druid-0.21.0
Apache Druid 0.21.0 contains around 120 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 36 contributors. Refer to the complete list of changes and everything tagged to the milestone for further details.
# New features
# Operation
# Service discovery and leader election based on Kubernetes
The new Kubernetes extension supports service discovery and leader election based on Kubernetes. This extension works in conjunction with the HTTP-based server view (druid.serverview.type=http) and task management (druid.indexer.runner.type=httpRemote) to allow you to run a Druid cluster with zero ZooKeeper dependencies. This extension is still experimental. See Kubernetes extension for more details.
# New dynamic coordinator configuration to limit the number of segments when finding a candidate segment for segment balancing
You can set the percentOfSegmentsToConsiderPerMove to limit the number of segments considered when picking a candidate segment to move. The candidates are searched up to maxSegmentsToMove * 2 times. This new configuration prevents Druid from iterating through all available segments to speed up the segment balancing process, especially if you have lots of available segments in your cluster. See Coordinator dynamic configuration for more details.
# status and selfDiscovered endpoints for Indexers
The Indexer now supports status and selfDiscovered endpoints. See Processor information APIs for details.
# Querying
# New grouping aggregator function
You can use the new grouping aggregator SQL function with GROUPING SETS or CUBE to indicate which grouping dimensions are included in the current grouping set. See Aggregation functions for more details.
# Improved missing argument handling in expressions and functions
Expression processing now can be vectorized when inputs are missing. For example a non-existent column. When an argument is missing in an expression, Druid can now infer the proper type of result based on non-null arguments. For instance, for longColumn + nonExistentColumn, nonExistentColumn is treated as (long) 0 instead of (double) 0.0. Finally, in default null handling mode, math functions can produce output properly by treating missing arguments as zeros.
# Allow zero period for TIMESTAMPADD
TIMESTAMPADD function now allows zero period. This functionality is required for some BI tools such as Tableau.
# Ingestion
# Native parallel ingestion no longer requires explicit intervals
Parallel task no longer requires you to set explicit intervals in granularitySpec. If intervals are missing, the parallel task executes an extra step for input sampling which collects the intervals to index.
# Old Kafka version support
Druid now supports Apache Kafka older than 0.11. To read from an old version of Kafka, set the isolation.level to read_uncommitted in consumerProperties. Only 0.10.2.1 have been tested up until this release. See Kafka supervisor configurations for details.
Multi-phase segment merge for native batch ingestion
A new tuningConfig, maxColumnsToMerge, controls how many segments can be merged at the same time in the task. This configuration can be useful to avoid high memory pressure during the merge. See tuningConfig for native batch ingestion for more details.
# Native re-ingestion is less memory intensive
Parallel tasks now sort segments by ID before assigning them to subtasks. This sorting minimizes the number of time chunks for each subtask to handle. As a result, each subtask is expected to use less memory, especially when a single Parallel task is issued to re-ingest segments covering a long time period.
# Web console
# Updated and improved web console styles
The new web console styles make better use of the Druid brand colors and standardize paddings and margins throughout. The icon and background colors are now derived from the Druid logo.

# Partitioning information is available in the web console
The web console now shows datasource partitioning information on the new Segment granularity and Partitioning columns.
Segment granularity column in the Datasources tab

