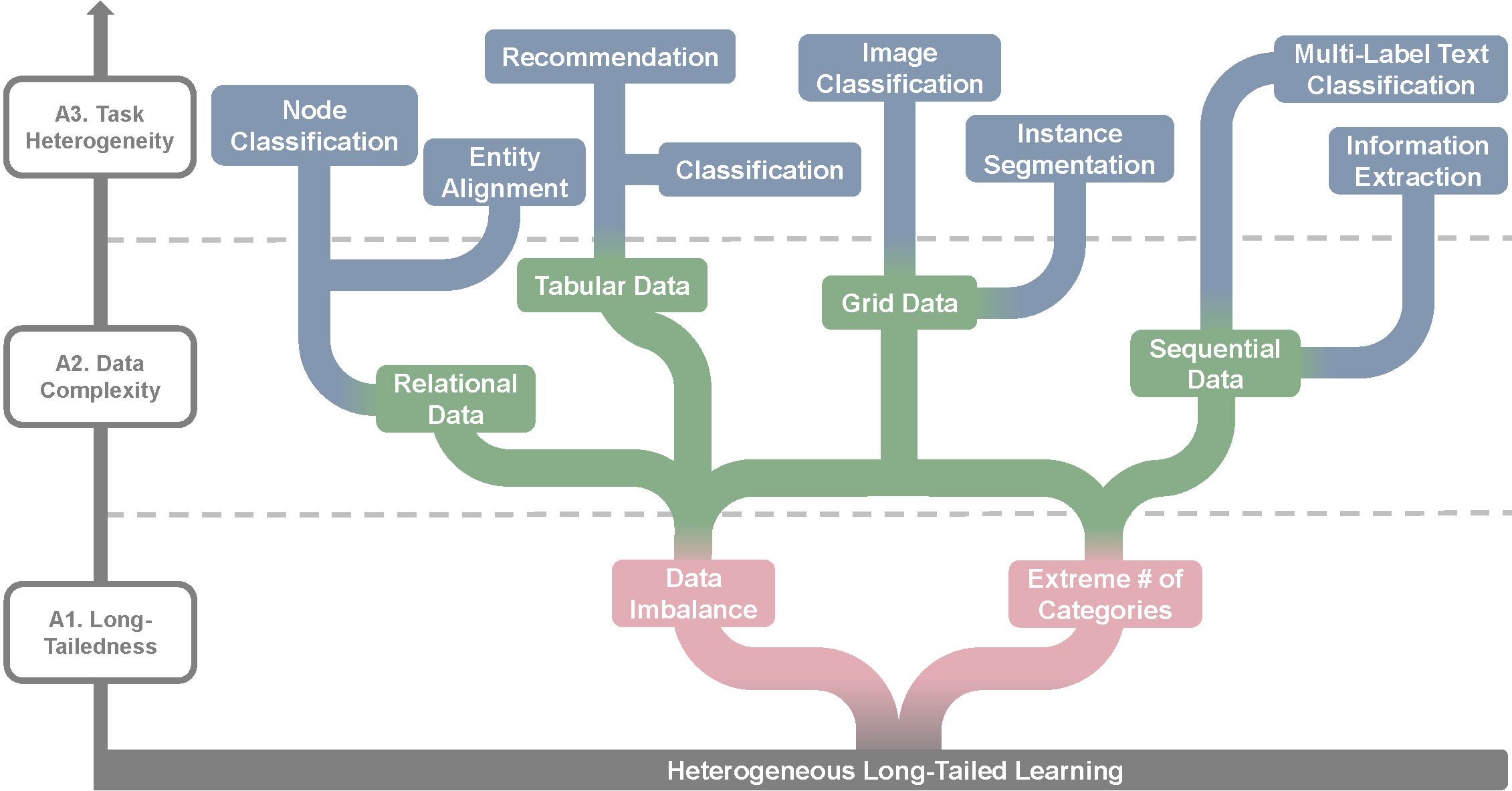
HeroLT is a comprehensive long-tailed learning benchmark that examine long-tailed learning concerning three pivotal angles:
- (A1) the characterization of data long-tailedness: long-tailed data exhibits a highly skewed data distribution and an extensive number of categories;
- (A2) the data complexity of various domains: a wide range of complex domains may naturally encounter long-tailed distribution, e.g., tabular data, sequential data, grid data, and relational data; and
- (A3) the heterogeneity of emerging tasks: it highlights the need to consider the applicability and limitations of existing methods on heterogeneous tasks.
We provide a fair and accessible performance evaluation of 13 state-of-the-art methods on multiple benchmark datasets across multiple tasks using accuracy-based and ranking-based evaluation metrics.
| Code Structure | Quick Start | Algorithms | Datasets | Example | Publications |
HeroLT
├── HeroLT
│ ├── configs # Customizable configurations
│ ├── data # Datasets in HeroLT
│ | ├── ... ..
│ ├── nn
│ | ├── Dataloaders
│ | ├── Datasets
│ | ├── layers
│ | ├── Models
│ | ├── Modules
│ | ├── Samplers
│ | ├── Schedulers
│ | ├── Wrappers # Algorithms in HeroLT
│ | ├── loss # Loss functions in long-tailed learning
│ | ├── pecos
│ | ├── xbert
│ ├── outputs
│ | ├── ... ..
│ ├── tools
│ | ├── ... ..
│ ├── utils # utility functions and classes
│ | ├── ... ..
├── examples # Examples of running the specific method
├── figs
└── README.md
We provide the following example for users to quickly implementing HerolT.
First of all, users need to clone the source code and install the required packages:
- torch==1.10.2
- torch-geometric==2.0.4
- torchvision
- numpy==1.21.5
- scipy==1.7.3
- scikit-learn==1.1.1
To run an LT task, users should prepare a dataset. The DataZoo provided in HeroLT can help to automatically download and preprocess widely-used public datasets for various LT applications, including CV, NLP, graph learning, etc. Users can directly specify dataset = DATASET_NAMEin the configuration. For example,
GraphSMOTE('wiki', './HeroLT/')Then, users should specify the model architecture that will be trained. HeroLT provides a ModelZoo that contains the implementation of widely adopted model architectures for various LT tasks. Users can import MODEL_NAME to apply a specific model architecture in LT tasks. For example,
from HeroLT.nn.Wrappers import GraphSMOTEHere we demonstrate how to run a standard LT task with HeroLT, with setting dataset = 'wiki'and import GraphSMOTE to run GraphSMOTE for an node classification task on Cora_Full dataset. Users can customize training configurations, such as lr, in the configs/GraphSMOTE/config.yaml, and run a standard LT task as:
# Run with default configurations
from HeroLT.nn.Wrappers import GraphSMOTE
model = GraphSMOTE('wiki', './HeroLT/')
model.train()Then you can observe some monitored metrics during the training process as:
============== seed:123 ==============
[seed 123][GraphSMOTE][Epoch 0][Val] ACC: 21.6, bACC: 17.9, Precision: 16.5, Recall: 16.8, mAP: 15.7|| [Test] ACC: 18.8, bACC: 13.3, Precision: 16.5, Recall: 13.3, mAP: 11.6
[*Best Test Result*][Epoch 0] ACC: 18.8, bACC: 13.3, Precision: 16.5, Recall: 13.3, mAP: 11.6
[seed 123][GraphSMOTE][Epoch 100][Val] ACC: 68.1, bACC: 60.5, Precision: 60.5, Recall: 60.5, mAP: 59.8|| [Test] ACC: 68.0, bACC: 54.1, Precision: 56.7, Recall: 54.1, mAP: 53.2
[*Best Test Result*][Epoch 100] ACC: 68.0, bACC: 54.1, Precision: 56.7, Recall: 54.1, mAP: 53.2
[seed 123][GraphSMOTE][Epoch 200][Val] ACC: 67.7, bACC: 59.0, Precision: 57.9, Recall: 59.0, mAP: 58.4|| [Test] ACC: 67.4, bACC: 54.1, Precision: 56.7, Recall: 54.1, mAP: 52.9
[*Best Test Result*][Epoch 102] ACC: 67.8, bACC: 54.0, Precision: 56.4, Recall: 54.0, mAP: 53.2
[seed 123][GraphSMOTE][Epoch 300][Val] ACC: 67.2, bACC: 58.6, Precision: 58.9, Recall: 58.6, mAP: 58.0|| [Test] ACC: 67.1, bACC: 53.6, Precision: 57.7, Recall: 53.6, mAP: 52.3
[*Best Test Result*][Epoch 102] ACC: 67.8, bACC: 54.0, Precision: 56.4, Recall: 54.0, mAP: 53.2
... ...
