions.valid_json)[['original_source', 'reference_evaluate', 'reference_result']]
resultResults should look like this: