[TOC]
本项目旨在实现一个高并发内存池,参考了Google的开源项目tcmalloc实现的简化版本。
TinyTcMalloc的功能主要是实现高效的多线程内存管理。由功能可知,高并发指的是高效的多线程,而内存池则是实现内存管理的。
i7-4790k、Windows10专业版、Visual Studio 2022 Community
该项目要求读者掌握C/C++、数据结构(链表和哈希桶)、操作系统中的内存管理、单例设计模式、多线程以及互斥锁相关知识。
-
池化技术
池化技术是指程序预先向系统申请过量的资源,并对这些资源进行合理管理,避免需要使用频繁的申请和释放资源导致的开销。
常见的池化技术应用还有数据结构池、线程池、对象池、连接池等,读者可自行了解。
-
内存池
内存池指的是程序预先向操作系统申请足够大的一块内存空间;此后,程序中需要申请内存时,不需要直接向操作系统申请,而是直接从内存池中获取进行使用;同理,程序释放内存时,也不是将内存直接还给操作系统,而是将内存归还给内存池,以备下次被程序申请使用。当程序退出(或者特定时间)时,内存池才将之前申请内存池中的全部内存真正释放。
-
内存池主要解决问题
- 内存池主要解决的是频繁的内存分配和释放操作所导致的效率问题和内存碎片(不了解的可以参考浅谈内存碎片)问题。传统的内存分配方式每次都需要向操作系统申请一块内存,而释放内存时也需要向操作系统归还内存。这种方式存在以下问题:
- 内存分配和释放操作的开销比较大,需要耗费一定的时间和资源,会影响程序的性能;
- 由于内存分配和释放不可控,可能会导致内存碎片问题,降低内存的使用效率;
- 内存泄漏问题,由于程序无法确定何时需要释放内存,可能导致内存泄漏和资源浪费问题。
内存池通过预先分配一块内存池,并且把内存池分成多个大小相等的内存块,每次从内存池中取出内存块使用,使用完后再归还给内存池,这样就可以 避免了频繁的内存分配和释放操作。同时,内存池还可以提高内存的使用效率,避免内存碎片问题的发生,而且还可以避免内存泄漏问题。
- 内存池主要解决的是频繁的内存分配和释放操作所导致的效率问题和内存碎片(不了解的可以参考浅谈内存碎片)问题。传统的内存分配方式每次都需要向操作系统申请一块内存,而释放内存时也需要向操作系统归还内存。这种方式存在以下问题:
-
malloc解析
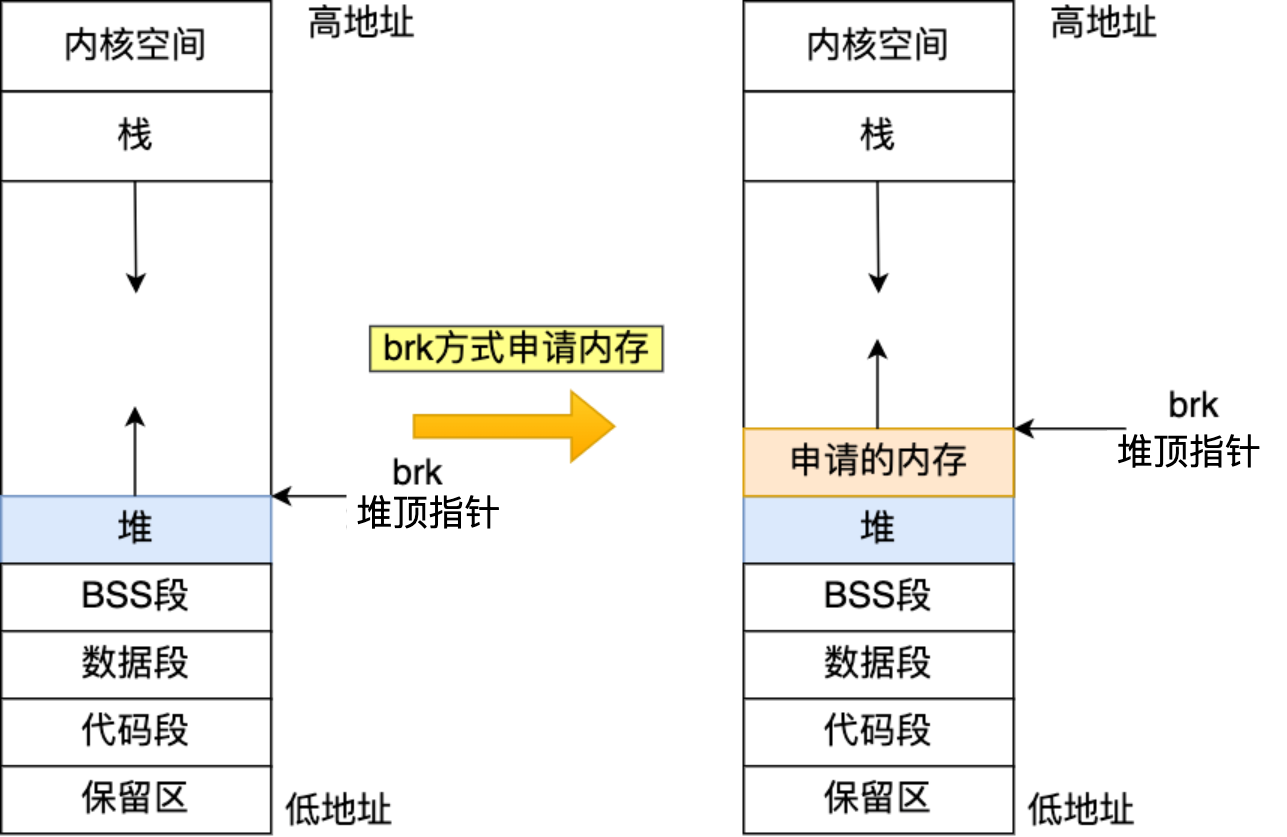
实际上,malloc函数属于C语言的库函数,并非是系统调用。当我们使用malloc函数动态申请内存时,malloc函数会根据程序申请的内存大小(一般以128k为分界线)选择调用brk()系统调用在堆区申请内存或者mmap()系统调用在文件映射区申请内存。偷一下懒,这里放一下小林coding的示意图:
malloc函数适用于各种场景下的内存分配任务,但是通用往往意味着各方面都不够完美,比如malloc函数在频繁进行小块内存分配和释放的场景下往往会具有较高的内存调用开销和内存碎片化问题,该项目设计一个定长内存池来优化特定内存申请效率(Note:内存池技术不适用需要大量申请大块内存的场景)。
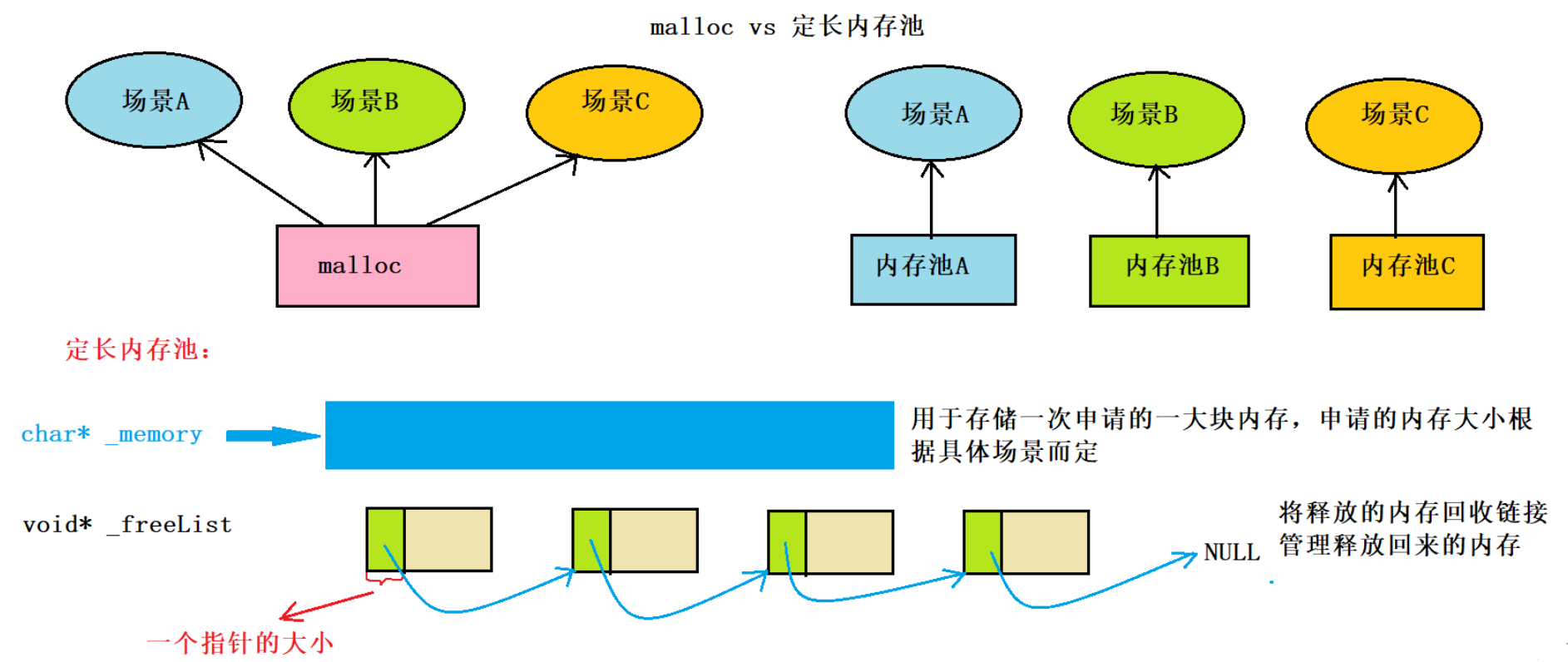
本项目需要选取一块对象内存的前n个内存(32位系统n=4,64位系统n=8)来存放指向下一块释放回来的自由对象内存的指针,为了实现代码的平台通用性,我们可以将对象内存强制转换成__void**__类型,再对这个二级指针解引用即可取出我们需要的当前对象内存的前n个内存。该技巧的核心思想是利用编译器对不同类型在内存中占据空间的大小进行处理,对象内存的地址强制类型转换成__void**__类型,这样就相当于把该对象的地址存放在了一个8个字节(64位系统)或者4个字节(32位系统)的内存单元中。
该操作在本项目中会被频繁使用,为了提高调用执行效率,将其封装成内联函数方便调用:
// 内存指针转换 4/32位 8/32位