HeroLT includes 13 algorithms, as shown in the following Table.
| Algorithm | Venue | Long-tailedness | Task |
|---|---|---|---|
| X-Transformer | 20KDD | Data imbalance, extreme # of categories | Multi-label text classification |
| XR-Transformer | 21NeurIPS | Data imbalance, extreme # of categories | Multi-label text classification |
| XR-Linear | 22KDD | Data imbalance, extreme # of categories | Multi-label text classification |
| BBN | 20CVPR | Data imbalance | Image classification |
| BALMS | 20NeurIPS | Data imbalance | Image classification, Instance segmentation |
| OLTR | 19CVPR | Data imbalance, extreme # of categories | Image classification |
| TDE | 20NeurIPS | Data imbalance, extreme # of categories | Image classification |
| MiSLAS | 21CVPR | Data imbalance | Image classification |
| Decoupling | 20ICLR | Data imbalance | Image classification |
| GraphSMOTE | 21WSDM | Data imbalance | Node classification |
| ImGAGN | 21KDD | Data imbalance | Node classification |
| TailGNN | 21KDD | Data imbalance, extreme # of categories | Node classification |
| LTE4G | 22CIKM | Data imbalance, extreme # of categories | Node classification |
HeroLT includes 14 datasets, as shown in the following Table.
| Data Statistics | Long-Tailedness | ||||||
|---|---|---|---|---|---|---|---|
| Dataset | Data | # of Categories | Size | # of Edges | IF | Gini | Pareto |
| EURLEX-4K | Sequential | 3,956 | 15,499 | - | 1,024 | 0.342 | 3.968 |
| AMAZONCat-13K | Sequential | 13,330 | 1,186,239 | - | 355,211 | 0.327 | 20.000 |
| Wiki10-31K | Sequential | 30,938 | 14,146 | - | 11,411 | 0.312 | 4.115 |
| ImageNet-LT | Grid | 1,000 | 115,846 | - | 256 | 0.517 | 1.339 |
| Places-LT | Grid | 365 | 62,500 | - | 996 | 0.610 | 2.387 |
| iNatural 2018 | Grid | 8,142 | 437,513 | - | 500 | 0.647 | 1.658 |
| CIFAR 10-LT (100) | Grid | 10 | 12,406 | - | 100 | 0.617 | 1.751 |
| CIFAR 10-LT (50) | Grid | 10 | 13,996 | - | 50 | 0.593 | 1.751 |
| CIFAR 10-LT (10) | Grid | 10 | 20,431 | - | 10 | 0.520 | 0.833 |
| CIFAR 100-LT (100) | Grid | 100 | 10,847 | - | 100 | 0.498 | 1.972 |
| CIFAR 100-LT (50) | Grid | 100 | 12,608 | - | 50 | 0.488 | 1.590 |
| CIFAR 100-LT (10) | Grid | 100 | 19,573 | - | 10 | 0.447 | 0.836 |
| LVIS v0.5 | Grid | 1,231 | 693,958 | - | 26,148 | 0.381 | 6.250 |
| Cora-Full | Relational | 70 | 19,793 | 146,635 | 62 | 0.321 | 0.919 |
| Wiki | Relational | 17 | 2,405 | 25,597 | 45 | 0.414 | 1.000 |
| Relational | 42 | 1,005 | 25,934 | 109 | 0.413 | 1.263 | |
| Amazon-Clothing | Relational | 77 | 24,919 | 208,279 | 10 | 0.343 | 0.814 |
| Amazon-Eletronics | Relational | 167 | 42,318 | 129,430 | 9 | 0.329 | 0.600 |
Here, we present a motivative application of the recommendation system, which naturally exhibits long-tailed data distributions coupled with data complexity [2] (e.g., tabular data and relational data) and task heterogeneity (e.g., user profiling [1] and recommendation [2]).

[1] E. Purificato, L. Boratto, and E. W. De Luca, “Do graph neural networks build fair user models? assessing disparate impact and mistreatment in behavioural user profiling”. CIKM 2022.
[2] F. Liu, Z. Cheng, L. Zhu, C. Liu, and L. Nie, “An attribute-aware attentive GCN model for attribute missing in recommendation”. IEEE Transactions on Knowledge and Data Engineering 2022.