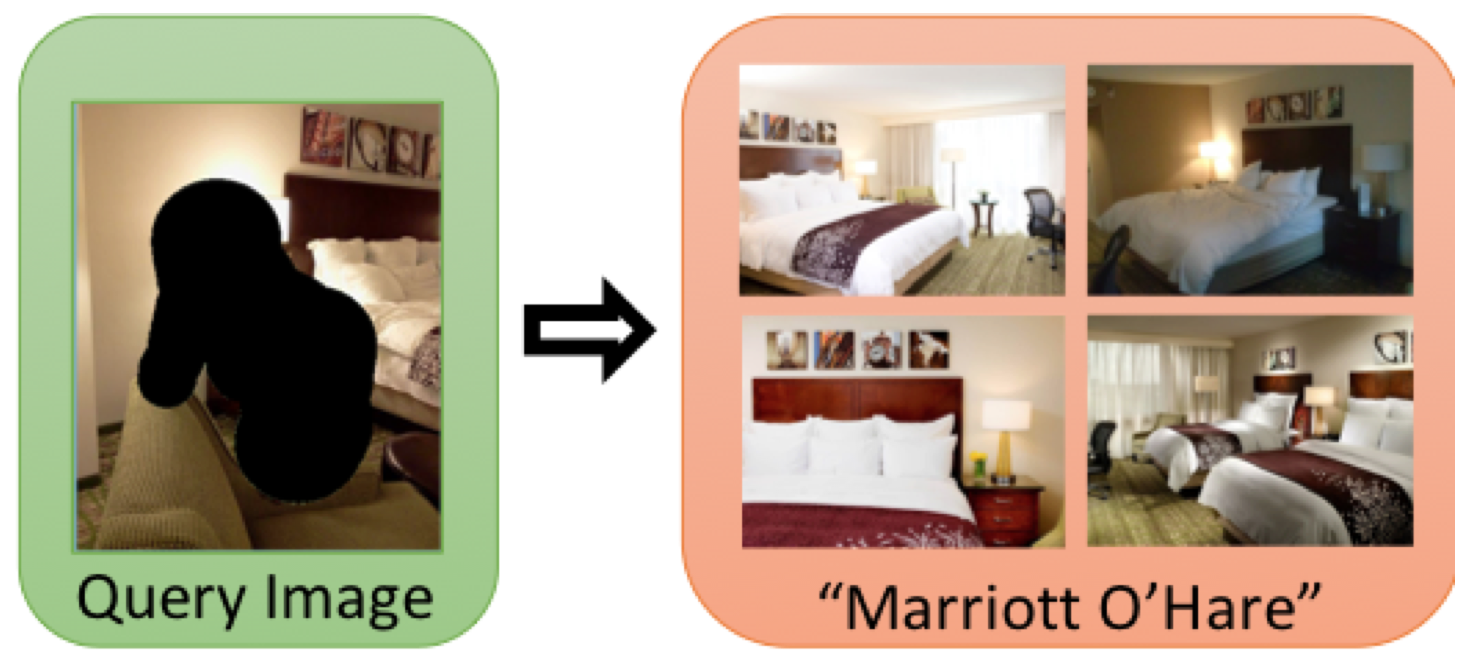
The Hotels-50K dataset was created to encourage work in hotel recognition, the task of identifying the hotel in images taken in hotel rooms. This task is particularly important as many photographs of human trafficking victims are captured in hotel rooms, and identifying which hotels the victims were photographed in is a top priority for trafficking investigators.
The Hotels-50K dataset (introduced in https://www2.seas.gwu.edu/~pless/papers/Hotels50k.pdf) consists of over 1 million images from 50,000 different hotels around the world. These images come from both travel websites, as well as the TraffickCam mobile application, which allows every day travelers to submit images of their hotel room in order to help combat trafficking. The TraffickCam images are more visually similar to images from trafficking investigations than the images from travel websites.
The training dataset includes 1,027,871 images from 50,000 hotels, and 92 major hotel chains. Of the 50,000 hotels, 13,900 include user contributed images from the TraffickCam application (a total of 55,061 TraffickCam images are included in the training set).
The test dataset includes 17,954 TraffickCam images from 5,000 different hotels (as well as versions of the test images that have medium and large occlusions to replicate the occlusions seen in real world trafficking victim photographs).
(UPDATE: A large number of the hyperlinks provided in the original dataset were moved after the fact by the imagery providers. We have updated the dataset to have valid imagery as of April 27, 2020. The above values are roughly correct but need to be updated to reflect the new dataset.)
We recommend using Python 2.7. To insure the correct dependencies are installed, run:
pip install -r requirements.txt
Re-implementation of our baseline methods additionally requires Facebook's 'Faiss' library for efficient similarity search (https://github.com/facebookresearch/faiss). Instructions for installing Faiss can be found at https://github.com/facebookresearch/faiss/blob/master/INSTALL.md. Be sure to do both step 1 for the library install and step 2 for the Python interface.
The metadata for the hotels, chains and images is in the 'input/dataset.tar.gz' file. When you decompress this folder, you will find four csv files with the following headers:
- chain_info.csv: chain_id, chain_name
- hotel_info.csv: hotel_id, hotel_name, chain_id, latitude, longitude
- train_set.csv: image_id, hotel_id, image_url, image_source, upload_timestamp
- test_set.csv: image_id, hotel_id, image_url, image_source, upload_timestamp
The test images (unoccluded and occluded) can be downloaded from https://cs.slu.edu/~stylianou/images/hotels-50k/test.tar.lz4 (3.14GB; to match the training dataset structure, download this file to the images directory and decompress it there).
To download the training images, we provide the 'download_train.py' file, which downloads and scales down the images in the train_set file into 'images/train' (make sure you've decompressed the 'input/dataset.tar.gz' folder first).
The script downloads the images into the following structure (which matches the test image organization):
images/train/chain_id/hotel_id/data_source/image_id.jpg
The testing dataset includes four folders: unoccluded, low_occlusions, medium_occlusions, high_occlusions. The images within these folders are organized in the same structure as the training set.
The test images in the low_occlusions, medium_occlusions and high_occlusions folders are pre-masked with people shaped occlusions extracted from the MS COCO dataset, to mimic the sorts of occlusions found in real world trafficking victim photographs. The mask applied to a particular image can be found in the folder:
images/test/(low/medium/high)\_occlusions/chain_id/hotel_id/data_source/masks/image_id.png
In addition to the masked test images, we additionally provide a set of people shaped occlusions which aren't used in the test set, that can be used during your training process. These images can be found in the 'images/people_crops.tar.gz' compressed folder.
We provide code to evaluate how well different approaches perform hotel recognition in the context of human trafficking investigations. There are two different metrics that are computed: image retrieval ('evaluate/retrieval.py') and multi-class log loss ('evaluate/log_loss.py').
python evaluate/retrieval.py knn_results.csv
The retrieval evaluation code reports the average top-K accuracy by both hotel instance (K={1,10,100}) and hotel chain (K={1,3,5}).
It expects as input a comma-separated file with the image IDs for the top 100 retrieved images. Each row should be formatted as follows:
test_image_id, result1_image_id, result2_image_id, ... , result100_image_id
Image IDs can be extracted from the image file names (each file is named image_id.jpg).
You can generate CSVs for each of the test sets with varying occlusion levels to evaluate how your approach performs as a function of the size of the occlusion.
The following figure shows the top-K retrieval results (%) by hotel instance from the original Hotels50K paper:
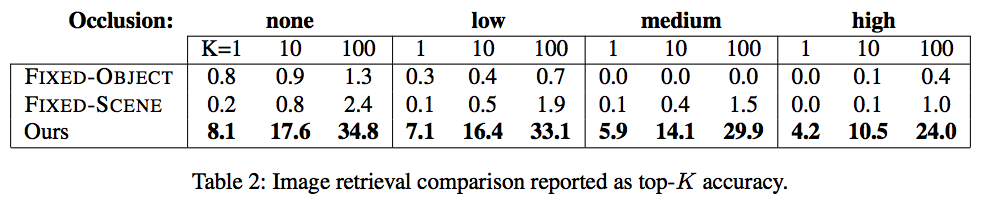
Note that there is a slight discrepancy between the hotel chain retrieval results generated by this code and the results in the paper. In the paper, we consider the hotel chain retrieval accuracy of only query images with a known chain, and result images with a known chain. For simplicity sake, the provided code does not assume that the result images are only from a known chain. Running this code on our pretrained models produces hotel chain retrieval accuracy of 40.4, 54.1, and 60.4 for the unoccluded test for K = 1, 3 and 5, respectively.
python evaluate/log_loss.py class_probabilities.csv
The log loss evaluation code reports the multi-class log loss by both hotel instance and hotel chain for a particular test set, and takes as input a csv of class probabilities organized as follows:
test_image_id, class1_id, class1_probability, class2_id, class2_probability, ... , class50000_id, class50000_probability
While each row can include up to 50,000 classes, you only need to provide (id, probability) pairs for classes that have non-zero probabilities. Each row can have a different number of (id, probability) pairs.
If you just have retrieval results (for example, if you trained an embedding and don't have class probabilities), you can use the following script to convert the k-NN retrieval results from above to class probabilities:
python evaluate/convert_knn_to_probabilities.py input_knn_results_file.csv output_class_probabilities_file.csv
This will convert the k-NN retrieval results into posterior probabilities which can then be used as the input to the multi-class log loss metric, and save the results out to 'output_class_probabilities_file.csv'.
The following figure shows the log loss by hotel instance from the original Hotels50K paper (computed by converting the k-NN results to posterior probabilities, where k=100):
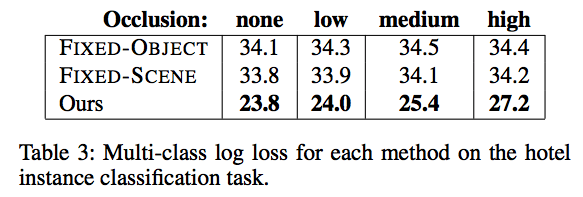
Note: If you are converting from k-NN retrieval results to class probabilities, you may want to modify your retrieval results and the convert_knn_to_probabilities.py to consider k > 100.
In order to re-produce the results in our paper, you can download our pre-trained model from https://www2.seas.gwu.edu/~astylianou/hotels50k/hotels50k_snapshot.tar.gz.
You can then run:
python baseline_implementation/extract_features.py pretrained_model_dir/pretrained_model
to extract the gallery and test image features for each of the different tests (unoccluded, low, medium and high occlusions). (Do not include the file suffixes in the pretrained_model name. For example, if you download the pretrained net to hotels50k_snapshot, the above command would be 'python baseline_implementation/extract_features.py hotels50k_snapshot/hotels50k').
To compute the CSV file needed for the retrieval evaluation, you will then want to run:
python baseline_implementation/feats_to_csv.py
This will save out CSV files for each of the tests to baseline_implementation/csv_output. These CSVs can be used directly as the input to the retrieval.py code, and to create the input for the log loss code by using the convert_knn_to_probabilities.py script.
To cite this work, please use:
@inproceedings{hotels50k,
author = {Stylianou, Abby and Xuan, Hong and Shende, Maya and Brandt, Jonathan and Souvenir, Richard and Pless, Robert},
title = {Hotels-50K: A Global Hotel Recognition Dataset},
booktitle = {The AAAI Conference on Artificial Intelligence (AAAI)},
year = {2019}
}