Create async HTTP requests with Python in no time.
![]()




With Unparallel you can easily create thousands of web requests in an efficient way leveraging Python's async capabilities.
Unparallel is built on top of HTTPX and aims to support its rich set of features.
pip install unparallelA simple example of doing several GET requests to an HTTP web service:
import asyncio
from unparallel import up
async def main():
urls = [f"https://httpbin.org/get?i={i}" for i in range(5)]
results = await up(urls)
print([item["args"] for item in results])
if __name__ == "__main__":
asyncio.run(main())This prints:
Making async requests: 100%|███████████| 5/5 [00:00<00:00, 9.98it/s]
[{'i': '0'}, {'i': '1'}, {'i': '2'}, {'i': '3'}, {'i': '4'}]
Similarly, we can do a bunch of POST requests. This time we will use a single path but multiple payloads:
import asyncio
from unparallel import up
async def main():
url = "https://httpbin.org/post"
payloads = [{"obj_id": i} for i in range(5)]
results = await up(url, method="post", payloads=payloads)
print([item["data"] for item in results])
asyncio.run(main())This prints:
Making async requests: 100%|███████████| 5/5 [00:00<00:00, 9.98it/s]
['{"obj_id": 0}', '{"obj_id": 1}', '{"obj_id": 2}', '{"obj_id": 3}', '{"obj_id": 4}']
