OSTMap (Open Source Tweet Map)
OSTMap development started as a project at the IT-Ringvorlesung 2016. A team of six students (and some help of two big data experts from mgm tp) implements OSTMap over a period of 6 weeks.
OSTMap reads geotagged data from the twitter stream. We save it to an small hadoop cluster (1 master, 4 worker nodes) running HDP 2.4 with Apache Accumulo and Apache Flink. In addition we have a user interface to search for tweets by a term search and a map search. The results are presented as a list or on the map. In addition we run analysis batch jobs on this data.
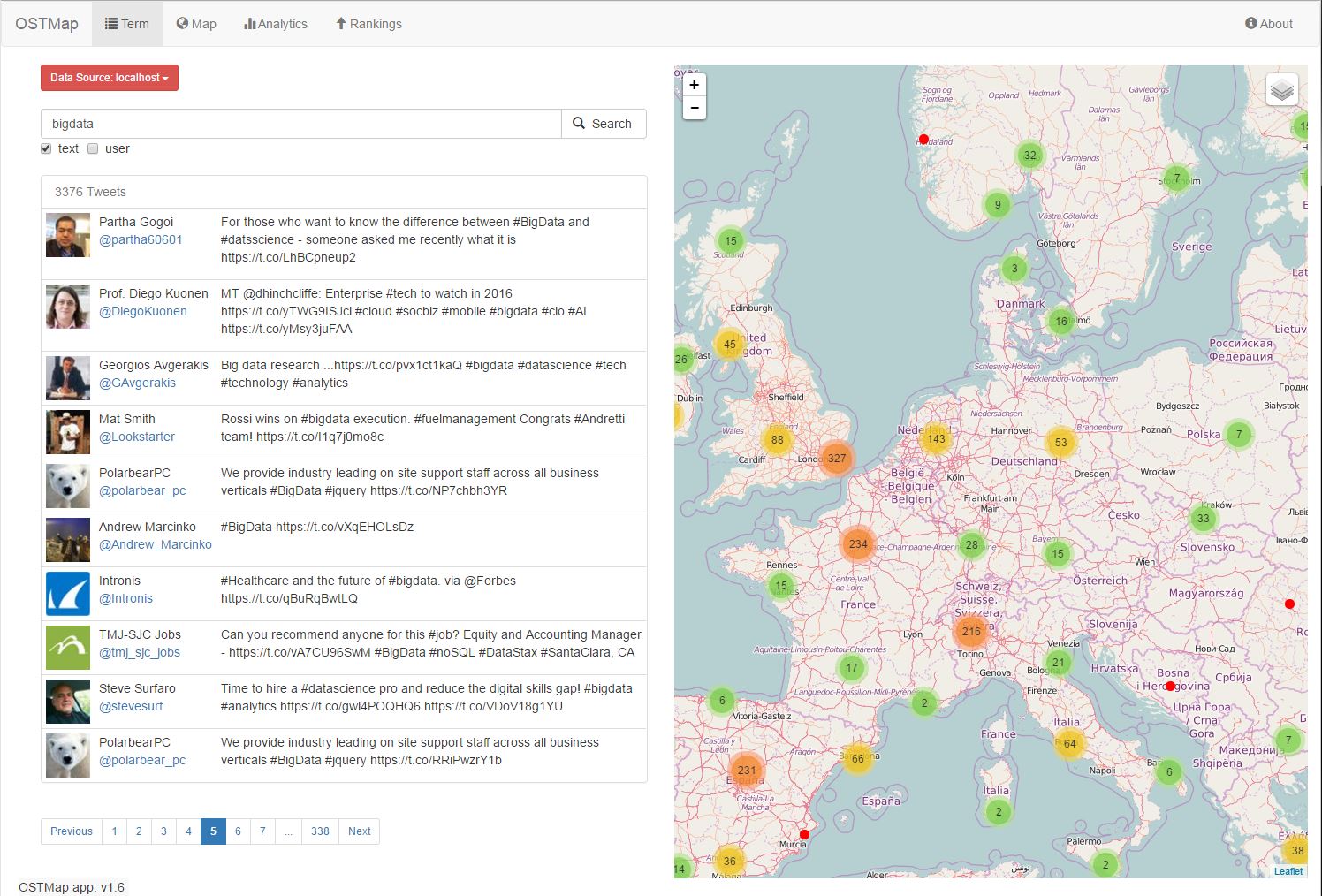
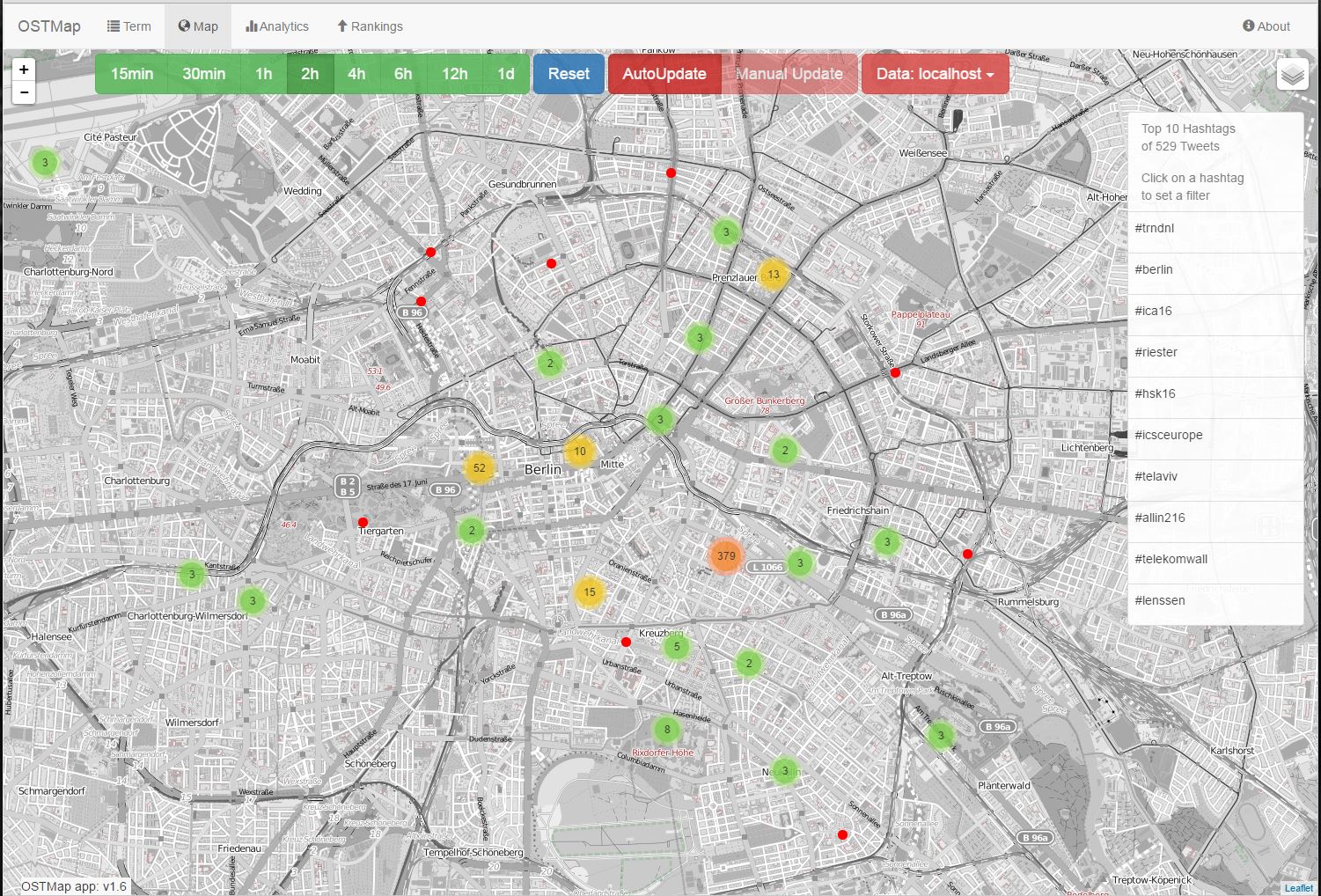
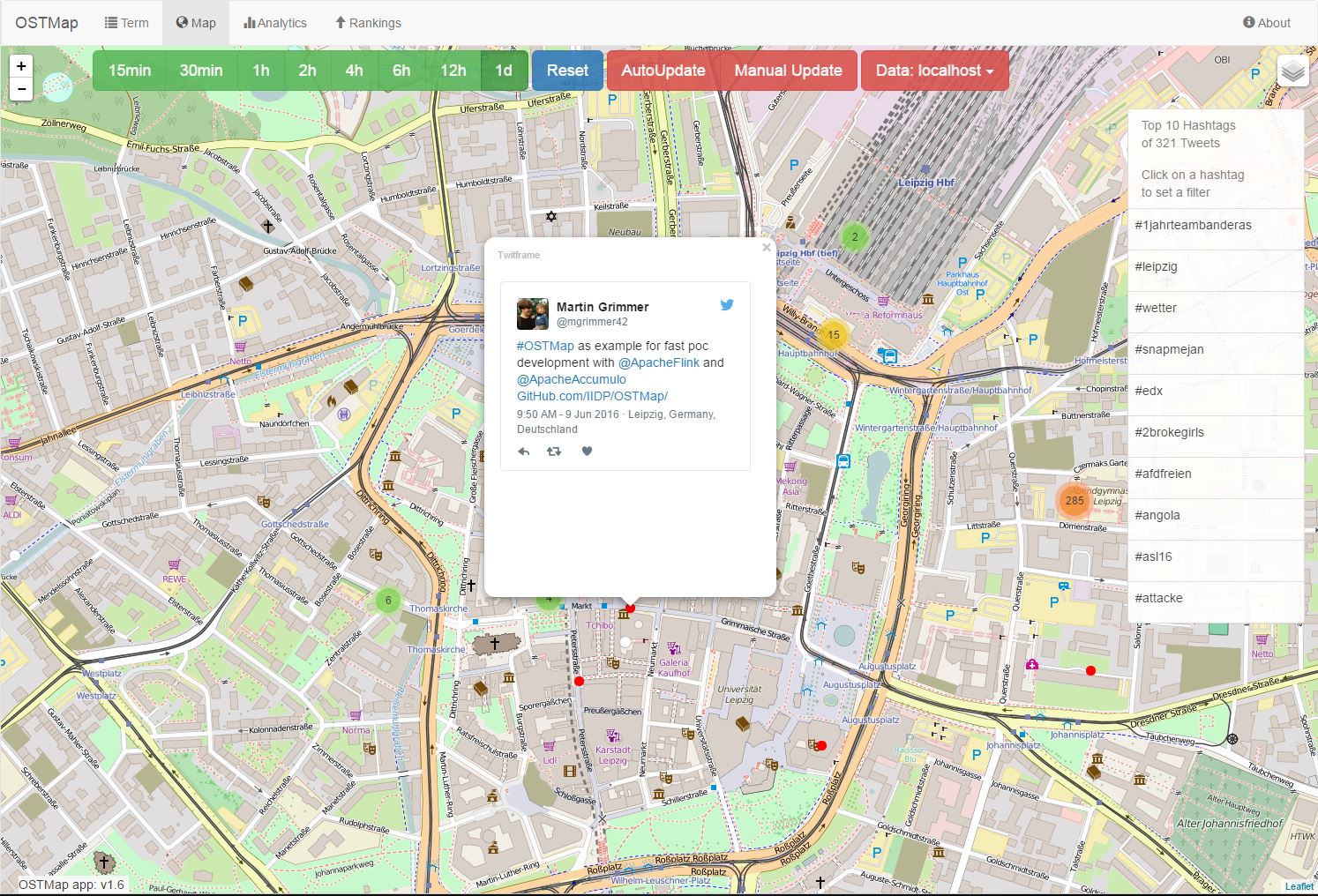
