

免费,开源,可批量的离线OCR软件
适用于 Windows7 x64 及以上
适用于 Windows7 x64 及以上
这里是记录 Umi-OCR 全新重构版本v2.0的仓库。
- 全新升级:V2版本重构了绝大部分代码,提供焕然一新的界面和更强大的功能。
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 高效:自带高效率离线OCR引擎。只要电脑性能足够,可以比在线OCR服务更快。
- 灵活:支持定制界面,支持命令行、HTTP接口等多种调用方式。
开发者请务必阅读 构建项目 。
Umi-OCR v2 由一系列灵活好用的标签页组成。您可按照自己的喜好,打开需要的标签页,并锁定标签栏。
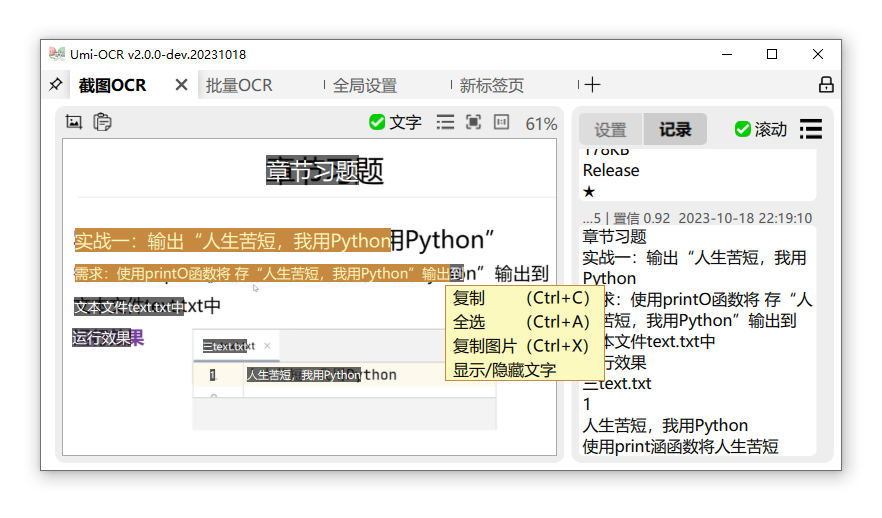
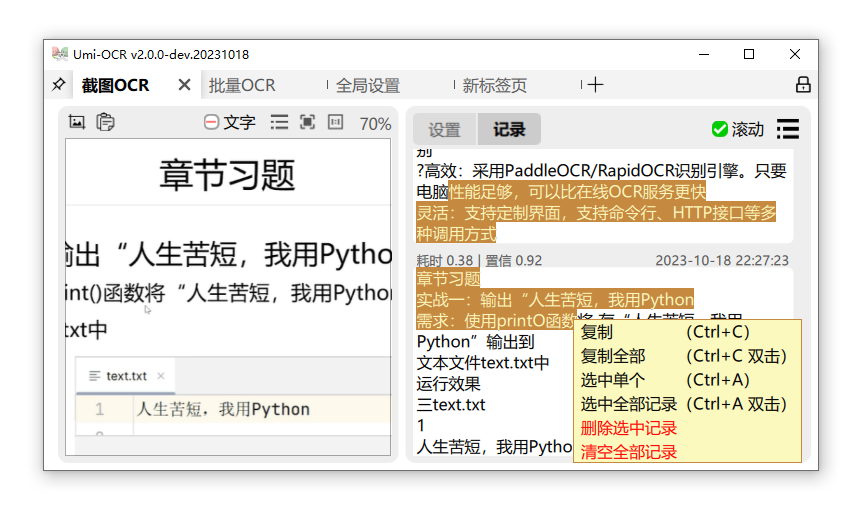
截图OCR:打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
- 左侧的图片预览栏,可直接用鼠标划选复制。
- 右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
- 也支持在别处复制图片,粘贴到Umi-OCR进行识别。

批量OCR:这一页支持批量导入本地图片并识别。
- 识别内容可以保存为 txt / jsonl / md / csv(Excel) 等多种格式。
- 支持
文本后处理技术,能识别属于同一自然段的文字,并将其合并。还支持代码段、竖排文本等多种处理方案。 - 没有数量上限,可一次性导入几百张图片进行任务。
- 支持任务完成后自动关机/待机。
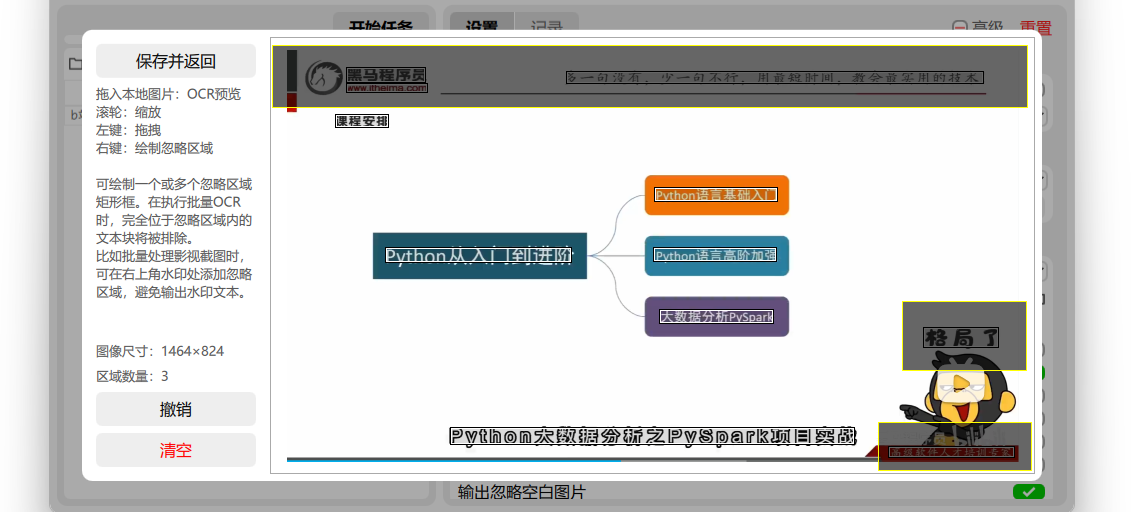
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。

二维码:这里可以扫码。
- 支持多种格式的二维码、条形码。
- 支持一图多码。
- 可截图/粘贴/拖入本地图片。
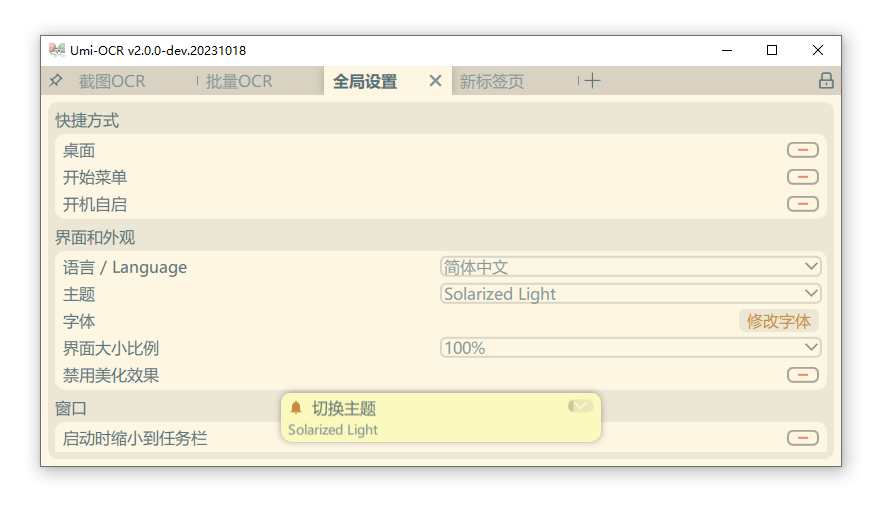
全局设置:在这里可以调整软件的全局参数。
- 支持更改界面语言。(翻译校对工作将在第一个正式版发布后进行)
- 支持切换界面主题。Umi-OCR拥有多个亮/暗主题。
- 可以调整界面文字大小、文字字体。
- 切换OCR插件。
- 多国语言界面:软件界面支持多国语言。目前预览阶段为AI翻译生成,可能词义和排版不好,或者有错漏的情况。正式发布时会进行人工校对。
- 渲染器:软件界面默认支持显卡加速渲染。但是如果在你的机器上出现截屏闪烁、UI错位的情况,请调整
全局设置→界面和外观→渲染器。 - 文本块后处理(段落合并) 可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案如下:
