基于springboot以及ChatGPT接口的智能BI(Business Intelligence)项目 , 用户只需要输入分析诉求并导入XLS数据, 即可通过AI进行图表生成与数据分析 , 实现数据分析的降本增效。
由于服务器资源问题目前线上体验暂时无法使用
线上地址 : http://bi.dhx.icu
测试用户:
testuser@163.com adorabled4
包含了主要项的版本信息,更多内容请参考pom.xml
| 项 | 版本 |
|---|---|
| JDK | 1.8 |
| MySQL | 5.7.32 |
| Redis | 6.2.6 |
| Maven | 3.8.6 |
| Mybatis-plus | 3.5.3 |
| MongoDB | 7.0.1 |
| Springboot | 2.7.14 |
| SpringCloud | 2021.0.7 |
| OpenAPI | 3.0 |
为了避免部分隐私信息泄漏(比如密钥, 数据库配置),目前我通过Nacos作为配置中心来存储, 准备了一个common.properties
用来存储部分的隐私信息 ,
如果需要本地运行并且没有配置Nacos, 那么你需要
关闭Nacos配置: 在bootstrap.yml中配置 spring.cloud.nacos.config.enabled 为false
在项目中添加application.properties(如果已经有就不用) , 添加上如下的信息
# OSS
alibaba.cloud.oss.endpoint=********************************
alibaba.cloud.oss.bucket=**********
alibaba.cloud.oss.domain=********************************
alibaba.cloud.access-key=*******************************
alibaba.cloud.secret-key=***********************************
# gitee第三方
gitee.clientId=************************************************
gitee.clientSecret=*********************************************
gitee.state=GITEE
gitee.redirectUri=http://localhost:8000/user/login
gitee.token.url=https://gitee.com/oauth/token?grant_type=authorization_code&client_id=${gitee.clientId}&redirect_uri=${gitee.redirectUri}&client_secret=${gitee.clientSecret}&code=
gitee.user.url=https://gitee.com/api/v5/user?access_token=
gitee.user.prefix=${gitee.state}
# github第三方配置
github.clientId=*************************
github.clientSecret=***********************************
github.state=GITHUB
github.redirectUri=http://localhost:6848/api/login3rd/github/callback
github.token.url=https://github.com/login/oauth/access_token?client_id=${github.clientId}&client_secret=${github.clientSecret}&redirect_uri=${github.redirectUri}&code=
github.user.url=https://api.github.com/user
github.user.prefix=${github.state}
# 讯飞星火配置
spark.appId=*************
spark.apiKey=***********************
spark.apiSecret=*************************
spark.host=spark-api.xf-yun.com
spark.path=/v3.1/chat
spark.domain=generalv3
##鱼聪明配置
yuapi.client.access-key=3s*******************
yuapi.client.secret-key=q*******************
## STMP配置
mail.host=smtp.163.com
mail.port=25
mail.username=********************
mail.password=E*******************- 通过MongoDB进行生成图表结果存储 , 原始数据量较大 , 通过对原始数据与图表结果的分库存储 , 一方面减小MySQL压力, 另一方面也可以提高原始数据的安全性(默认用户删除图表是删除生成的结果 , 对于原始数据需要走单独的删除接口)
- 通过策略模式以及反向压力思想, 根据当前系统负载进行策略选择
- 通过Spring-Retry进行失败重试
- 通过对生成图表JSON数据进行压缩 , 实测平均节约**35+%**空间
- 通过Docker进行项目部署, 同时通过Github Actions实现Docker镜像构建与推送到阿里云镜像仓库的自动化
- 通过WebSocket进行图表生成结果的实时推送
- 通过阿里云OSS进行用户图表存储(主要是头像)
- 更改用户注册登录方式为邮箱 + Oauth登录
- JWT + Redis双Token单点登录
- Logback日志配置以及基于AOP的日志处理
- 讯飞星火客户端 + Spring SseEmitter流式传输
- Knife4j + OpenAPI 3 接口文档
- 设计模式实践(适配器模式,桥接模式,门面模式,策略模式,工厂模式,观察者模式,代理模式等)
项目地址 :
目前的主要业务流程
下面我简单描述下部分扩展点的实现细节
MongoDB是一个面向文档的NoSQL数据库,它以JSON样式的文档存储数据。这种灵活的数据模型使得可以轻松地存储和检索不同结构的数据
对于生成的图表, 主要的操作更多是查询 , 也就是 读>>写
这里使用MongoDB进行信息存储 , 数据库查询速度提高了 3~4倍 , 接口响应速度快了40%+ , 因此我认为这一点还是十分有必要的。
要点在于我们如果去做好图表生成的CRUD操作以及MySQL与图表之间的数据一致性
关于CRUD操作 , 建议参考spring-data-mongodb的官方文档 , 这里给出地址
https://docs.spring.io/spring-data/mongodb/docs/3.3.10/reference/html/
另外, 十分建议直接使用docker去进行服务搭建 (只需要就记住一次命令 , 基本是属于一劳永逸)
还有一点需要注意的就是MongoDB的id , 这里我使用的是MongoDB自带的Object ID , 实际在查询的过程中仍然使用我们业务中的ChartId , 好处是这样用户生成图表会更加的方便
如果使用chartId作为主键 , 对于一些生成失败的图表就会占用主键 , 会大大增加编码的复杂性
只需要添加一个version字段用来标记即可
关于数据一致性 , 做法是在生成图表成功的时候进行数据的同步 , 这样也十分契合我们进行数据隔离存储的目的 , 也就是说我们的MySQL中不再存储图表生成的结果
反向压力的思想鱼总在直播的过程中已经介绍过了, 这里不再重复
详细内容可以查看 https://blog.csdn.net/weixin_41701290/article/details/119994997
使用的是java.lang.management包下的工具类
这里给出代码
public class ServerMetricsUtil {
private static OperatingSystemMXBean osBean = ManagementFactory.getPlatformMXBean(OperatingSystemMXBean.class);
private static MemoryMXBean memoryBean = ManagementFactory.getMemoryMXBean();
private static ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
/**
* 获取当前服务器CPU使用占比
*
* @return CPU usage percentage.
*/
public static double getCpuUsagePercentage() {
return osBean.getProcessCpuLoad() * 100; // Convert to percentage
}
/**
* 获取当前服务器内存使用占比
*
* @return Memory usage percentage.
*/
public static double getMemoryUsagePercentage() {
long usedMemory = memoryBean.getHeapMemoryUsage().getUsed();
long maxMemory = memoryBean.getHeapMemoryUsage().getMax();
return ((double) usedMemory / maxMemory) * 100; // Convert to percentage
}
/**
* 判断当前使用同步还是异步进行服务
* based on CPU and memory usage.
*
* @return true for synchronous, false for asynchronous.
*/
public static boolean shouldProvideSync() {
double cpuUsagePercentage = getCpuUsagePercentage();
double memoryUsagePercentage = getMemoryUsagePercentage();
// Threshold values for CPU and memory usage
double cpuThreshold = 70.0; // Example threshold value
double memoryThreshold = 80.0; // Example threshold value
if (cpuUsagePercentage < cpuThreshold && memoryUsagePercentage < memoryThreshold) {
return true; // Provide service synchronously
} else {
return false; // Provide service asynchronously
}
}
public static ServerLoadInfo getLoadInfo() {
double cpuUsagePercentage = getCpuUsagePercentage();
double memoryUsagePercentage = getMemoryUsagePercentage();
return new ServerLoadInfo(cpuUsagePercentage,memoryUsagePercentage);
}
}这里我的实现并不好 , 每次服务都需要去查询负载 , 并且这个方法执行很慢 , 并且仅仅是通过CPU以及内存占用来进行负载判断
更好的应该是结合更多的参数, 比如磁盘I/O 网络I/O等
如果不熟悉策略模式 , 建议浏览 https://www.runoob.com/design-pattern/strategy-pattern.html
简单来讲就是通过一个接口统一方法的各项信息(参数 , 名称, 返回值等) , 然后我们定义不同的策略去实现接口中的执行方法
由于在进行图表生成的过程中会使用到大量的Spring控制的Bean , 于是我把所有的策略实现类都交给了Spring管理
通过@Compoennet(value="xxxx") 来指明Bean的名称 , 然后在 策略选择器的代码中通过注入Map<String, Strategy> 来获取具体的执行策略
通过枚举类枚举了策略的Bean名称 , 便于代码维护
@Component
public class StrategySelector {
/**
* Spring会自动将strategy接口的实现类注入到这个Map中,key为bean id,value值则为对应的策略实现类
*/
@Resource
Map<String, GenChartStrategy> strategyMap;
/**
* 选择对应的生成图表执行策略
*
* @param info 服务器当前负载信息
* @return {@link GenChartStrategy}
*/
public GenChartStrategy selectStrategy(ServerLoadInfo info) {
if (info.isVeryHighLoad()) {
return strategyMap.get(GenChartStrategyEnum.GEN_REJECT.getValue());
} else if (info.isHighLoad()) {
return strategyMap.get(GenChartStrategyEnum.GEN_MQ.getValue());
} else if (info.isMediumLoad()) {
return strategyMap.get(GenChartStrategyEnum.GEN_THREAD_POOL.getValue());
} else {
return strategyMap.get(GenChartStrategyEnum.GEN_SYNC.getValue());
}
}
}那么具体的执行策略也就是原本我们生成图表的方式
- 同步
- 线程池异步
- RabbitMQ异步
这里我新加了一条 拒绝策略 , 只会在服务器负载特别高的时候去执行
我们在开发的过程中大多经常与JSON打交道, 那么常用的JSON网站大家应该都有印象
图表生成的JSON数据中是有很多的制表符以及空格的 , 因此把这部分的空间省去可以极大地提高我们的空间利用效率
原本想着找个开源库直接压缩, 但是在测试的过程中发现 , 由于Java语言本身的原因 , JSON中字段的双引号会被吞掉
举个例子
{
"title": {
"text": "资源消耗情况",
"subtext": "数据来源:数据库"
}
}在执行了压缩方法之后 , 就会变成下面这个样子
{
title: {
text: 资源消耗情况,
subtext: 数据来源
:
数据库
}
}压缩确实是压缩了, 但是前端已经无法解析这段JSON了 , 于是自己写了个正则替换 , 也能达到目的
关键在于替换掉 制表符以及大量的空格 换行符
public static String compressJson(String data){
data=data.replaceAll("\t+","");
data=data.replaceAll(" +","");
data=data.replaceAll("\n+","");
return data;
}效果
{
"title": {
"text": "资源消耗情况",
"subtext": "数据来源:数据库"
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "shadow"
}
},
"legend": {
"data": [
"2020年",
"2019年",
"2018年"
]
},
"grid": {
"left": "3%",
"right": "4%",
"bottom": "3%",
"containLabel": true
},
"xAxis": {
"type": "value",
"boundaryGap": [
0,
0.01
]
},
"yAxis": {
"type": "category",
"data": [
"平均每天能源消费量(万吨标准煤)",
"平均每天煤炭消费量(万吨)",
"平均每天焦炭消费量(万吨)",
"平均每天原油消费量(万吨)"
]
},
"series": [
{
"name": "2020年",
"type": "bar",
"label": {
"show": true,
"position": "inside"
},
"emphasis": {
"focus": "series"
},
"data": [
1361.5,
1106.2,
132,
189.8
]
},
{
"name": "2019年",
"type": "bar",
"label": {
"show": true,
"position": "inside"
},
"emphasis": {
"focus": "series"
},
"data": [
1335.6,
1101.1,
127.2,
184.3
]
},
{
"name": "2018年",
"type": "bar",
"label": {
"show": true,
"position": "inside"
},
"emphasis": {
"focus": "series"
},
"data": [
1292.9,
1088.9,
119.8,
172.6
]
}
]
}结果
{
"title": {
"text": "资源消耗情况",
"subtext": "2020-2018"
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "shadow"
}
},
"legend": {
"data": [
"平均每天能源消费量(万吨标准煤)",
"平均每天煤炭消费量(万吨)",
"平均每天焦炭消费量(万吨)",
"平均每天原油消费量(万吨)"
]
},
"toolbox": {
"show": true,
"orient": "vertical",
"left": "right",
"top": "center",
"feature": {
"mark": {
"show": true
},
"dataView": {
"show": true,
"readOnly": false
},
"magicType": {
"show": true,
"type": [
"line",
"bar",
"stack",
"tiled"
]
},
"restore": {
"show": true
},
"saveAsImage": {
"show": true
}
}
},
"xAxis": {
"type": "category",
"data": [
"2020年",
"2019年",
"2018年"
]
},
"yAxis": {
"type": "value",
"name": "消费量(万吨)"
},
"series": [
{
"name": "平均每天能源消费量(万吨标准煤)",
"type": "bar",
"stack": "总量",
"data": [
1361.5,
1335.6,
1292.9
]
},
{
"name": "平均每天煤炭消费量(万吨)",
"type": "bar",
"stack": "总量",
"data": [
1106.2,
1101.1,
1088.9
]
},
{
"name": "平均每天焦炭消费量(万吨)",
"type": "bar",
"stack": "总量",
"data": [
132,
127.2,
119.8
]
},
{
"name": "平均每天原油消费量(万吨)",
"type": "bar",
"stack": "总量",
"data": [
189.8,
184.3,
172.6
]
}
]
}这段数据中空间占用从 2.66kb 减小到了1.67kb , 效果还是十分可观的
其他的几个扩展点更多的是偏向于通用的一些代码 , 这里由于篇幅原因不再详细介绍。
后端这里配置了workflow的自动化Docker镜像部署 , 同时推送到阿里云的私有镜像仓库
这里我专门编写了两篇文章来详细介绍部署的流程以及Github Actions的配置过程, 欢迎前往阅读:
如果你并不熟悉Docker , 那么建议你先阅读:
一般我们在本地PC开发的过程中,只要项目能跑起来,那么环境基本上是没有问题的。
但是对于线上环境,往往会存在着许多注意不到的地方,对于线上环境,在部署的时候应当主要注意以下的几个问题
- 配置文件 : 非常简单的例子
,比如下图中的几个配置文件,一定要做出区分,比如数据库或其他配置是否是线上环境准备好的(包括但不限于访问路径,账户,密码以及其他的配置信息)。
- 环境配置:比如springboot项目中的
spring.profiles.active, 如果我们是手动执行命令, 每次都需要去输入--spring.profiles.active=prod等参数, 对于像我这样手懒的同志非常的不友好, 好在Dockerfile可以帮助我们很好的解决这个问题。 - 安全性: 比如防火墙配置、HTTPS 配置、认证和授权等(对于腾讯云, 阿里云等云服务厂商, 一定要在服务器的安全组中去配置访问权限)。

有关其他常见容器的配置 , 请参考 docker常用容器部署命令总结
接着就可以开始准备jar包了
对于默认使用spring-initialer准备的项目或者是git clone的项目 , pom文件中一般都会配备 spring-boot-maven-plugin的插件
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>在pom的build标签中我们可以自定义构建jar包时候的选项.
比如使用<finalName>${name}</finalName> 来定义jar包的名称。
这里使用项目名称来命名
打包建议使用IDEA的UI来进行操作(防止手抖输错命令)
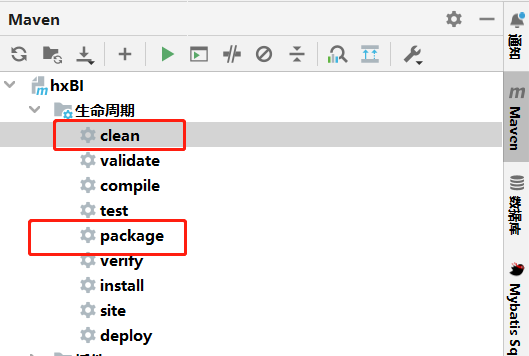
package完成之后我们可以看到在project/target目录下有打包好的jar文件

这里我们直接在当前目录 java -jar ${name}.jar即可运行项目
这里先给出一个Dockerfile的示例
FROM openjdk:8-jdk-alpine
LABEL maintainer="adorabled4 <dhx2648466390@163.com>"
# 设置时区
RUN apk add --no-cache tzdata && \
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo "Asia/Shanghai" > /etc/timezone && \
apk del tzdata
# 创建工作目录
RUN mkdir -p /app/hxBI
# 将所有jar文件添加到对应模块的目录中 => 需要注意的是 , TODO 构建的时候是以dockerfile所在的目录开始的
COPY jar/hxBI.jar /app/hxBI
# 暴露端口号
EXPOSE 6848
# 运行所有jar文件 : --spring.profiles.active=prod 指定项目的运行环境
CMD ["sh", "-c", "java -jar /app/hxBI/hxBI.jar --spring.profiles.active=prod"]其中必要的注释都已在上面给出 ,
关于FROM openjdk:8-jdk-alpine
FROM openjdk:8-jdk-alpine:这条指令定义了基础镜像。它告诉 Docker 使用名为 openjdk 的镜像,并选择标签为 8-jdk-alpine
,这意味着基础镜像是一个包含 OpenJDK 8 和 Alpine Linux 的镜像。Alpine Linux 是一个轻量级的 Linux 发行版。
简单来讲 , 这一行代码就可以代替我们手动去完成
- 下载jdk
- export path
并且丝毫不用担心服务器中JDK过多导致的版本冲突问题。
需要注意的是 : RUN , COPY CMD 等操作都是以以dockerfile所在的目录开始的 , 也就是说使用的是相对路径
使用docker build 命令来构建镜像
docker build 命令的常见参数和用法如下:
docker build [OPTIONS] PATH | URL | -其中,OPTIONS 是一些可选参数,PATH 是 Dockerfile 所在的路径。URL 表示可以从远程仓库中获取 Dockerfile,而 -表示从标准输入中读取
Dockerfile。
常用的 docker build 参数包括:
--tag或-t:为构建的镜像指定标签。标签的格式一般是repository:tag,例如myapp:latest。--file或-f:指定要使用的 Dockerfile 文件的路径。如果你的 Dockerfile 不是默认的Dockerfile,可以使用这个参数来指定。--build-arg:传递构建参数给 Dockerfile。可以在 Dockerfile 中使用ARG指令来引用这些参数。--no-cache:禁止使用缓存的镜像层。如果在构建过程中某一层的镜像发生了变化,Docker 默认会使用缓存,但使用这个参数会禁用缓存。
示例用法:
# 在当前目录下的 Dockerfile 中构建镜像,并设置标签为 myapp:latest
docker build -t myapp:latest .