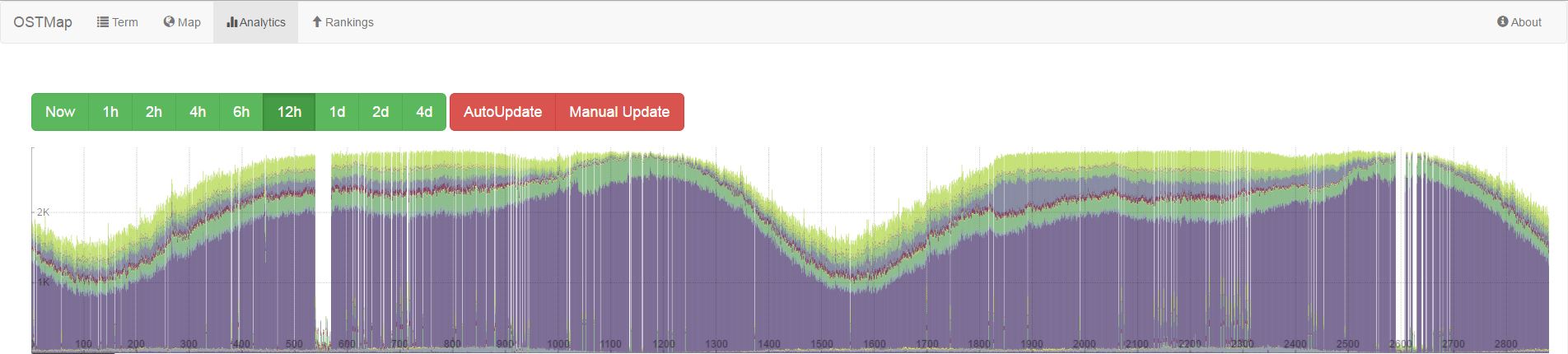
Demo of the map mode: http://ostmap.scads.uni-leipzig.de/#/map
- we use Apache Flink as computation framework for stream and batch processing
- we use Apache Accumulo as storage
- Spring Boot for restservices
- AngularJS, Bootstrap and Leaflet for the frontend
- stream_processing
- the stream processing app - reads the twitter stream and writes the raw data, the index and calculated results to accumulo
- batch_processing
- batch jobs over the complete dataset
- commons
- common code used by other submodules
- accumulo_iterators
- custom iterators for querying accumulo
- rest_service
- a spring boot application serving the ui and the rest services used by the ui
- Sentiment Analysis
- Sentiment analysis aims to determine the attitude of a tweet with respect to some topic. It should detects a positive, negative or neutral attitude of a tweet.
- supports stream as well as batch processing
- IT-Ringvorlesung 2016 at university of Leipzig
- industry partner for this project: mgm tp
- for information regardning development see: wiki
- for issues see: issues
- for our milestones see: milestones
- to compile/shadowJar a subproject f.eg. execute "gradle shadowJar -p batch_processing"
- both, the stream process and the batch process needs to be a fat jar for flink -> gradle shadowJar
- the rest service is build with spring boot -> gradle build
Apache License Version 2.0, see LICENSE file