- 单行:合并同一行的文字,适合绝大部分情景。
- 多行-自然段:智能识别、合并属于同一段落的文字,适合绝大部分情景。
- 多行-代码段:尽可能还原原始排版的缩进与空格。适合识别代码片段,或需要保留空格的场景。
- 竖排:适合竖排排版。需要与同样支持竖排识别的模型库配合使用。
- 命令行手册: README_CLI.md
- HTTP接口手册: README_HTTP.md
已完成的工作
- 标签页框架。
- OCR API控制器。
- OCR 任务控制器。
- 主题管理器,支持切换浅色/深色主题主题。
- 实现 批量OCR。
- 实现 截图OCR。
- 快捷键机制。
- 系统托盘菜单。
- 文本块后处理(排版优化)。
- 引擎内存清理。
- 软件界面多国语言。
- 命令行模式。
- Win7兼容。
- Excel(csv)输出格式。
Esc中断截图操作- 外置主题文件
- 字体切换
- 加载动画
- 忽略区域。
- 二维码识别。
- 批量识别页面的图片预览窗口。
近期准备进行的工作,将会在 v2 头几个版本内逐步上线。
- 快捷键权限优化。
- 允许隐藏托盘图标。
- 截图联动/截图翻译。
- PDF识别。
- 高级截图(仿Snipaste,支持贴图)。
展开
这些是预想中的功能,在开发初期已预留好接口,将在远期慢慢实现。
但开发途中受限于实际情况,可能更改功能设计、新增及取消功能。
- 基于GPU的离线OCR。
- 离线翻译。
- 插件系统。
- 固定区域识别。
- 识别表格图片,输出为Excel。
- 根据系统的深/浅模式,自动切换主题。
- 历史记录系统。
- 兼容 MacOS / Ubuntu 等平台。
** 后缀表示本仓库(主仓库)包含的内容。
Umi-OCR
├─ Umi-OCR.exe
└─ UmiOCR-data
├─ main.py **
├─ version.py **
├─ site-packages
│ └─ python包
├─ runtime
│ └─ python解释器
├─ qt_res **
│ └─ 项目qt资源,包括图标和qml源码
├─ py_src **
│ └─ 项目python源码
├─ plugins
│ └─ 插件
└─ i18n **
└─ 翻译文件
支持的离线OCR引擎:
运行环境框架:
- PyStand 定制版
强烈建议只 clone 主分支,因为某些分支含有体积很大的二进制库,会让你花费很长时间下载。
git clone --branch main --single-branch https://github.com/hiroi-sora/Umi-OCR_v2.git
根据下列文档,完成对应平台的开发/运行环境部署。
- Windows
- 跨平台的支持筹备中