# 使用指定的 Dockerfile 文件构建镜像,并设置标签
docker build -t myapp:latest -f Dockerfile.dev .
# 从远程 Git 仓库中的 Dockerfile 构建镜像,设置标签
docker build -t myapp:latest https://github.com/user/repo.git#branch:path/to/Dockerfile
# 传递构建参数给 Dockerfile
docker build --build-arg APP_VERSION=1.0 -t myapp:latest .
# 构建镜像时禁用缓存
docker build --no-cache -t myapp:latest .这里我使用的命令是 docker build -t hxbi:v1 .
. 表示使用当前工作目录下的Dockerfile文件
具体过程记录如下
[root@iZ0jld3sffhskpkba9tnt9Z app]# pwd
/app
[root@iZ0jld3sffhskpkba9tnt9Z app]# ls
dist dist.tgz Dockerfile Dockerfile-frontend jar
[root@iZ0jld3sffhskpkba9tnt9Z app]# ls jar
hxBI.jar
[root@iZ0jld3sffhskpkba9tnt9Z app]# docker build -t hxbi:v1 .
[+] Building 0.8s (9/9) FINISHED
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 664B 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for docker.io/library/openjdk:8-jdk-alpine 0.7s
=> [1/4] FROM docker.io/library/openjdk:8-jdk-alpine@sha256:94792824df2df33402f201713f932b58cb9de94a0cd524164a0f228334 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 59B 0.0s
=> CACHED [2/4] RUN apk add --no-cache tzdata && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo " 0.0s
=> CACHED [3/4] RUN mkdir -p /app/hxBI 0.0s
=> CACHED [4/4] COPY jar/hxBI.jar /app/hxBI 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:24d55a0575bee2ecab97b9c04dc1e5fe680942ca4c8af765ff58418f969cf3cb 0.0s
=> => naming to docker.io/library/hxbi:v1 0.0s
[root@iZ0jld3sffhskpkba9tnt9Z app]# 运行容器使用 docker run 命令
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]其中,OPTIONS 是一些可选参数,IMAGE 是要运行的镜像名称或镜像 ID。COMMAND 表示容器启动后要执行的命令,ARG...
是传递给命令的参数。
常用的 docker run 参数包括:
--detach或-d:以后台模式运行容器,即使容器内的主进程没有在前台运行,容器也会继续运行。--name:为容器指定一个自定义的名称,可以在后续操作中使用。--publish或-p:将容器的端口映射到主机的端口。格式为hostPort:containerPort。--volume或-v:将主机文件系统的目录或文件挂载到容器中,以实现数据持久化。--env或-e:设置环境变量,供容器内的应用程序使用。--network:指定容器的网络模式,可以是bridge、host、none等。--restart:设置容器的重启策略,如always、unless-stopped等。--rm:容器停止后自动删除容器。通常用于一次性任务。
这里我执行的命令是docekr run -d -p 6848:6848 --name hxbi hxbi:v1
如果你想设置容器自动启动 , 请在后面加上--restart=always
首次在线上环境上部署项目总是会伴随着各种各样的问题 ,灵活的使用docker logs命令可以帮助我们更好的去进行运维工作
docker logs 命令的常见参数和用法如下:
docker logs [OPTIONS] CONTAINER其中,OPTIONS 是一些可选参数,CONTAINER 是要查看日志的容器的名称或容器 ID。
常用的 docker logs 参数包括:
--follow或-f:实时跟踪容器日志输出,类似于tail -f命令。在容器内有新的日志输出时会显示在终端上。--since:显示从指定时间戳开始的日志。可以是相对时间(如10m表示过去的 10 分钟)或绝对时间(如2023-08-01T00:00:00)。--tail:只显示最后指定行数的日志,默认是全部显示。--timestamps或-t:显示日志条目的时间戳。--details:显示更多的容器运行细节,如容器的创建时间、运行时间等。
示例用法:
# 查看容器名为 my-container 的日志(默认显示全部日志)
docker logs my-container
# 实时跟踪容器名为 my-container 的日志
docker logs -f my-container
# 查看容器名为 my-container 的日志,只显示最近 100 行
docker logs --tail 100 my-container
# 查看容器名为 my-container 的日志,显示从过去的 1 小时内的日志
docker logs --since 1h my-container
# 查看容器名为 my-container 的日志,显示时间戳
docker logs -t my-container当排除到错误之后, 我们可能会需要去删除容器以及镜像, 来重新构建
这里使用docker stop , docker rm , docker rmi 命令
rmi 顾名思义 , remove image( 删除镜像)
比如
docker stop hxbi;
docker rm hxbi;
docker rmi hxbi:v1;对于上面中的部署或者是删除的命令 , 我们可以会需要重复的去执行 , 这里可以去编写一个shell脚本来代理手动去敲命令
关于如何创建并编写文件
- touch xxx.sh
- vi xxx.sh
- shift + insert 复制内容
- Esc , 接着在命令行模式下输入 !wq 回车即可
创建容器
#!/bin/bash
# 切换到工作目录
cd /app
# 构建 Docker 镜像
docker build -t hxbi:v1 .