static inline void*& NextObj(void* obj) {
return *(void**)obj;
}C/C++中申请内存一般使用malloc/new,本项目为了脱离使用malloc函数,直接将Windows操作系统提供的虚拟内存申请系统调用函数VirtualAlloc封装成自己的内存申请函数:
// 自定义内存申请函数
inline static void* SystemAlloc(size_t kPage)
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kPage << PAGE_SHIFT, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
//Linux下brk mmap等
#endif // _WIN32
//抛出异常
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}简单介绍一下VirtualAlloc函数:
LPVOID VirtualAlloc( LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect );其中:
- lpAddress:指定欲保留或提交页面的起始地址。如果为0,则表示让系统决定;如果非0,则要求系统从这个地址开始分配给这个进程。
- dwSize:欲提交或保留的内存大小,单位是字节。
- flAllocationType:内存分配类型标志位,包含以下几个值之一:
- MEM_COMMIT:提交已经被保留的内存页,此时内存内容已经被清空。
- MEM_RESERVE:保留指定大小的虚拟地址空间而不进行物理存储分配。一旦保留了地址空间,就可以在后续的操作中执行提交操作(即将保留的内存页提交,使其与物理存储关联),也可以取消保留操作,释放掉相应的地址空间。
- flProtect:要应用于保留或提交的内存页所需的访问权限和页面属性(例如读、写、执行等),支持一系列参数,如 PAGE_READWRITE 表示可读可写,PAGE_EXECUTE 表示可执行,PAGE_EXECUTE_READ 表示可读可执行等。
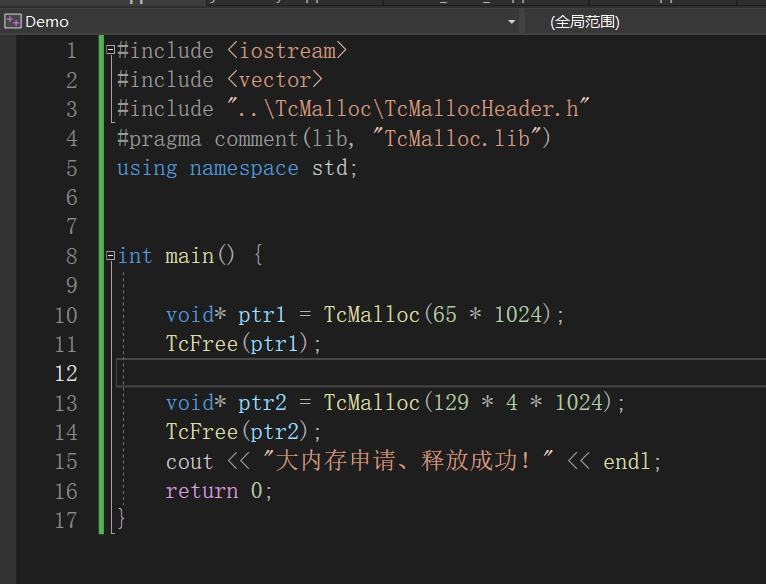
基于以上的内容,我们实现了我们的定长内存池,代码和测试代码点击下方链接获取:
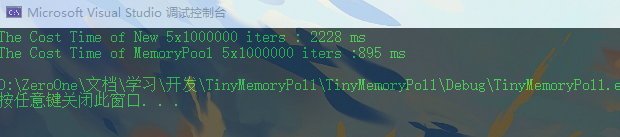
测试5000000次申请和释放内存结果如下,我们可以看出,使用定长内存池的代码效率要高于new(malloc)函数:
PageCache使用STL容器中的unordered_map来构建<_pageID,span>映射时,我们发现TcMalloc内存池的内存分配和释放效率要低于直接使用malloc和free函数,使用4个线程并发执行10轮,每轮执行申请并释放10000次(执行过程:申请16->申请1024->释放16->释放1024)进行性能测试,测试结果如下图所示:

1.点击vs工具栏的调试,打开该工具目录下的性能探查器
2.选择性能探查器下的检测选项,以监测应用程序相关函数的调用次数和调用时间,并点击下方的开始,开始监测
3.等待监测运行结果并分析
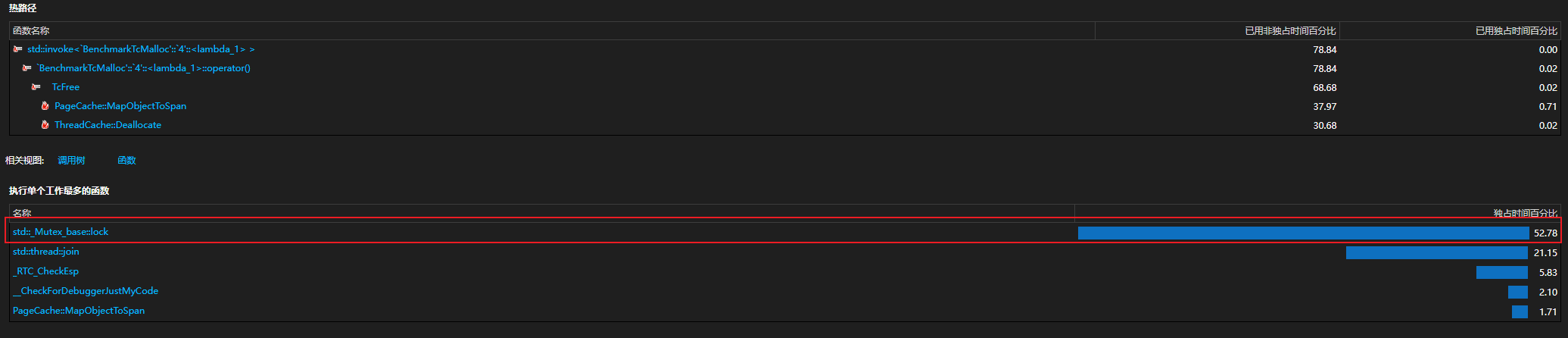

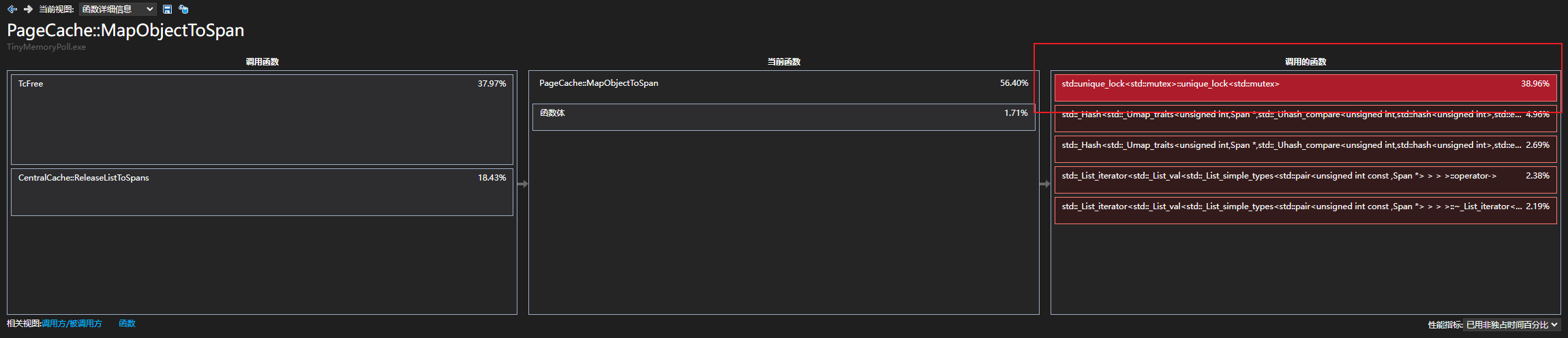

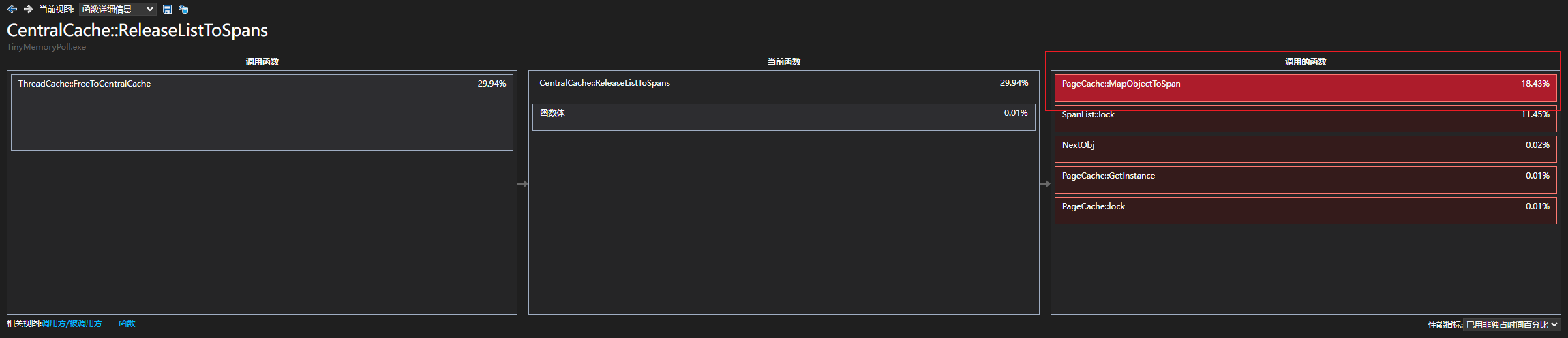

4.通过解析程序的执行过程,我们发现,为了保证操作的原子性,项目在unordered_map<PAGE_ID, Span*> _idSpanMap中的锁竞争上浪费了大量性能,这主要是因为unordered_map是线程不安全的,因此多线程下使用时需要加锁,防止使用<_pageID,span>映射时其他线程对映射造成修改,改变哈希桶结构而造成数据不一致,而<_pageID,span>映射会被多次使用到,大量加锁、解锁操作会导致资源的消耗。
为了突破<_pageID,span>映射大量锁操作带来的性能瓶颈,本项目参考google开源的tcmalloc,使用基数树进行优化。对基数树还不了解的小伙伴可以先看这篇博客:图解基数树(RadixTree)。
使用基数树为什么可以不用加锁?
之前使用unordered_map时可能有的线程在建立映射,有的线程在使用MapToSpan()进行读取(必须加锁)
- 若使用set,底层是红黑树:遍历时如果正好在进行旋转(左右旋),映射关系发生变化,出错
- 若使用unordered_map, 底层是哈希桶,遍历时刚好在进行扩容或插入删除,桶也变了,错误
而使用基数树:
- 插入时不会动结构,在写之前会提前开好空间(红黑树或哈希桶会动结构)
- 只有两个函数
FetchNewSpan和ReleaseSpanToPageCache会使用_pageMap建立映射,多个线程不可能对同一个位置进行写(调用这两个函数时已加锁)- 读写是分离的,不可能读的时候在写
由于项目使用的环境是32位编译系统,故只需要使用一层/两层基数树进行映射,只有在64位系统下才需要使用三层基数树,分别测试一层/两层基数树优化后的结果。
使用4个线程并发执行10轮,每轮执行申请并释放2000次(执行过程:申请16->申请65*1024->释放16->释放65*1024)进行性能测试,测试结果如下图所示:
- 单层基数树优化结果
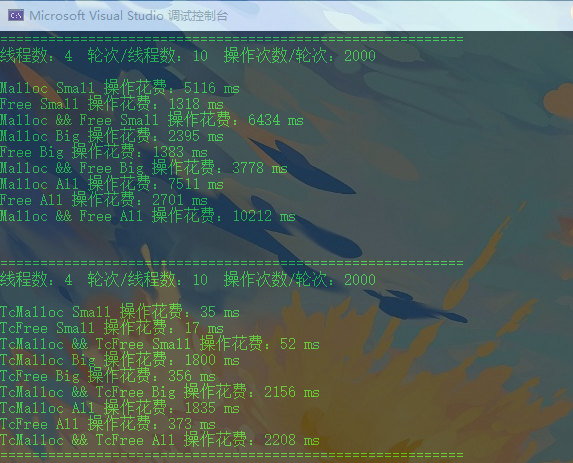
- 二层基数树优化结果

可以看到,使用基数树优化<_pageID,span>映射后,我们项目的内存使用效率要明显优于malloc&free,大概在其五倍左右。
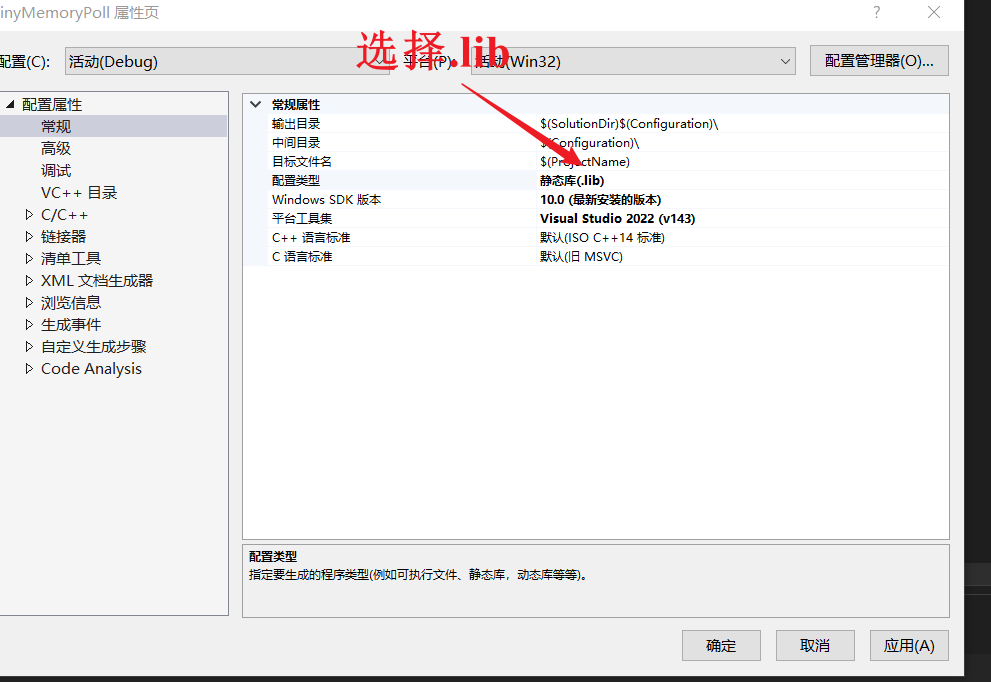
- 右键点击项目属性

- 选择输出位
.lib文件
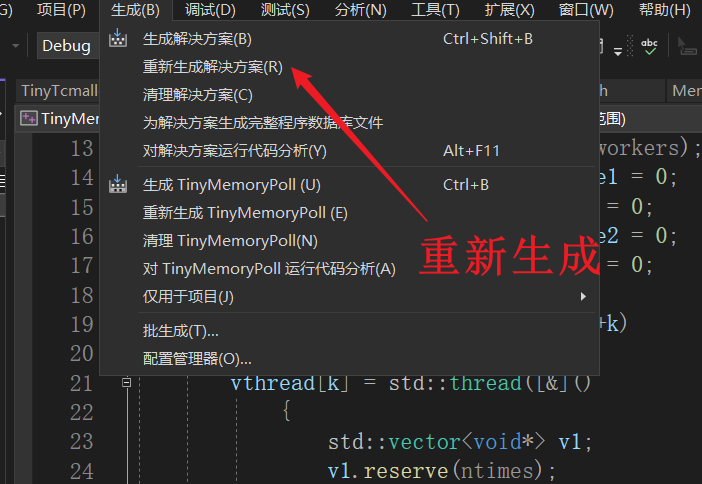
- 重新生成项目解决方案
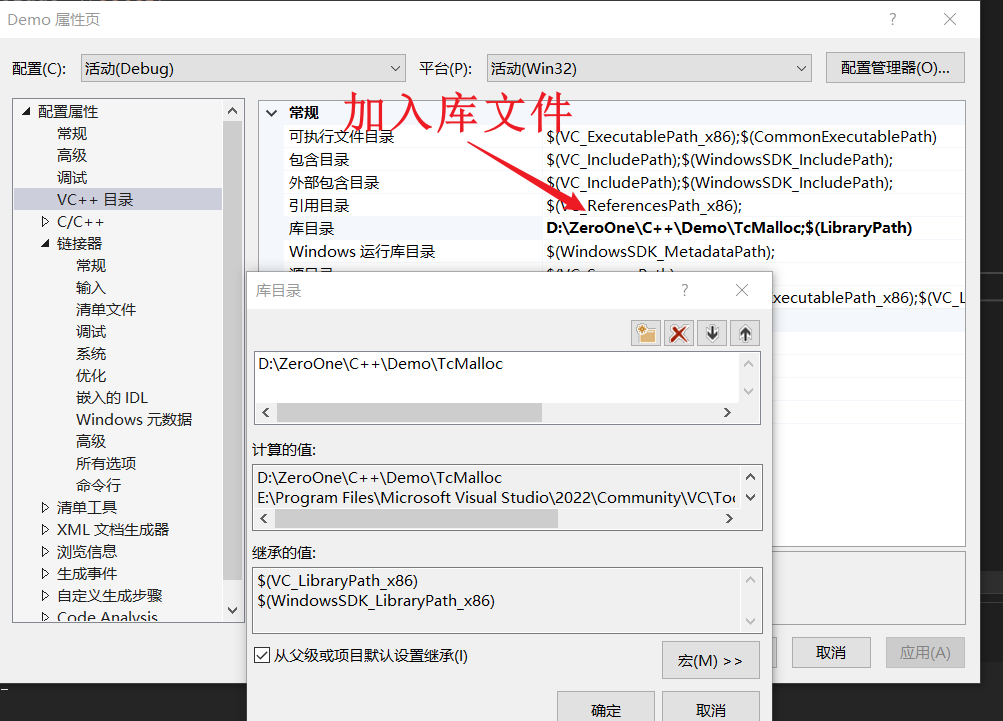
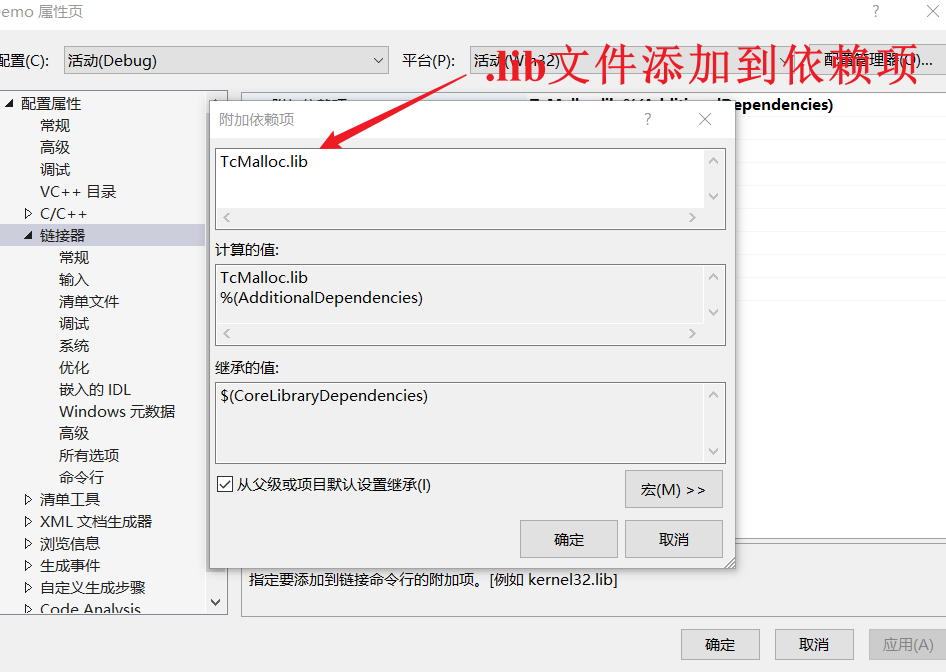
- 作者已经将项目头文件和响应的
.lib文件打包到TcMalloc文件夹,只需要将TcMalloc文件夹添加到你想添加的项目文件下,将其包含在库文件目录下并包含对应的静态文件库即可使用
- 以下是一个简单的使用示例。