- 新增:记忆窗口位置。 (#44)
- 新增:批量识图页增加图片预览窗口,单击图片条目打开。 (#2)
- 新增:检查软件是否有权限读写配置文件。 (#30)
- 新增:报错弹窗提供一键复制及打开issues的功能。
- 新增:全局设置页添加左侧目录栏。
- 新增:插件的多国语言UI机制。
- 优化:截图预览面板中,文本框的位置更准确。
- 优化:调整部分UI布置。
- 修复:扫码模块添加导入异常检查。 (#33)
- 修复:补充扫码页的拖入图片功能。 (#43)
- 修复:输出到单独文件txt时,文件名去除原后缀。 (#36)
- 修复:一些小Bug。
- 新增:命令行支持传入图片路径。 (#28)
- 新增:HTTP接口支持Base64传输图片。 (#28)
- 新增:忽略区域功能。
- 新增:二维码识别页。支持识别多种格式的二维码、条形码。 (Umi-OCR #95)
- 新增:提供备选启动器
UmiOCR-data/RUN_GUI.bat,供Umi-OCR.exe不兼容时使用。 (#21) - 优化:图片预览窗口,支持用
Tab切换显示/隐藏文本。 - 优化:记录面板,每条记录顶部添加复制按钮。 (#32)
- 优化:记录面板,拖拽过程中允许指针移出文本框区域。 (#32)
- 优化:重新设计截图缓存机制,避免Image组件销毁时的内存泄露。
- 优化:标签页应用动态解析机制,小幅提高加载速度。
- 优化:运行环境转为64位包。(计划不再提供对32位的兼容)
- 修正:配置项中布尔值解析不正确的问题。 (#30)
- 修正:拖入非图片文件可能导致卡顿几秒的问题。
- 修正:PaddleOCR插件的兼容性问题。 (Umi-OCR #209)
- 新增:截图前自动隐藏窗口。 (#26)
- 新增:更改字体功能。 (#25)
- 新增:可爱的加载动画。
- 新增:截图预览面板 支持显示结果文本、划选文本。
- 新增:截图预览面板 支持将图片复制到剪贴板。
- 新增:结果记录面板 支持跨文本框划选文本。 (#18)
- 新增:结果记录面板 支持删除一条或多条记录。 (#10)
- 新增:支持用Esc或右键中断截图。
- 优化:更改插件目录结构和导入机制。
- 修正:文件重复导致无法添加开机自启。 (#27)
- 新功能:第一次启动软件时,根据系统情况,选择最恰当的渲染器。解决截图闪烁问题。 (#7)
- 新功能:初步实现插件机制,切换引擎等组件更加便捷。
- 新功能:支持调整界面比例(文字大小)。
- 优化:调整截图页UI,提高屏占比。优化标签栏阴影。 (#8)
- 优化:双击通知弹窗可打开主窗口。 (#10)
- 优化:截图完成后,如果主窗口在前台,则不弹出成功提示。 (#10)
- 优化:禁用美化效果时,外部弹窗将不会渲染阴影区域。 (#14)
- 优化:Paddle引擎也支持win7系统了。