# 运行容器
docker run -d -p 6848:6848 --name hxbi hxbi:v1删除容器
#!/bin/bash
# 停止容器
docker stop hxbi
# 删除容器
docker rm hxbi
# 删除镜像
docker rmi hxbi:v1接着我们可以 run xxx.sh 来执行shell脚本.
如果没有权限请先试用chmod命令来修改文件的权限(推荐 chmod xxx.sh 755)
直接在前端的工作目录下输入npm build即可
打包好的Dist目录下是一些静态的资源文件 ,我们只需要把它放入nginx中即可
如果你想用Docker去部署nginx容器 , 请参考 https://blog.dhx.icu/2023/01/30/Linux/docker%E5%B8%B8%E7%94%A8%E5%AE%B9%E5%99%A8/
在下载nginx之前, 建议先在服务器上安装宝塔面板 , 通过面板的UI去执行操作 , 十分方便快捷。
宝塔安装命令 :
if [ -f /usr/bin/curl ];then curl -sSO download.cnnbt.net/install_panel.sh;else wget -O install_panel.sh download.cnnbt.net/install_panel.sh;fi;bash install_panel.sh ed8484bec
接着我们访问宝塔面板
如果你忘记了面板的地址, 请在命令行中输入
bt接着通过提示信息来进行操作。
软件商店中搜索nginx ,直接安装即可。
首先在面板中添加站点(如果没有域名建议去国内云服务厂商购买域名,第一年只需要不到十块钱(
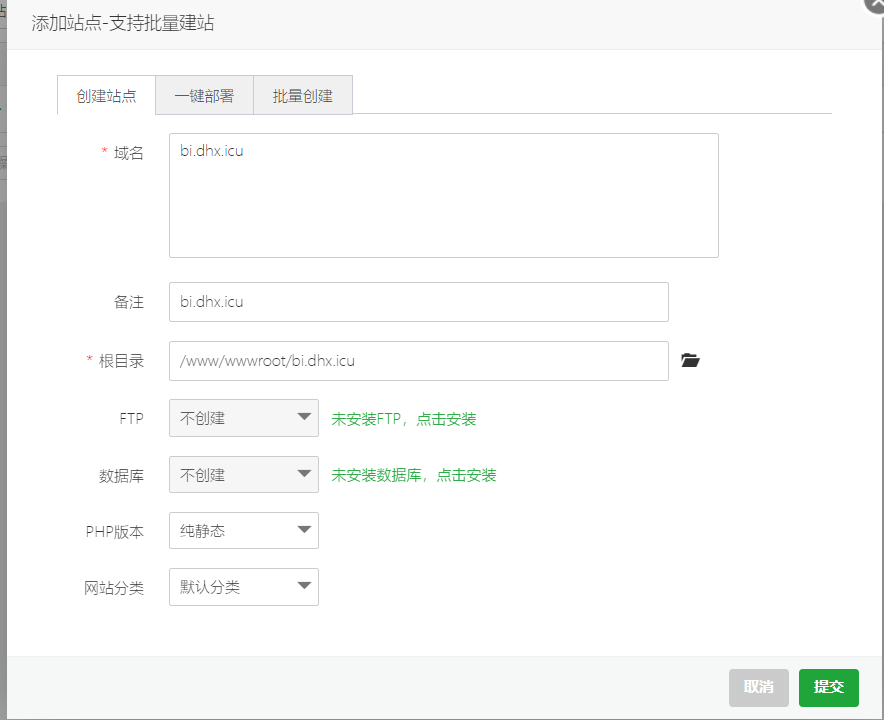
这里在添加完了域名之后 , 记得去域名解析中添加域名配置
- A记录
- 指向服务器的IP地址即可
点击宝塔面板左侧 文件选项, 进入到站点的工作目录 , 将我们dist目录下的静态资源文件上传到其中即可。
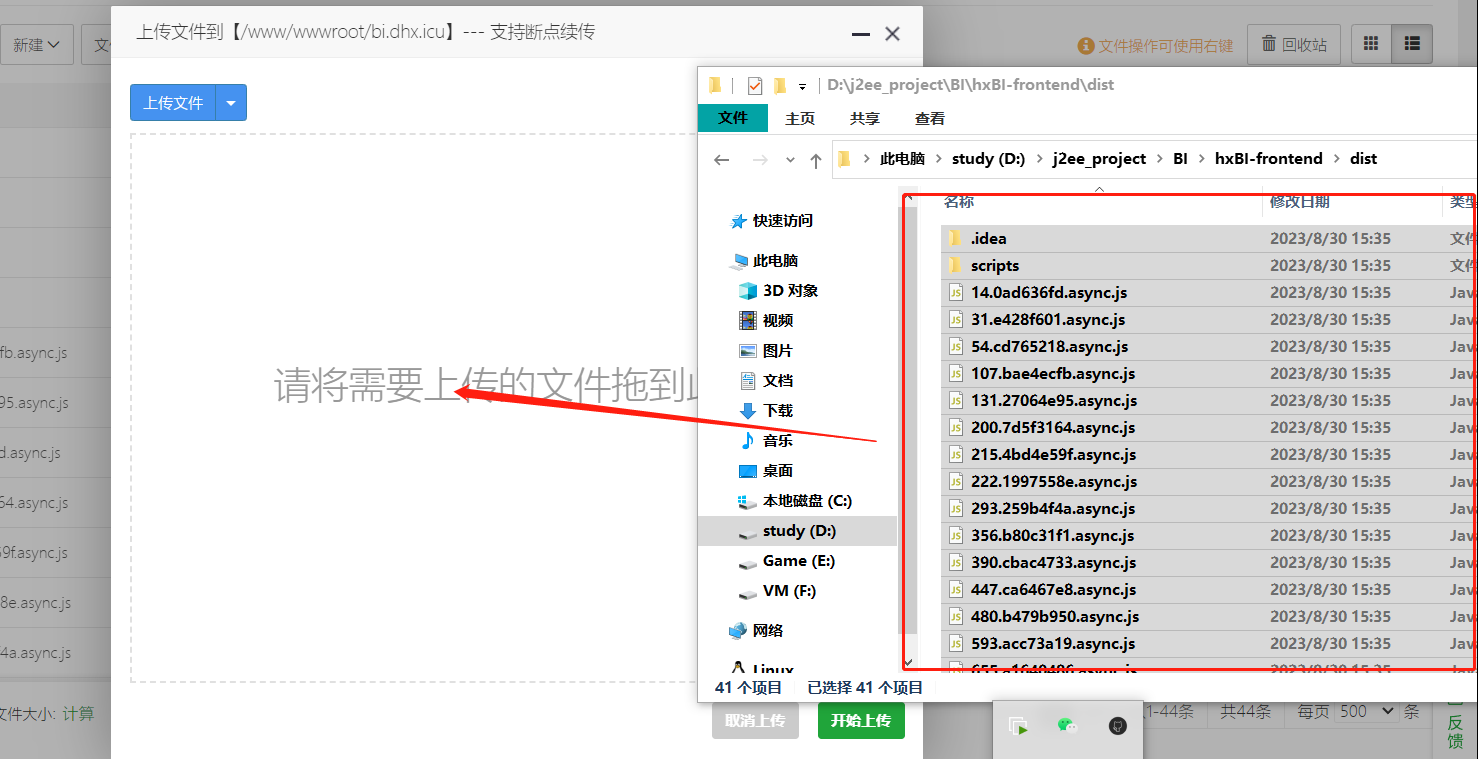
记得替换掉原本的index.html
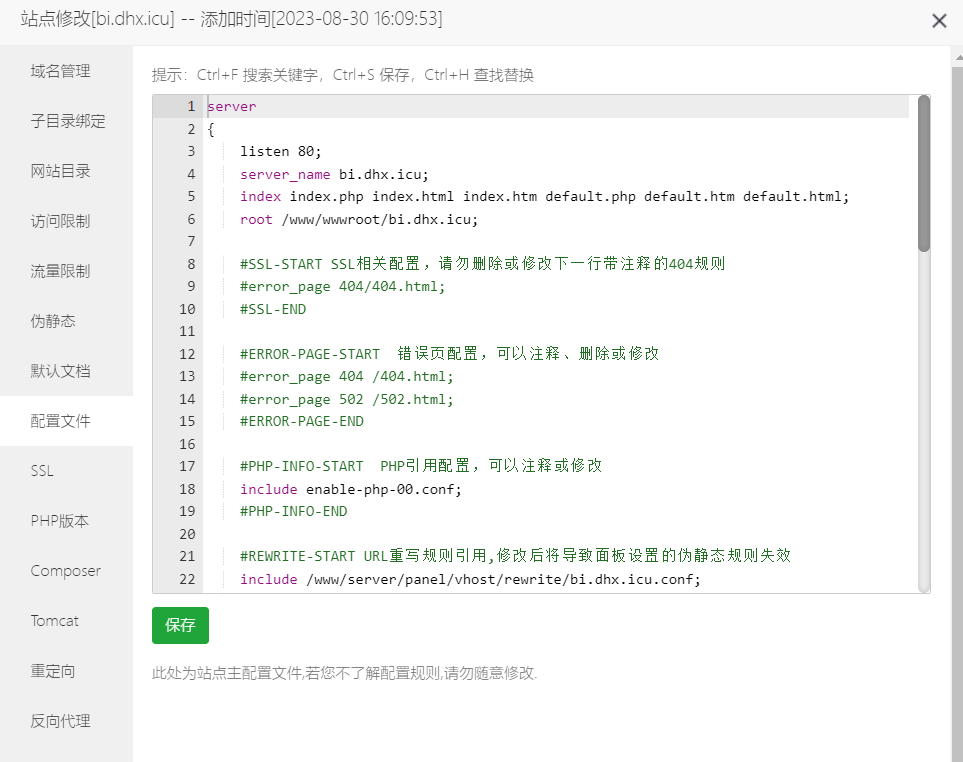
由于我们部署的是前后端分离的相面, 并且nginx本身处于安全考虑 , 原本的访问路径都会被替换到我们当前的前端的路径中 , 因此需要在nginx中配置反向代理.