For more details on the usage and examples, check out the docs.
Async is a really powerful feature - especially when you have to wait for I/O. When we create HTTP requests synchronously we have to wait for every response before we can start with the next request. If we utilize asynchronous programming, our runtime thread can do other work (other requests) during those periods of waiting.
Here is an example of making 20 web requests synchronously vs. asynchronously via unparallel.
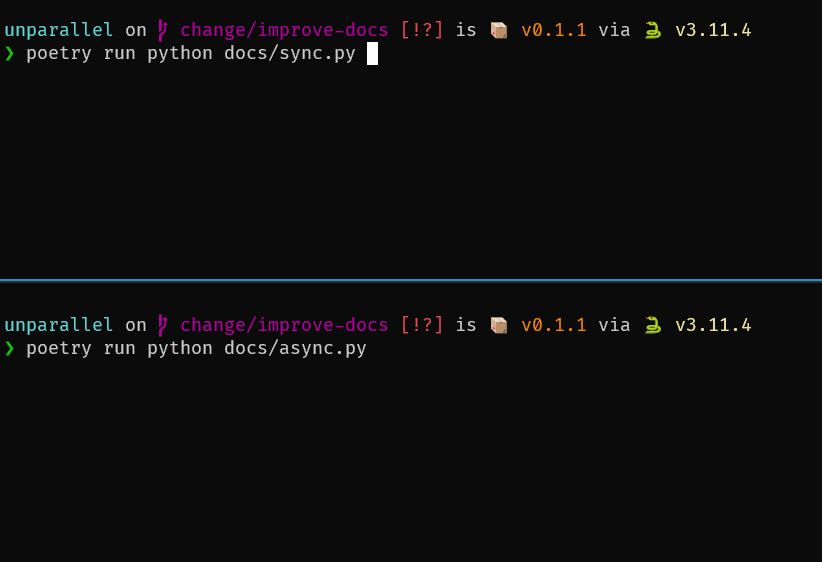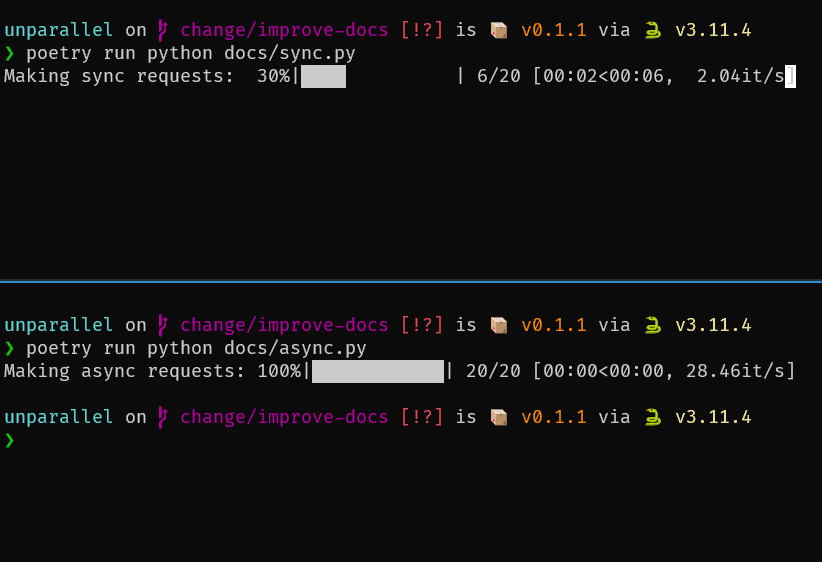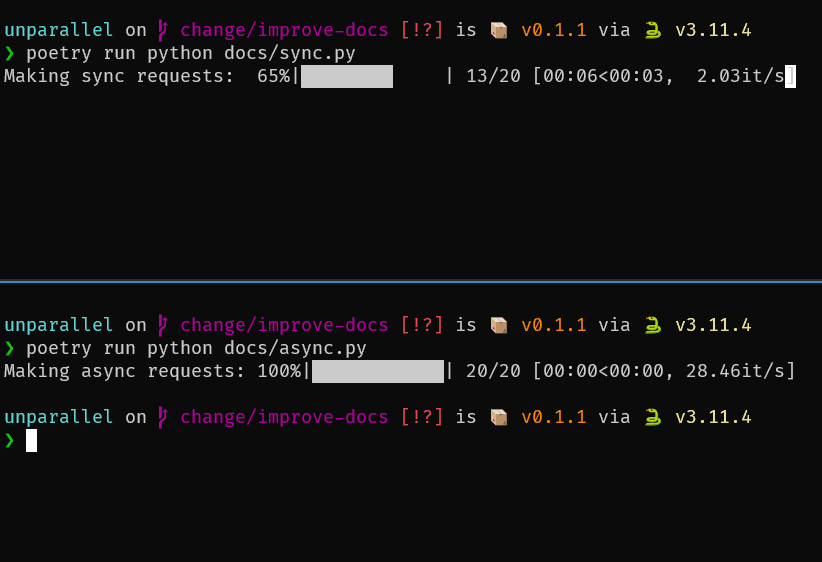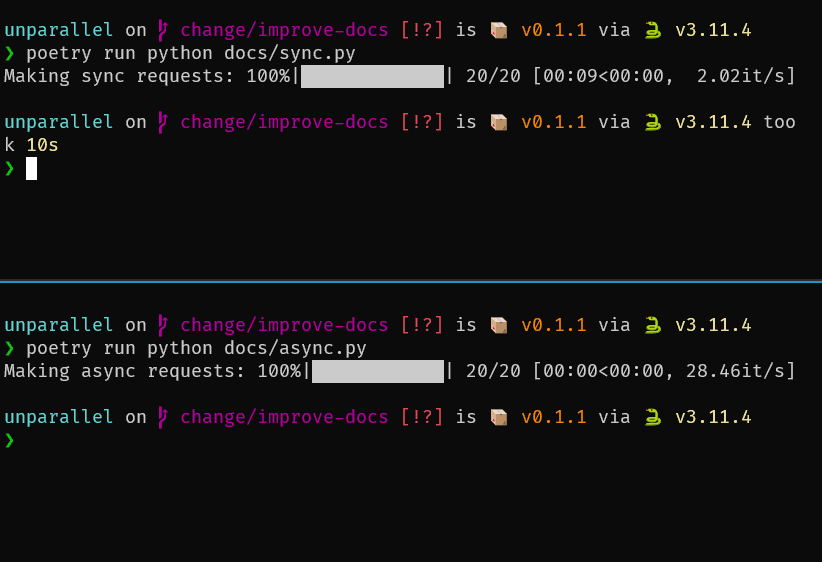
As you can see, the async version finishes in less than a second while the sync code runs for around 10 seconds. The difference gets even more drastic if you create much more requests.
You can find the sync/async code in the docs folder.
As this project is still in early development, I'm happy for any feedback and contributions! Please refer to the contributing guidelines for details.
This project is licensed under the terms of the MIT license. See LICENSE for more details.
This project was heavily inspired by the blog post Making 1 million requests with python-aiohttp by Paweł Miech.
I created this project with python-package-template.