This project is for Donaldson Company, which is a global company that creates filters for hundreds and thousands of different products. Donaldson is looking to the future with this project and would like us to create a system to analyze Tweets that their clients are creating for mentions of different power-train alternatives to combustion engines. In doing this Donaldson is looking to the future and seeking to be well prepared for any new emerging technologies so that they can effectively corner the market.
The system will grab Tweets from Twitter and store them in our database we have created. Once there are Tweets in the database the user will be able to either grab more Tweets or use built-in natural language processing methods to analyze Tweets already in the database. The user will also be able enter in new companies and power-train alternatives into the database to enable more customized data processing.
-
to allow easy tweet retrieval so that the user can seamlessly populate a database with relevant information
-
A slim database that is easily navigated so that there is a limited amount of wasted space
-
VADER Analysis of Tweets so that the user can identify market sentiment of these alternative power-trains
NLTK - Natural Language Tool Kit
VADER - Valence Aware Dictionary for Sentiment Reasoning
NLP - Natural Language Processing
https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
https://www.nltk.org/howto/sentiment.html
https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
https://www.Donaldson.com/en-us/
https://ojs.aaai.org/index.php/ICWSM/article/view/14550
There is no current system
We will pull down Tweets from the specified companies, store them in a database. We will then use VADER analysis to rate the Tweets according to the scores previously requested by Donaldson Company (Positive/Neutral/Negative/Compound) and store those values alongside the Tweets in question.
In addition to this tone analysis, we will also attempt to flag any tweet that may potentially be about a particular alternative power-train, for any analysis that might be done on it.
Also, we will attempt to build methods of extracting potentially useful information from the Tweets gathered, such as frequency mentioning various power-trains, how frequently those mentions occur in the context of how frequently the company Tweets overall, whether the frequency is changing, etc.
- Retrieve Tweets from Twitter.
- Save Tweets to SQL database.
- Save VADER analysis of Tweets to database.
- Identify mentions of alternative power-trains in Tweets and mark Tweets as such in database
- (New) Also grab Retweets by the company and see if there is anything to be analyzed about them.
- (New) Also grab Replies by company, see if there is anything to be analyzed about them.
- Output CSV of requested data
- Output graphs showing some of the above analyses where possible
The only usability requirements that have been mentioned by Donaldson is that they would like the data, and have mentioned CSV format once, briefly, and more recently have mentioned that they would like to see graphs. They also once mentioned MongoDB, which another Donaldson contact then shot down due to a lack of familiarity on our part with databases.
They seem utterly uninterested in using the code we provide, instead being more interested in the data we produce with it. The code may end up being nothing more than a reference point for them to identify how we obtained a specific result in the data we provide them.
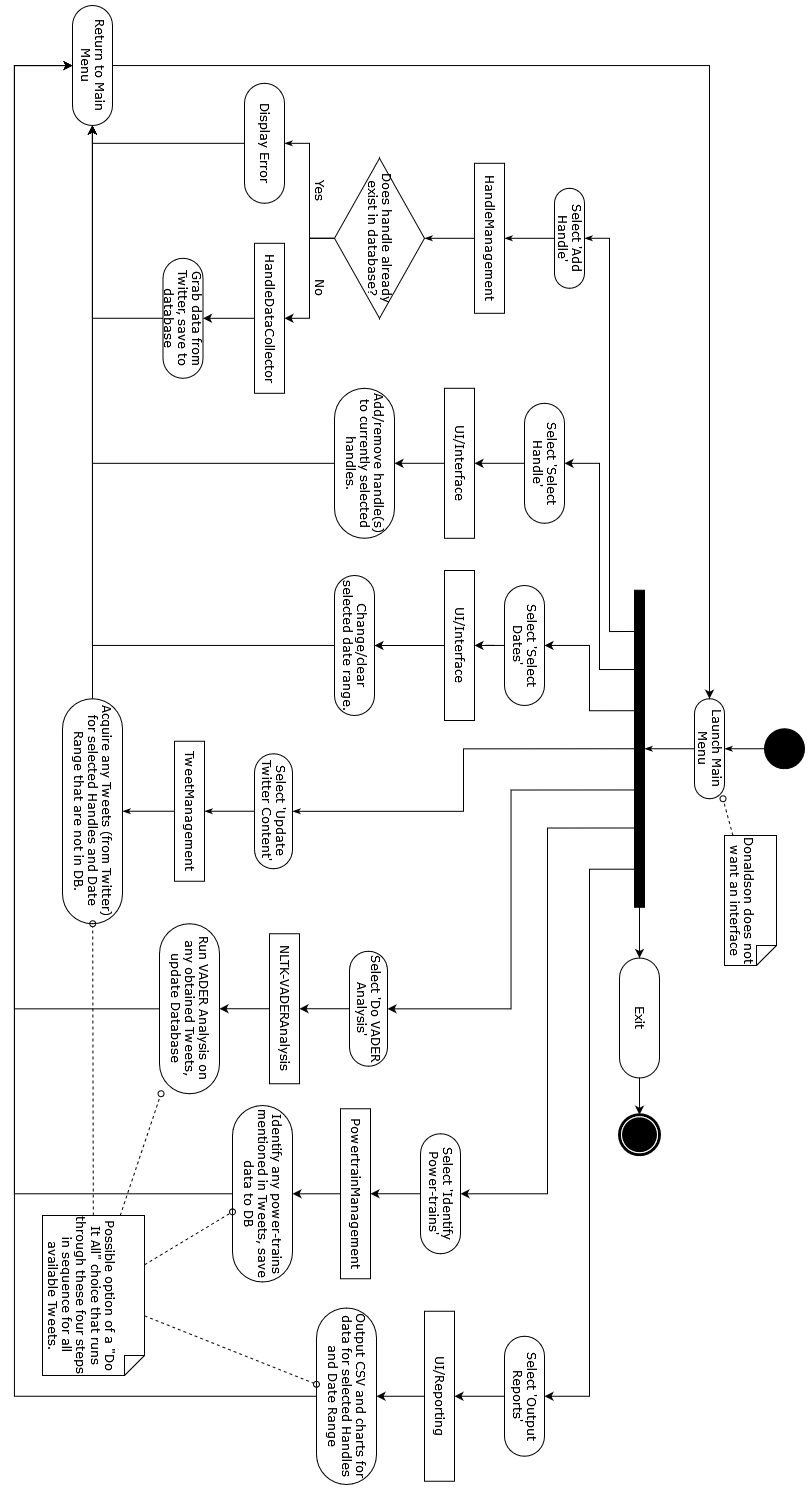
In our own opinion, we would likely prefer to have a system that is at a minimum usable enough that you can get data out through a text-based menu, but please refer to the Interface section below.
Installation should be as clear as we can make it. We should make clear what packages need to be installed, what tokens from Twitter APIs need to be obtained, and how to construct any necessary configuration files.
All systems involved either rely on local desktop hardware, remote databases, and Twitter. So long as their desktop functions, Twitter still exists, and the user can host a database of some kind, that's all that is required.
No specifics have been mentioned, and all focus has been on the data and contents of the data, rather than code. Donaldson may not expect to ever use the actual code, nor integrate it with their systems.
However, we will need it to be comfortably performant, so that we can actually obtain and produce data before the deadline. Don't take 40 minutes to update values if it can be done in 20 seconds, for example.
No specifics have been mentioned, other than a brief mention by one member of Donaldson that they use MongoDB in response to us mentioning we were learning MySQL.
No supportability requirements specified, but we will make an attempt to code it in a way that is modular enough that, if desired, someone could replace a small module with a module of their own design (if needed) to switch from, say, MySQL support to MongoDB support.
As VADER (the NLTK package VADER analysis is built into), Tweepy (our Twitter API interface), and the MySQL Connector package are all built in Python, our code will need to be built in Python as well.
Questions about an interface lead to us being told no interface was necessary. We may implement a rudimentary one for example purposes, but the goal of the project appears to be the data that comes out of it, with the code being there to help explain the results if requested. As such, the code itself may not need to be usable by someone via a user-friendly interface.
The code itself in a directory structure that Python can interpret, along with a list of necessary requirements to install.
We hope that providing package installation instructions for any dependencies our code requires avoids any concerns of "sub-licensing" or whatever it might be called, where we may not have permission from NLTK/Tweepy/MySQL to distribute their software directly to Donaldson. If Donaldson then chooses to install those packages, they then choose to agree to those license terms.
If those license terms are unacceptable, they have enough of our code to be able to write their own modules to replace the ones our code depends on.
Frankly, however, none of us are lawyers, and as such we really don't know how licensing on this might work.
We must cite anywhere anything VADER-related appears:
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
For the sake of thoroughness, however:
-
Open Source:
-
NLTK: https://github.com/nltk/nltk/wiki/FAQ
Source code is Apache 2.0.
Documentation (that we are not distributing) is Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States license
-
VADER (integrated into NLTK): https://github.com/cjhutto/vaderSentiment
License is MIT.
-
-
TweePy: https://github.com/tweepy/tweepy
License is MIT.
-
MySQL Python Connector:
License is GNU General Public License (GPLv2)
-
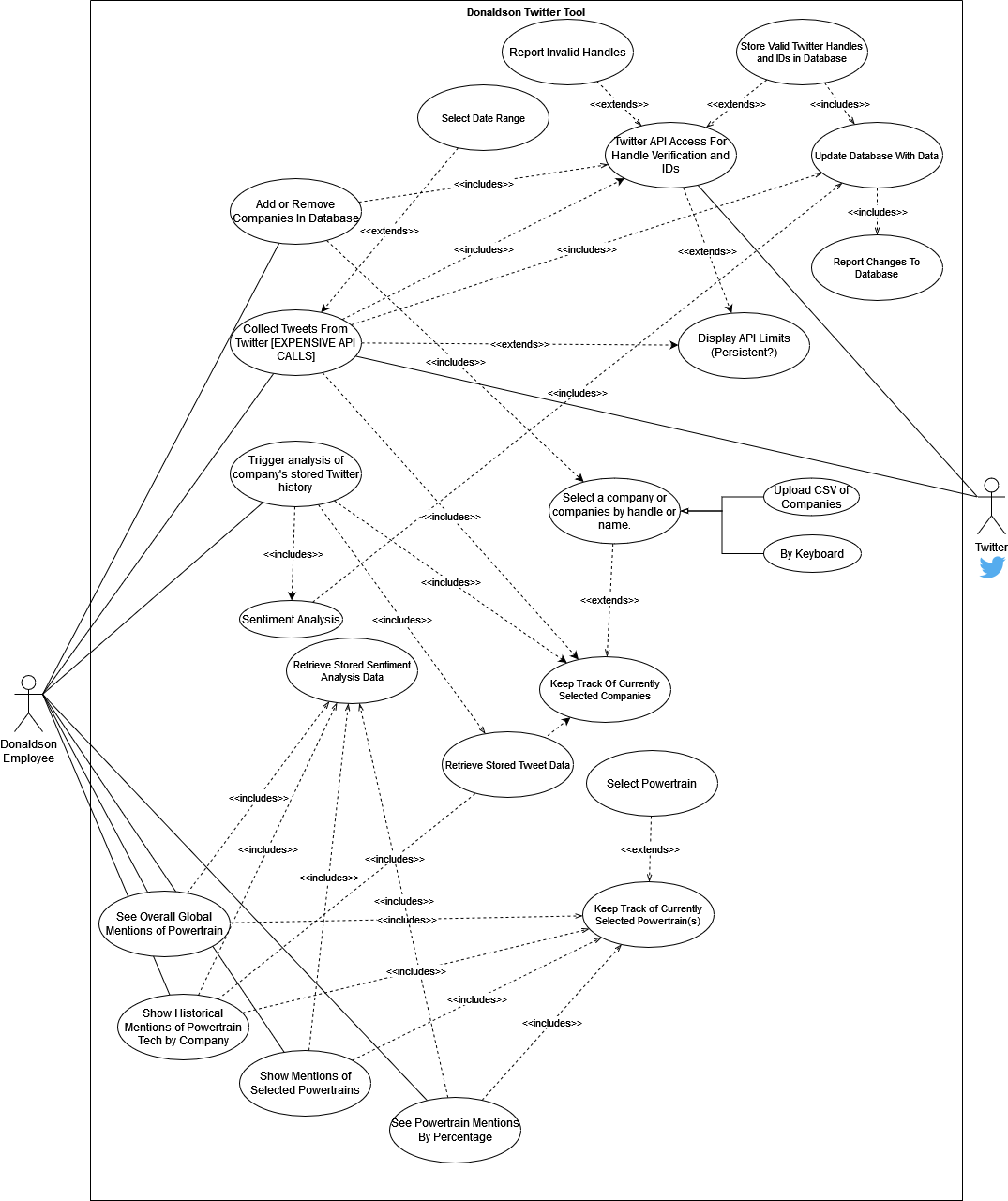
User requests the ability to add a company to the database. Program requests Twitter handle (required/not-null) to be input via keyboard, or via a file it reads in, permitting multiple companies to be added at once. The program verifies that each handle is valid and not already in the database under the retrieved ID and presents information from that account (bio/description, perhaps) and asks to confirm this is the correct account. If confirmed, company is added to database for later use. No further analysis occurs at this time.