这里给出核心的配置
location / {
# 用于配合 browserHistory使用
try_files $uri $uri/index.html /index.html;
}
location /api {
proxy_pass http://${backend_project_ip}:${backend_project_port};
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
}
其中/api表示 代理的路径前缀
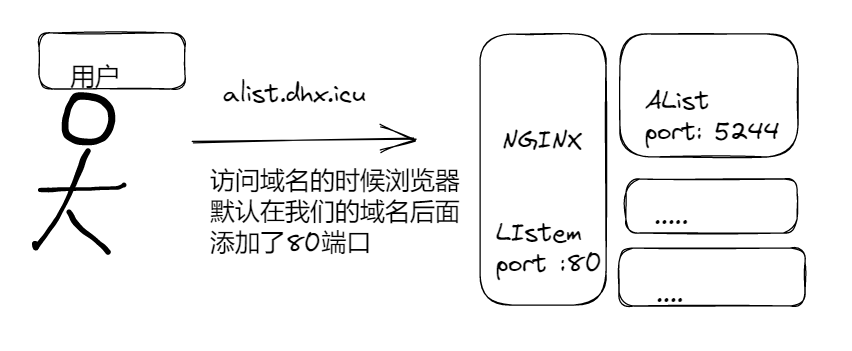
关于NGINX反向代理
那么对于代理我们可以这样来理解
正向代理 : 比如我们平时使用的VPN , 是用户主动代理的, 就是正向代理
反向代理 : 用户不知道的, 由服务提供者来设置的代理, 表面上用户访问的域名通过DNS解析到了某一台服务器的IP地址, 可实际上为用户提供服务的并不一定是这台机器(或者是端口) , > > 那么也就是NGINX这里起到的作用 : 反向代理 , 我们也可以在这里做其他的操作, 比如负载均衡 , 黑白名单等等
当你正确完成了上述的内容 , 访问部署的域名(或者是ip) , 即可查看到部署的前端页面。
前端很丑 , 轻喷QAQ

这里个人中心右边的板块还需要修改

非常欢迎您为该项目做出贡献,您可以:
- 在Issues页面中报告漏洞或提出改进意见。
- 提交Pull Request。
- 分享该项目给你的朋友和社区。
目前项目还有一些遗留的问题没有解决
- 前端部署到Nginx之后在填写生成图表的表单的时候上传文件显示错误(因为Nginx默认是禁止通过POST来访问静态资源的) , 不过在实际的测试过程中我发现后端是可以接收到文件的 (奇怪的bug)
- 目前还没有统计用户生成图表的调用结果等数据(我的想法是通过统计这个去实时的显示在个人中心页面中 , 使得可以更加直观的看到调用的结果)
- 前端有很多展示上的问题 : 比如部分页面没有loading , 以及页面展示原始数据的方式并不一致
- 用户无法修改原始数据
- 虽然图表引入了版本号, 但是前端在展示的时候还是有问题 , Spring-data-MongoDB分页查询返回了全部的元素数量
- 后端通过java.util.managment包来获取服务器的负载 , 在测试的过程中发现获取负载数据十分消耗时间
- 执行拒绝策略没有对之后的图表进行处理(这里的想法是存入到Redis集合中 , 通过定时任务去再次生成)
该项目基于MIT许可证开源,详情请查看LICENSE文件。