How mrjob works
This is a brief walkthrough of the mrjob codebase. It's aimed primarily at mrjob maintainers and contributors, but should also be useful for anyone trying to debug an issue with mrjob.
mrjob lets you describe a job in Python, and then helps you run it on Spark or Hadoop Streaming, as painlessly as possible. Some pain points that mrjob relieves are:
- dealing with Elastic MapReduce and other cloud services; for example creating temp space on S3, setting up IAM instance profiles and service roles, and dealing gracefully with throttling by the EMR API
- making sure job can access libraries and other files it depends on, and that they are correctly initialized (e.g. running
make) - if your job fails, helping you dig the error out of logs
In mrjob, jobs are always a subclass of the MRJob class (found in mrjob/job.py). Jobs do three things:
- read arguments from the command line
- set up a runner and tell it to run the job
- run inside Spark or Hadoop Streaming
A mrjob script is just a Python file containing a definition of a MRJob subclass, and a small snippet of code at the end ensuring that if you run the script, the run() method on that subclass gets called.
For example, take a look at mrjob/examples/mr_spark_wordcount.py. We could run the script like this:
python mr_spark_wordcount.py -r emr -v --image-version 5.10.0 input1.txt input2.txtHere's what would happen in the code:
A code snippet at the bottom of mr_spark_wordcount.py would call MRSparkWordcount.run(), which would itself constructs an instance a MRSparkWordcount (let's call it self).
(All these methods are defined in the base MRJob class; trace through the code in mrjob/job.py.)
The MRJob constructor itself sets up an self.arg_parser and then calls self.configure_args(), which updates self.arg_parser, and self.load_args(), which puts the command-line arguments into self.options.
(Our subclass of MRJob doesn't redefine configure_args() or load_args(), but it's fairly common to do so, especially to add custom command-line switches.)
Next, the run() method calls execute() on the job we just constructed. execute() itself calls self.run_job(), which makes use of the command line arguments to set up the runner.
In this case:
-
-vmeans to use verbose logging (self.options.verbose = True) -
-r emrmeans to run on Elastic MapReduce (self.options.runner = 'emr') -
--image-version 5.10.0means something specific to Elastic MapReduce, in this case, using AMI version 5.10.0 (self.options.image_version = 5.10.0).
self.run_job() first sets up logging:
self.set_up_logging(verbose=self.options.verbose, ...)and then calls self.make_runner(), which uses the command-line options and some knowledge about the job to construct a runner like this:
runner = EMRJobRunner(
image_version=5.10.0,
mr_job_script=/path/to/mrjob/examples/mr_spark_wordcount.py,
stdin=sys.stdin,
steps=[{'jobconf': {}, 'spark_args': [], 'type': 'spark'}],
...
)If you want to dig deeper in the code, EMRJobRunner is chosen by self._runner_class(), and its constructor arguments are chosen by self._runner_kwargs().
In particular, steps comes from self._steps_desc(), which just boils the result of self.steps() down into a simple JSONable format.
Some MRJobs re-define self.steps(), but in this particular case, our job (see mrjob/examples/mr_spark_wordcount.py) just re-defines self.spark(), resulting in a one-step job with a step of type 'spark'.
Finally, run_job() calls runner.run(). In this case, it also prints the results of the job to standard output. We could have repressed this by calling the job with -o s3://bucket/path or --no-cat-output.
Note that MRJobs don't have to run themselves. You can also farm out setting up logging and parsing command-line arguments to an external script, which would then need to do something like this:
job = MRYourJob(args=[...])
with job.make_runner() as runner:
runner.run()
for k, v in job.parse_output(runner.cat_output()):
...If you look at the code, this is actually pretty similar to what self.run_job() does.
We'll get into more of what runner.run() does below, but the gist of it is that it copies mr_spark_wordcount.py (and our input files) into our Spark cluster on EMR, and then calls it with --step-num=0 --spark and the paths of our input files:
spark-submit ... s3://bucket/path/mr_spark_wordcount.py --step-num=0 --spark s3://bucket/path/to/tmp/input1.txt,s3://bucket/path/to/tmp/input2.txt s3://bucket/path/to/tmp/output/Spark will call our script once with the command-line arguments above. The resulting process is called the Spark driver.
The code path for the driver is the same as above (refer back to mrjob/job.py, except now when we get to self.execute() it notices the --spark switch (self.options.spark = True) and instead of calling self.run_job(), it calls self.run_spark(step_num=0). self.run_spark() then calls the spark() method defined in mrjob/examples/mr_spark_wordcount.py with our input and output paths:
self.spark(
's3://bucket/path/input1.txt,s3://bucket/path/input2.txt',
's3://bucket/path/output/'
)At this point, our spark() method creates a SparkContext, and with the help of the pyspark library, creates several copies of itself that run different bits of code on different bits of data.
With Hadoop Streaming jobs, there is no pyspark to help us out, so mrjob is responsible for a bit more of the legwork; there's an example below.
The runner is responsible for getting your job into Spark or Hadoop Streaming and making it run. Runners are always a subclass of MRJobRunner (see mrjob/runner.py).
Runners do three things:
- ship files to Spark or Hadoop
- construct command lines to run
- launch and monitor the job
Unlike with jobs, you don't have to define your runner class; mrjob picks one based on your command line arguments. For example, -r emr corresponds to EMRJobRunner in mrjob/emr.py.
Also unlike jobs, runners only run on the local machine where you launch your job. A runner may handle uploading files to HDFS or S3, or talking to the EMR API, but it ultimately up to Hadoop or Spark to run your job.
Here's what happens in the code when runner.run() is called:
One of the most helpful things mrjob does is make sure the files you need to run your job are where Spark or Hadoop Streaming needs them. These may include:
- your mrjob script (in this case mr_spark_wordcount.py)
- a copy of the MRJob library
- files specified in your job definition (e.g. with
add_file_arg()or theFILESattribute) - files specified on the command line
- files needed by bootstrap or setup scripts (more about that below)
For example, to run our job in the cloud on EMR, we not only have to instruct EMR to place mr_spark_wordcount.py and a copy of mrjob where Hadoop or Spark can see them, we also have to put a copy of these files somewhere on S3 so EMR can see them.
The MRJobRunner's run() method (in mrjob/runner.py) is where to start when tracing the code. Many of the details are handled by each runner subclass's _run() method (note the underscore). These are all a bit different, but there are some important commonalities.
Most jobs need certain files to appear in the working directories of their tasks (Hadoop) or executors (Spark).
As far as Hadoop and Spark are concerned, there are basically two kinds of things you might want to make available to your job: files (which are basically any type of file, but just one), and archives, which start life as tarballs but get unpacked as directories inside Hadoop and Spark.
Both files and archives are tracked by self._working_dir_mgr, which is defined for all runners, and is an instance of WorkingDirManager (also defined in mrjob/setup.py). WorkingDirManager is essentially a map from the paths or URIs of files to the name they should have in the working directory. It also takes care of finding unique names for files, and tracks whether they should be treated as files or archives.
Files get added to self._working_dir_mgr all over the code, generally at the point that they are first created or identified. For example, on most runners, we create a copy of the mrjob library (self._create_mrjob_zip(), defined in mrjob/bin.py) and then immediately add it to the relevant runner. This can look a bit like "spaghetti code", but it allows us to separate tracking files (by adding them to the appropriate manager) from uploading them.
Occasionally, you will see other WorkingDirManagers in the code. For example in EMRJobRunner, we also have self._bootstrap_dir_mgr and self._master_node_setup_mgr. For now, just know that these are doing the exact same thing (tracking files and archives to ship into a working directory), just for other sorts of tasks (e.g. bootstrapping the cluster).
In addition to files and archives, MRJob also supports dirs, which are just archives that MRJob creates for you by tarballing existing directories. These are converted into archives in self._create_dir_archive(), called from self.run() (both of these are in mrjob/runner.py). From the point of view of the WorkingDirManager, dirs are just archives.
Hadoop can't actually "see" most files on your local filesystem when running the job; you have to upload them to HDFS first. Similarly, with EMR and other cloud services, you usually have to put local files into cloud storage (e.g. S3).
Uploading is handled by self._upload_local_files(), defined in mrjob/runner.py, and called by every runner that runs a job remotely.
Every runner that runs remotely defines self._upload_mgr, which is an instance of UploadDirManager, defined in mrjob/setup.py. An UploadDirManager is a lot like a WorkingDirManager, except that it doesn't distinguish between archives and files, and that it knows which directory (prefix) files are going to be uploaded to.
When _upload_local_files() is called, it just creates the directory and iterates through the contents of self._upload_mgr:
if self._upload_mgr:
self.fs.mkdir(self._upload_mgr.prefix)
log.info('Copying other local files to %s' %
self._upload_mgr.prefix)
for src_path, uri in self._upload_mgr.path_to_uri().items():
log.debug(' %s -> %s' % (src_path, uri))
self.fs.put(src_path, uri)Like with self._working_dir_mgr, self._upload_dir_mgr is referred to all over the code, wherever we create or identify a file that needs to be uploaded. Usually these methods have for_upload in their name. For an example, take a look at _add_job_files_for_upload() in mrjob/emr.py.
If you looked carefully at _add_job_files_for_upload(), you'd notice that it adds archives from the working dir manager to the upload dir manager, but not files:
for path in self._working_dir_mgr.paths('archive'):
self._upload_mgr.add(path)Why not?
The short answer is that files that are supposed to end up in the working directory are uploaded to a different directory, called the working directory mirror. This is handled by self._copy_files_to_wd_mirror() (defined in mrjob/runner.py), which is called by self._upload_local_files().
The long answer is that Spark is somewhat more limited than Hadoop when it comes to placing files in a job's working directory.
On Hadoop, when you place a file in a job's working directory, you can also specify a different name for it. On the command line, it's just a switch like this:
-files hdfs:///path/to/foo#bar
The #bar tells Hadoop that the hdfs:///path/to/foo should appear in the job's working directory with the name bar.
On Spark (unless you're running Spark on YARN, which is basically Hadoop), there isn't the ability to rename files. The best you can do is give the path or URI:
--files hdfs:///path/to/foo
And Spark will copy it into your job's working directory, with the same name.
What that means is if we're using (non-YARN) Spark, and you have a file named foo that you'd to like to be named bar in the job's working directory, there better be a copy of it named bar on HDFS or wherever you're pointing Spark to. This place is the working directory mirror.
Note that even though self._copy_files_to_wd_mirror() is called from _add_job_files_for_upload(), it actually works for remote files as well. For example, if you launched a Spark job from mrjob with --files hdfs://path/to/foo#bar, mrjob would actually copy that file (foo) to hdfs://path/to/wd-mirror/bar so that it'll have the right now in Spark.
For the sake of code simplicity, mrjob will create and manager a working dir mirror whenever you have to copy files to a remote location, even if you're not running a Spark job. It also creates a working directory mirror when running jobs on Spark locally, though it's a bit more selective about what gets copied into there (basically, just files that need to be renamed).
Why doesn't the working dir mirror contain archives? It turns out that (non-YARN) Spark doesn't support archives at all, so there's no value in placing them in the working dir mirror. That's why _add_job_files_for_upload(), above, added them to self._upload_mgr.
Once our files are tracked and uploaded, we need to tell Hadoop/Spark where to find them.
Let's return to our example, above. We ran this command line:
python mr_spark_wordcount.py -r emr -v --image-version 5.10.0 input1.txt input2.txtOn EMR, it creates a step with this definition:
{
'Jar': 'command-runner.jar',
'Args': [
'spark-submit',
'--conf',
'spark.executorEnv.PYSPARK_PYTHON=python',
'--conf',
'spark.yarn.appMasterEnv.PYSPARK_PYTHON=python',
'--master',
'yarn',
'--deploy-mode',
'cluster',
'--files',
's3://bucket/path/to/tmp/files/wd/mr_spark_wordcount.py',
's3://bucket/path/to/tmp/files/wd/mr_spark_wordcount.py',
'--step-num=0',
'--spark',
's3://bucket/path/to/tmp/files/input1.txt,s3://bucket/path/to/tmp/files/input2.txt',
's3://path/to/tmp/output/'
]
}which instructs EMR to run this command line on the cluster's master node:
spark-submit --conf ... --master yarn --deploy-mode cluster --files ... s3://bucket/path/to/tmp/files/wd/mr_spark_wordcount.py ...In this case, mrjob knows that EMR runs Spark jobs in cluster mode on the YARN master (that is, on Hadoop). mrjob is actually a bit overzealous here: it tells Spark to place our Spark script into executors' working directories, even though in the end it asks Spark to run the script directly from S3 (which you can do in cluster mode).
This command line is created by self._args_for_spark_step(), defined in mrjob/bin.py). This in turn calls various methods defined in the same module:
def _args_for_spark_step(self, step_num, last_step_num=None):
return (
self.get_spark_submit_bin() +
self._spark_submit_args(step_num) +
[self._spark_script_path(step_num)] +
self._spark_script_args(step_num, last_step_num)
)Some other switches that _spark_submit_args() could potentially add to the command line include:
- More
--confswitches, either from:- spark properties set with
--jobconf(e.g.spark.executor.memory) - environment variables set with
--cmdenv(like we do above forPYSPARK_PYTHON)
- spark properties set with
- An
--archivesswitch for archives that are meant to be uploaded to the working directory -
--py-files, for Python packages added (set with mrjob's own--py-filesswitch)
It's pretty common for mrjob to run Spark scripts with --py-files /path/to/mrjob.zip, ensuring they have access to a copy of the mrjob library. The only reason this doesn't happen on EMR is that we install a copy of mrjob on the cluster at bootstrap time (see below).
Finally, we need to actually run the job and wait until it finishes. On EMR this consists of four steps:
- a. create a cluster
- b. submit steps
- c. wait for the steps to finish
- d. parse logs if the job failed
For most runners, steps a and b are replaced by simply running a command (spark-submit ... or hadoop jar ...)
Running the command-line above will cause mrjob to make an EMR API call like this:
RunJobFlow(
Applications=[{'Name': 'Hadoop'}, {'Name': 'Spark'}],
BootstrapActions=[
{'Name': 'master', 'ScriptBootstrapAction': {'Path': 's3://bucket/path/to/tmp/files/b.sh', 'Args': []}},
],
Instances={'InstanceGroups': [...],
JobFlowRole='mrjob-...',
LogUri='s3://bucket/path/to/logs/',
Name='mr_spark_wordcount.user.timestamp',
ReleaseLabel='emr-5.10.0',
ServiceRole='mrjob-...',
Steps=[]
)Some things to note:
-
Applications: mrjob automatically determines we need to installSpark -
Instances: mrjob configures how many and what type of EC2 instances, based on user request -
LogUri: mrjob always requests logs be copied to S3 -
JobFlowRoleandServiceRole: if you don't configure these, mrjob takes care of setting IAM up for you -
ReleaseLabel: set based on our--image-version 5.10.0on the command line -
Steps: empty because we will do this later
Finally, BootstrapActions tell EMR to run a script on each host as root before running any steps. In this case, it's a script that installs mrjob, and it looks like this:
#!/bin/sh -x
set -e
# store $PWD
__mrjob_PWD=$PWD
if [ $__mrjob_PWD = "/" ]; then
__mrjob_PWD=""
fi
{
# download files and mark them executable
aws s3 cp s3://mrjob-35cdec11663cb1cb/tmp/mr_spark_wordcount.marin.20191204.222645.633132/files/mrjob.zip $__mrjob_PWD/mrjob.zip
chmod u+rx $__mrjob_PWD/mrjob.zip
# bootstrap commands
__mrjob_PYTHON_LIB=$(python3 -c 'from distutils.sysconfig import get_python_lib; print(get_python_lib())')
sudo rm -rf $__mrjob_PYTHON_LIB/mrjob
sudo unzip $__mrjob_PWD/mrjob.zip -d $__mrjob_PYTHON_LIB
sudo python3 -m compileall -q -f $__mrjob_PYTHON_LIB/mrjob && true
} 1>&2As noted above, bootstrap scripts have their own instance of WorkingDirMgr. Its contents become commands to download the file (aws s3 cp ...), and, for archives, to un-archive them as well (tar ...).
mrjob would then make an EMR API call like this:
AddJobFlowSteps(
JobFlowId='j-CLUSTERID',
Steps=[
{
'ActionOnFailure': 'TERMINATE_CLUSTER',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': [...]
},
'Name': 'mr_spark_wordcount.user.timestamp: Step 1 of 1'
}
]
)(We covered the contents of Args above.)
This step definition is created by self._build_step() in mrjob/emr.py.
mrjob makes repeated DescribeCluster and DescribeStep API calls every 30 seconds or so, until your step completes or fails, or the cluster gets shut down. You can trace through the code starting at self._wait_for_steps_to_complete() in in mrjob/emr.py
If the job completes successfully, run() is done. At that point, your MRJob class (or your own batch script) might call runner.cat_output().
Once your runner goes out of scope, runner.cleanup() will be called, causing temp directories to be deleted and so on. EMR will automatically shut down the cluster once it runs out of steps. (There is a way for mrjob to launch a cluster that EMR won't automatically shut down, but in that case, mrjob adds a special bootstrap script that shuts the cluster down after it's been idle for a certain number of minutes.)
One of the cool things about mrjob is that it's pretty good at finding the error when your job fails.
How the log parsing code works is a whole other topic, but essentially mrjob will very selectively download and parse logs from S3 (or, if possible, by SSHing into your cluster) until it finds the Python exception that probably caused the job to fail. (If it can't find one, it eventually gives up and prints a Java error instead.)
The entry point into log parsing is self._pick_error(), defined in LogInterpretationMixin in mrjob/logs/mixin.py.
Once mrjob is done parsing the logs, it'll throw a StepFailedException.
The examples above use a Spark job, but mrjob was actually originally was designed to work with Hadoop. Here are some other kinds of jobs that mrjob can run, and what they look like in terms of code and command lines.
Back in 2010 when mrjob was first released, there was no mainstream big data solution that used Python (Spark wasn't released until 2014). Instead, mrjob made use of Hadoop Streaming, a language-neutral solution.
Hadoop Streaming jobs generally operate on lines of data, which may be spread across multiple input files. A Hadoop Streaming job has no more than one mapper command, and no more than one reducer command. These commands take in lines through standard input, and output lines through standard output.
First data is divided up and the mapper command is run on each. Then the resulting lines are shuffled and sorted by key (which is just the part of the line before the first TAB character). Finally, the shuffled and sorted lines are divided up between reducers in such a way that all lines with the same key are adjacent and are processed by the same reducer.
Just as a Spark MRJob can run inside Spark, a MRJob designed for Hadoop streaming can serve as both mapper and reducer inside Hadoop.
As an example, let's MRWordFreqCount, a simple word frequency count job, in mrjob/examples/mr_word_freq_count.py:
class MRWordFreqCount(MRJob):
def mapper(self, _, line):
for word in WORD_RE.findall(line):
yield (word.lower(), 1)
def reducer(self, word, counts):
yield (word, sum(counts))The mapper() method is concerned with finding the words in a line. For example, a mapper fed "Go Dog, Go!" as an input line would emit: ("go", 1), ("dog", 1), ("go", 1).
The job of the reducer() method is to collect all the words and sum together their counts. For example, reducer() here will be called exactly once with word set to "go" and counts being a stream of 1s (at least two, plus some from other lines).
If you're reading the source code of the job, you may notice there is also a combiner() method. A combiner is essentially an optional mini-reducer that runs before the shuffle-and-sort step. Essentially, several mappers will process data on one node (one computer, basically), and the combiner can reduce the size of the data on that one node before shipping it off to others.
If you run mr_word_freq_count.py on EMR (or some other Hadoop cluster):
python mr_word_freq_count.py -r emr -v input1.txt input2.txtmrjob will construct a command line something like this:
hadoop jar /path/to/streaming.jar -mapper 'python mr_word_freq_count.py --step-num=0 --mapper' -combiner 'python mr_word_freq_count.py --step-num=0 --combiner' -reducer 'python mr_word_freq_count.py --step-num=0 --reducer' -files s3://bucket/path/to/tmp/mr_word_freq_count.py -input s3://bucket/path/to/tmp/input1.txt -input bucket/path/to/tmp/input2.txt -output s3://bucket/path/to/tmp/output/ Essentially, rather than our script being run with --spark, it's run as a mapper (--mapper), combiner (--combiner) and reducer (-reducer). And because of the way Hadoop Streaming works, our script literally gets run from start to finish many, many times across different nodes.
This command line to run Hadoop is created by self._hadoop_streaming_jar_args() in mrjob/bin.py. Most of the methods it calls are in that file as well.
When Hadoop Streaming runs your script with --mapper, run_mapper() in mrjob/job.py gets called, and it in turn runs your mapper method once for each line.
Similarly, when Hadoop Streaming runs your script with --reducer, run_reducer() gets called, and your reducer() method gets run once for each key. If you trace through the code, you'll see that mrjob ultimately uses itertools.groupby() to present all the values corresponding to one key as a stream of data.
From your MRJob's point of view, combiners work basically the same way as reducers (script gets called with --combiner, calls run_combiner()).
Unlike Spark, which is aware of Python data structures, Hadoop Streaming just operates on lines. So mrjob offers protocols to convert Python data structures to and from lines.
By default, the initial mapper receives the raw line, and from then on out, everything is encoded as JSON. You can change this by setting INPUT_PROTOCOL, OUTPUT_PROTOCOL, and/or INTERNAL_PROTOCOL to a protocol class in your MRJob class definition. You can see several protocols in mrjob/protocol.py; for example, you can use pickle instead of JSON.
Hadoop Streaming can run any command as a mapper or reducer, not just your MRJob script. You can leverage this by re-defining mapper_cmd() or reducer_cmd() (or for that matter, combiner_cmd()). For example, mrjob/examples/mr_grep.py does this. When you run the script, it'll make a command line like:
hadoop jar streaming.jar -mapper 'grep -e <expression>'Running a single mapper and reducer isn't all that useful for most tasks, so mrjob allows you to create multi-step jobs. From the point of view of Hadoop or Spark, these are just a series of jobs where the output directory of one step happens to be the same as the input directory of the next step.
To define a multi-step MRJob, you re-define self.steps(). For example, here's the steps() method for MRMostUsedWord (in mrjob/examples/mr_most_used_word.py):
def steps(self):
return [
MRStep(mapper_init=self.mapper_init,
mapper=self.mapper_get_words,
combiner=self.combiner_count_words,
reducer=self.reducer_count_words),
MRStep(reducer=self.reducer_find_max_word)
]MRStep is just the class that represents a Hadoop Streaming step; you can see other step classes (including SparkStep) in mrjob/step.py.
The command lines for multi-step jobs are constructed in exactly the same way, except that commands from the second step are run with --step-num=1 (so running mr_most_used_word.py
You might notice mapper_init=.... This is just a method that takes no arguments that runs once every time the mapper script is called; in this script we use it to load a file containing stop words.
It's possible to combine two different kinds of steps in a single job; for example, see mrjob/examples/mr_jar_step_example.py
By the way, if you don't redefine self.steps(), all that happens is that MRJob's default step method (see mrjob/job.py) checks which other methods have been re-defined and returns an array. For example, if you re-define mapper(), the default steps() method returns [MRStep(mapper=self.mapper, ...)].
Hadoop Streaming is actually just one of many JARs you can run. If you have good knowledge of Hadoop and Java, you can actually write your own JARs, which potentially run much faster.
If you define a MRJob with a JarStep, it just constructs a command line like hadoop jar your.jar <args>. It's also up to you to decide what, if any arguments your JAR receives. You can use the constants INPUT, OUTPUT, and GENERIC_ARGS to stand for the input files or directory, the output directory, and any generic Hadoop arguments (e.g. -D for configuration properties). Here's some example code from mrjob/examples/mr_jar_step_example.py that constructs a JarStep:
jar_step = JarStep(
jar='file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar',
args=['wordcount', GENERIC_ARGS, INPUT, OUTPUT],
)When mrjob runs a JarStep, it doesn't need to upload your MRJob script. If the JAR is a local file (not a URI as above), it will ensure that the JAR gets uploaded.
Similarly, spark-submit can run any Python script or Spark JAR, not just MRJob scripts. You can run a regular old Spark script by defining a SparkScriptStep, and similarly, you can run a Spark JAR by defining a SparkJarStep.
If all you want to do is run a Spark script on EMR or some other platform mrjob supports, you don't even need to make a script; you can just run mrjob spark-submit ... as a drop-in replacement for spark-submit (code for this is in mrjob/tools/spark_submit.py).
Hadoop Streaming jobs can set Hadoop input and output formats, in order to read input or write output in special ways.
For example, mrjob/examples/mr_nick_nack.py is basically a word frequency count job, but it sets HADOOP_OUTPUT_FORMAT = 'nicknack.MultipleValueOutputFormat' so that output is divided into separate directories based on the first letter of the word. It also sets LIBJARS to ensure that the JAR containing MultipleValueOutputFormat is automatically uploaded into Hadoop Streaming.
Sometimes you want to run a job that processes files rather than lines. MRJob makes this easy for you; just define mapper_raw() in your job (or make a step like MRStep(mapper_raw=...)) and it'll pass the path of a local copy of the file, and its URI on S3 or wherever it's stored.
For example, mrjob/examples/mr_phone_to_url.py uses this feature to parse WARC files, which encode webpages using a multi-line format.
What's going on behind the scenes is that the "input" that Hadoop Streaming sees is a list of URIs of files, and then it sets your script's Hadoop input format to NLineInputFormat, so that each mapper only receives the URI of one file.
Your script still gets called with --mapper --step-num=...; just run_mapper() does something slightly different when the script runs.
You can add your own custom switches to your job, and they'll get passed through to your script when it runs inside Spark or Hadoop.
For example, mrjob/examples/mr_text_classifier.py uses self.add_passthru_arg() to add a --min-df (document frequency) switch to the job:
def configure_args(self):
super(MRTextClassifier, self).configure_args()
self.add_passthru_arg(
'--min-df', dest='min_df', default=2, type=int,
help=('min number of documents an n-gram must appear in for us to'
' count it. Default: %(default)s'))
...Now, the commands that Hadoop Streaming runs will include --min-df (-mapper 'mr_text_classifier.py --mapper --step-num=0 --min-df=1) if you set it. This works with SparkSteps as well—one reason not to just write a regular Spark script.
You can also add special switches that take files as a single argument; if the file is on your local filesystem, mrjob will ensure that it gets uploaded into Spark or Hadoop. For example, mrjob/examples/mr_most_used_word.py uses this to upload a custom stop words file:
def configure_args(self):
super(MRMostUsedWord, self).configure_args()
self.add_file_arg(
'--stop-words-file',
dest='stop_words_file',
default=None,
help='alternate stop words file. lowercase words, one per line',
)So far we've only talked about running jobs on EMR. In addition to the EMR runner (in mrjob/emr.py), there are five others:
InlineMRJobRunner (in mrjob/inline.py) avoids launching subprocesses from Python, to make debugging easier. If you run a Hadoop Streaming job, it does its best to simulate a single-threaded version of Hadoop (it can't run Hadoop JARs though). If you run a Spark job, it actually runs your job through the pyspark library.
If you don't specify the -r flag, this is the runner you get by default, on the assumption that you'd probably rather debug your job before running it on a cluster.
LocalMRJobRunner (in mrjob/local.py) is like InlineMRJobRunner, except that it launches subprocesses. When running Hadoop Streaming jobs, it's essentially a poor man's Hadoop; it uses all your CPUs, but has no error recovery. In addition, when launching a Spark job, it uses a local-cluster[...] Spark master, which is a better way to test out complex jobs locally.
The Hadoop runner (in mrjob/hadoop.py) is designed to work with your own Hadoop cluster. If the hadoop binary is in one of about six standard places, it'll find it and start launching hadoop jar and hadoop fs commands (for HDFS). It runs Spark as well, assuming by default you'll want to use the yarn master and HDFS.
SparkMRJobRunner (in mrjob/spark/runner.py) always launches jobs spark-submit. What's cool about this runner is that it can run Hadoop Streaming jobs as well, but it runs them in Spark! (More below about the magic behind this.)
The Spark runner is, like Spark, agnostic about filesystems, and supports any filesystem supported by mrjob (local, HDFS, S3, or Google Cloud Storage).
DataprocJobRunner (in mrjob/dataproc.py) is like EMRJobRunner, except that instead of working with Amazon's Elastic MapReduce, it runs jobs on Google Cloud Dataproc.
Unfortunately, DataprocJobRunner does not yet support Spark.
Here's what the entire runner class hierarchy looks like:
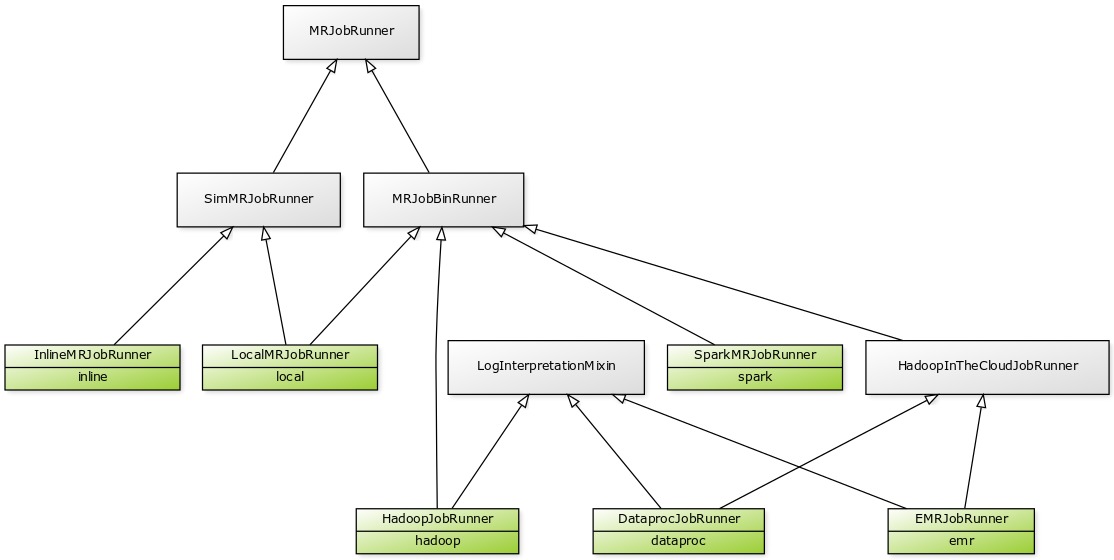
If you're trying to make a change to runner code, here's a rough guide to where to look:
BinMRJobRunner (in mrjob/bin.py) contains the bulk of shared runner code that involves launching subprocesses or creating command lines. Basically, if every runner but InlineMRJobRunner needs a certain feature, you'll find it here.
Code common to all runners is found in the base MRJobRunner class (in mrjob/runner.py).
SimMRJobRunner (in mrjob/sim.py) contains nearly all the code that powers -r inline and -r local. This handles running mappers and reducers, setting up fake Hadoop working directories and configuration properties, etc.
LogInterpretationMixin (in mrjob/logs/mixin.py) handles downloading and parsing logs created by the job. Note that SparkMRJobRunner doesn't inherit from LogInterpretationMixin because it only parses the output of the spark-submit command, which it parse directly with other code in mrjob/logs/.
HadoopInTheCloudJobRunner (in mrjob/cloud.py) contains some code that's specifically useful for cloud services (launching clusters, SSHing in, etc.). There is doubtless still some common code between EMRJobRunner and DataprocJobRunner that could be pushed up into this class but hasn't yet been.
Every runner instance has an fs property that allows it to perform filesystem operations. For example, an EMRJobRunner's fs can talk to both the local filesystem and S3.
mrjob's filesystem is a bit limited, as it basically only supports operations used by the library. So, for example, there are ls(), cat(), and put() methods, but no get() or cp(). Runners use their own filesystems fairly often; just grep the mrjob source code for self.fs.
The full filesystem interface is defined in Filesystem (in mrjob/fs/base.py). As a rule, nearly every filesystem method that reads from the filesystem is recursive and supports globbing.
Various filesystems are defined in in mrjob/fs/s3.py, with one module per filesystem. For example, S3Filesystem is in mrjob/fs/s3.py.
Runners' fs property is always a CompositeFilesystem, defined in mrjob/fs/composite.py.
Each CompositeFilesystem instance has a list of sub-filesystems (added with add_fs()). Each sub-filesystem has a can_handle_path() method that takes a URI or local filesystem path, and returns whether that filesystem can handle it. For example, the S3Filesystem can handle URIs that start with s3://, s3a://, or s3n://, but not paths or other types of URIs.
The CompositeFilesystem handles methods in the base Filesystem interface by simply going thorough its list of filesystems until it finds one where can_handle_path() is True, and then passes the method call through to that filesystem.
Filesystems can have their own methods not defined in the base interface (for example, S3Filesystem has a get_bucket() method), but they are not passed through by CompositeFilesystem. Instead, CompositeFilesystem allows you to access each sub-filesystem directly by name, for example: runner.fs.s3.get_bucket().
CompositeFilesystem has a teeny bit of magic that allows it to permanently disable a sub-filesystem if it turns out that it's not set up. For example, SparkMRJobRunner would like to use S3Filesystem to handle s3:// URIs if S3 credentials are properly set up, but if not, it would fall back to the HadoopFilesystem. To see how this is set up, search for def fs in mrjob/fs/spark/harness.py.
As noted above, the mrjob library is older than Spark. What are users supposed to do with their old Hadoop Streaming MRJob scripts if they migrate to a Hadoop-free Spark solution, such as Spark on Mesos?
Hadoop Streaming MRJob scripts are essentially just a description, in Python, of how to transform data. It turns out that everything you can do in Hadoop Streaming, you can also do in Spark.
When SparkMRJobRunner wants to run a Hadoop Streaming job, the Spark script it actually runs is mrjob/spark/harness.py, which we call the Spark harness. This script just needs to know the name of your MRJob class, and simplified JSON version of your job's steps, which SparkMRJobRunner passes through as part of harness.py's command line.
At this point the harness calls your job's mappers, reducers, etc. It doesn't actually call run_mapper(), but instead calls map_pairs() a method that run_mapper() calls (see mrjob/job.py). Similarly, there are reduce_pairs() and combine_pairs().
As magical as it is, the source code for mrjob/spark/harness.py is pretty straightforward; it's only long because it covers nearly every edge case needed by real MRJobs.
The main thing that's tricky is that Hadoop's concept of a reducer is much more heavyweight than Spark's, so we actually use rdd.mapPartitions() to simulate reducers. Hadoop's combiners are a better fit for Spark's lightweight paradigm, so there's a special code path (using rdd.combineByKey()) to make use of combiners if they're defined.
In general, Hadoop Streaming MRJobs tend to run faster in the Spark harness than in actual Hadoop Streaming. Hadoop Streaming retains two main advantages:
- it can run arbitrary commands (e.g.
grep). (Spark probably could do this, but then we'd be literally turning Spark into Hadoop Streaming.) - it has no limit on reducer size. In Hadoop Streaming, all the values for one reducer key go into a file, and as long as your job doesn't load them all into memory, it can handle arbitrarily many. In contrast, Spark is all about loading stuff into memory, so if you have a particularly "lumpy" dataset, Spark may choke on it before your code gets to run.
It can sometimes be useful to be able to run another command immediately before running a Spark or Hadoop Streaming task. For example, you might want to make your source tree. Or, if you were feeling more ambitious, you could set up a Docker container for your task to run inside—if you can write it as a shell script, you can do it.
mrjob uses setup scripts to make this happen. Setup scripts are just shell scripts that take the place of command line Hadoop Streaming or Spark is trying to run. Since the scripts eventually run the original command, Hadoop/Spark is none the wiser.
Setup scripts are made up of setup commands, which are just snippets of shell where # has a special meaning, similar to Hadoop's distributed cache syntax. For example, you could upload your source tree into the job's working directory and run make on it by running your job with:
--setup 'make -C /path/to/src-tree.tar.gz#src-tree/'For full details about setup script syntax, look at the setup docs in the mrjob documentation. If you want to see the code that parses setup commands, look at parse_setup_cmd() in mrjob/setup.py.
Setup scripts come in three flavors: Hadoop Streaming, Hadoop Streaming with input manifest, and Spark
This is the original flavor of setup script. mrjob creates a script called setup-wrapper.sh, and prepends it to the command line for your mapper, reducer, etc. So the -mapper argument to your Hadoop Streaming command would look something like:
-mapper 'sh -ex setup-wrapper.sh python mr_your_job.py --mapper ...'mrjob would also be responsible for ensuring that src-tree.tar.gz and the wrapper script itself get uploaded into the working directory, meaning that Hadoop Streaming command would also contain:
-archives /path/to/src-tree.tar.gz -files /path/to/setup-wrapper.shIf a job has an input manifest (see mapper_raw() above), it's the setup script that's responsible for downloading a local copy of the file that a task is supposed to run on. This script is named manifest-setup.sh.
The Hadoop Streaming command line looks the same, but the end of the wrapper script is different. It first reads a single line containing the URI of the input file ($INPUT_URI), and then runs a command to download the file to a temporary location ($INPUT_PATH), uncompressing it if necessary. It then calls your task with two extra arguments, $INPUT_PATH and $INPUT_URI.
Look at _manifest_download_content() in mrjob/bin.py to see how this part of the script is generated.
Unlike Hadoop Streaming, Spark cannot be made to run arbitrary commands. However, it does invoke Python, and so to get the effect of a setup script, we merely need to tell Spark that our wrapper script is the Python binary by setting $PYSPARK_PYTHON to point at it.
To see how we do this, look at _spark_cmdenv() in mrjob/bin.py. Spark setup wrapper scripts are named python-wrapper.sh, so the resulting spark-submit command line looks the same except that it contains:
--conf spark.executorEnv.PYSPARK_PYTHON=python-wrapper.shmake was actually the original use case for setup scripts. In Hadoop Streaming, unpacked archives are actually shared between tasks on the same machine, so if multiple tasks ran make simultaneously, it could cause an error.
We fixed this by adding file locking, so no two setup scripts could run at the same time on the same machine. The resulting setup script to run make looks something like this:
# store $PWD
__mrjob_PWD=$PWD
# obtain exclusive file lock
exec 9>/tmp/wrapper.lock.mr_your_script.unique_job_id
/Users/marin/git/venv-3.7-mrjob/bin/python -c 'import fcntl; fcntl.flock(9, fcntl.LOCK_EX)'
# setup commands
{
make -C $__mrjob_PWD/src-tree
} 0</dev/null 1>&2
# release exclusive file lock
exec 9>&-
# run task from the original working directory
cd $__mrjob_PWD
"$@"The above shell script is generated by _setup_wrapper_script_content() in mrjob/bin.py, which is called by _write_setup_script() (same module).
This same code path is actually used for all three setup script types. See _create_setup_wrapper_scripts() (also same module) to see the various ways _write_setup_script() is called.
An extremely common use of setup scripts is to get a copy of the mrjob library into your Spark/Hadoop task's $PYTHONPATH. This results in an additional command in your setup script:
export PYTHONPATH=$__mrjob_PWD/mrjob.zip:$PYTHONPATHThe way this works is that _py_files() in mrjob/bin.py calls _create_mrjob_zip() (same module) and appends it to the list of files it returns (which comes from running your job with something like --py-files lib1.zip,lib2.egg).
_create_setup_wrapper_scripts() calls _py_files_setup() (both of these are also in mrjob/bin.py). _py_file_setup() might look a bit complex, but it's essentially adding a parsed version of:
export PYTHONPATH=mrjob.zip#:$PYTHONPATHto the list of setup commands.
Cluster pooling is a feature that allows mrjob to re-use the same cluster for a different job if the cluster has a similar-enough setup.
This feature was added to mrjob back when AWS billed by the full hour. So, for example, if you spun up a cluster and ran a job for 20 minutes, you might as well have left the cluster running for another 40 minutes for other jobs to use, since you already paid for that time.
Now that AWS bills by the second, pooling is mostly useful as a way of getting around waiting for a cluster to provision and bootstrap. This is great for development (low latency) but not so useful for production (wastes money).
Pooling is somewhat of a nuisance to maintain, as every new EMR feature can potentially affect whether a cluster launched for one job is appropriate to use for another. To make things even more interesting, sometimes a cluster can be "better" than another one because it offers more CPU or memory (and an otherwise identical setup).
For details about how pooling works from a user perspective (e.g. which aspects of configuration affect pooling), check out Cluster Pooling in the mrjob docs.
The main place pooling comes into play in the mrjob code is from _launch_emr_job() in mrjob/emr.py. If self._opts['pool_clusters'] is true, we call self._find_cluster() (same module), which looks at idle clusters to see if any are suitable for the job.
Some information about a cluster (e.g. image version) is available from the EMR API. Other information (such as the contents of files used in bootstrapping) is not; this information is rolled into a hash created by self._pool_hash() and attached to the cluster as a tag in self._create_cluster().
Because it's expensive to run a cluster forever, every cluster used in pooling has a special daemon added at bootstrap time that checks YARN to see if any jobs are running, and if none have for a certain amount of time (by default, 10 minutes), calls sudo shutdown -h now. The daemon is quite reliable, but it leaves open the possibility of a race condition:
- job selects a pooled cluster to submit to and adds steps through the EMR API
- before those steps are actually added to YARN, the daemon on that cluster shuts it down
- the job fails because its cluster shut down unexpectedly
To get around this race condition, mrjob is able to detect when a pooled cluster self-terminated and re-launch the job. If this happens, self._wait_for_step_to_complete() raises a _PooledClusterSelfTerminatedException, which is caught by self._finish_run(), causing it to call self._relaunch().
To learn more about how pooling fits into the mrjob code, grep for 'pool_clusters'.