A menu listing valid companies exists. User selects company from that menu, or perhaps selects multiple companies, either through the keyboard or via a file read in to the program. User asks program to query for new Tweets, possibly by count, possibly by date range, or other alternatives. Program asks for confirmation, with warnings on how this request will impact the Tweet caps. Both quarter-hourly and monthly caps are involved in this. If the user confirms the action, this API interface is queried.
Note: this pulls down all relevant data for analysis and storage in the database. No further requests that impact the monthly cap should be required?
Dumps CSV containing powertrain mentions, labeled by time or other methods of categorization. May be as a simple CSV for use in whatever program Donaldson deems fit? This avoids locking them into whatever poor UI we would likely settle on.
Donaldson has also requested graphs. I don't believe any of us have any serious experience with statistical analysis, but we can certainly try to make some graphs?
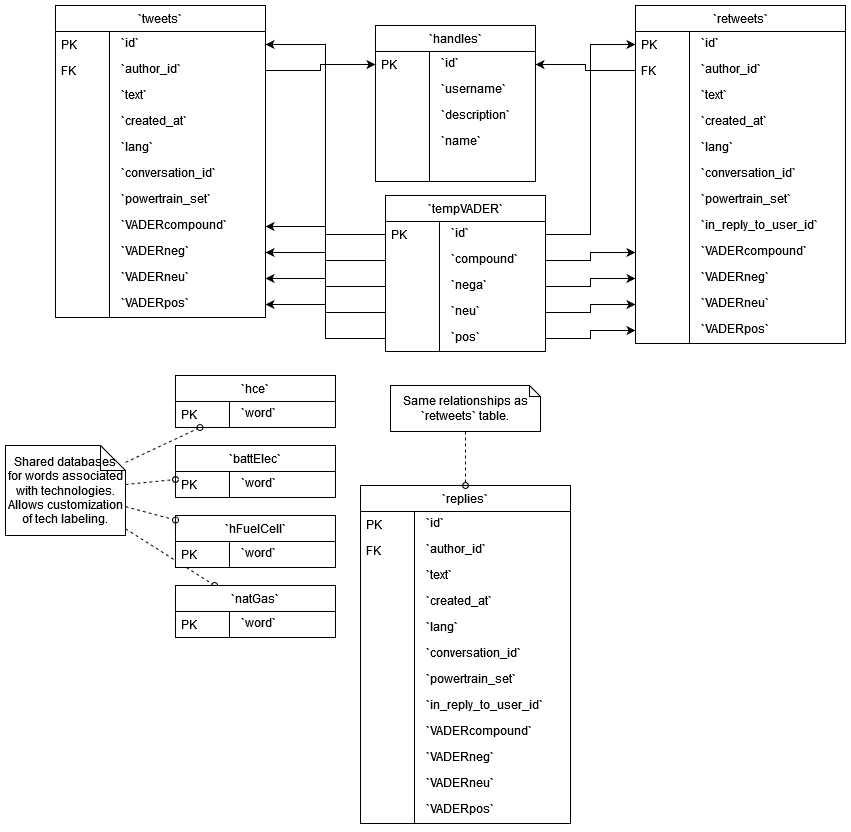






Expanded architecture may be viewed here, but is too large for viewing in this page: https://github.com/agarcia169/4306-Donaldson-Project/blob/main/images/iteration2/architecture-Expanded.drawio.png
{kind=link}



NLTK - The Natural Language Toolkit is a platform used for building python programs to work with the Human Language it contains text processing libraries for tokenization, parsing , classification and semantic reasoning it was originally developed by Steven Bird, Edward Loper, and Ewan Klein for the purposes of program development and education purposes
Sentiment Analysis - the process of computationally identifying and categorizing opinions expressed in a piece of text, mostly used to determine whether the writer's attitude towards a specific topic is positive, negative, or neutral
VADER - Valence Aware Dictionary for Sentiment Reasoning is a module that is based within the initial package of NLTK and can be applied directly to unlabeled text data. VADER analysis relies on a dictionary that can map lexical (relating words) to emotion intensities known as sentiment scores. which the score can be found just by adding together intensities of the sentence.
https://github.com/agarcia169/4306-Donaldson-Project/blob/main/csvfile.csv
As the data seems to be the focus of Donaldson's interest, a sample copy of an initial run of a small attempt at collecting data is above, as produced by the code below. It's approximately 1.85MB, is tab-delimited, and contains approximately 6380 Tweets from several companies Donaldson is interested in. Each line also contains the relevant VADER analysis and a rudimentary attempt at marking Tweets relating to alternative power-trains.
get_handle_from_twitter(): # Returns a Twitter ID, username, description, and name.add_handle_to_database(): # Adds a Twitter Handle to the database.
get_twitter_handle (): # Gets the handle from the DB of a provided Twitter ID#
get_twitter_id (): # Get the ID# from the DB of a provided handleget_db_connection(): # Establishes an immutable connection to the DB server.
# Once set (with the relevant fields) it can not be changed. (Singleton)get_twitter_connection(): # Called with a Twitter Bearer Token ONE TIME ONLY
# to initialize a connection to twitter. Thereafter, called with no arguments
# to get a tweepy.Client object with that connection in it. (Singleton)evaluate_new_tweets(): # checks whether new Tweets in the database have had VADER analysis
updatelabels(): # updates database entries to reflect what power-train mentions if any are presentadd_tweet_to_db(): # checks whether new Tweets in the database have had VADER
retrieve_recent_tweets(): # retrieves tweet that was most recently put into DB
retrieve_older_tweets(): # retrieves oldest tweet that was put into DB
retrieve_many_tweets(): # retrieves multiple tweets from DB
retrieve_tweets(): # retrieves a tweet from the DB with a specific tweet IDanalyze_analyzed_tweets_in_DB(): # analyzes all Tweets in database and then for any
# that don't analyze them and store the results in the databasehttps://github.com/agarcia169/4306-Donaldson-Project/tree/main/src/donaldson_asu_twitter/ReportingUI
dumpy(): # goes through the MySQL database and outputs all tweets with analysis
# into a .csv file