Partitioning column in the Segments tab

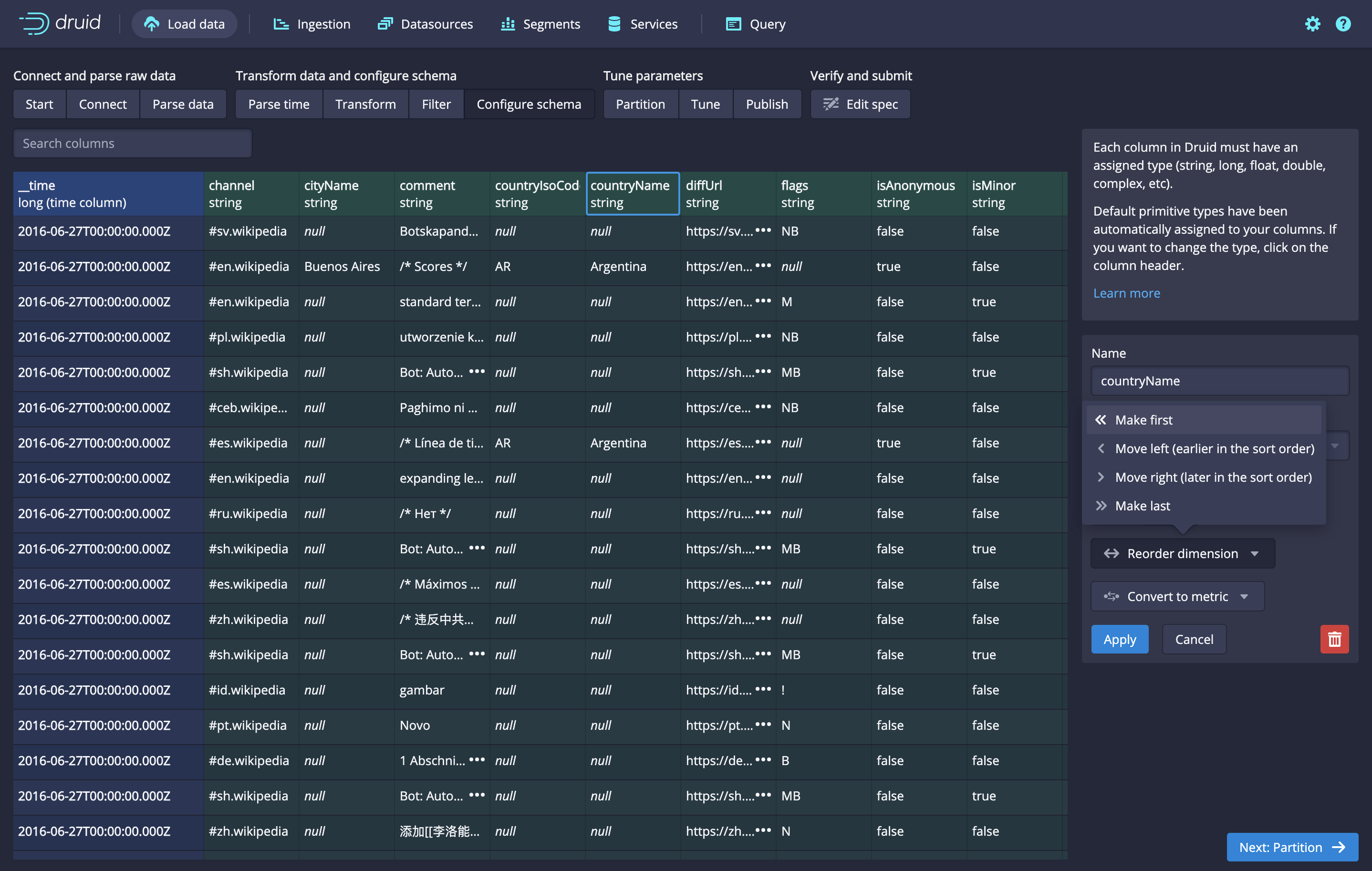
# The column order in the Schema table matches the dimensionsSpec
The Schema table now reflects the dimension ordering in the dimensionsSpec.
# Metrics
# Coordinator duty runtime metrics
The coordinator performs several 'duty' tasks. For example segment balancing, loading new segments, etc. Now there are two new metrics to help you analyze how fast the Coordinator is executing these duties.
coordinator/time: the time for an individual duty to executecoordinator/global/time: the time for the whole duties runnable to execute
# Query timeout metric
A new metric provides the number of timed out queries. Previously timed out queries were treated as interrupted and included in the query/interrupted/count (see Changed HTTP status codes for query errors for more details).
query/timeout/count: the number of timed out queries during the emission period
# Shuffle metrics for batch ingestion
Two new metrics provide shuffle statistics for MiddleManagers and Indexers. These metrics have the supervisorTaskId as their dimension.
ingest/shuffle/bytes: number of bytes shuffled per emission periodingest/shuffle/requests: number of shuffle requests per emission period
To enable the shuffle metrics, add org.apache.druid.indexing.worker.shuffle.ShuffleMonitor in druid.monitoring.monitors. See Shuffle metrics for more details.
# New clock-drift safe metrics monitor scheduler
The default metrics monitor scheduler is implemented based on ScheduledThreadPoolExecutor which is prone to unbounded clock drift. A new monitor scheduler, ClockDriftSafeMonitorScheduler, overcomes this limitation. To use the new scheduler, set druid.monitoring.schedulerClassName to org.apache.druid.java.util.metrics.ClockDriftSafeMonitorScheduler in the runtime.properties file.
# Others
# New extension for a password provider based on AWS RDS token
A new PasswordProvider type allows access to AWS RDS DB instances using temporary AWS tokens. This extension can be useful when an RDS is used as Druid's metadata store. See AWS RDS extension for more details.
# The sys.servers table shows leaders
A new long-typed column is_leader in the sys.servers table indicates whether or not the server is the leader.
# druid-influxdb-emitter extension supports the HTTPS protocol
See Influxdb emitter extension for new configurations.
# Docker
# Small docker image
The docker image size is reduced by half by eliminating unnecessary duplication.
# Development
# Extensible Kafka consumer properties via a new DynamicConfigProvider
A new class DynamicConfigProvider enables fetching consumer properties at runtime. For instance, you can use DynamicConfigProvider fetch bootstrap.servers from location such as a local environment variable if it is not static. Currently, only a map-based config provider is supported by default. See DynamicConfigProvider for how to implement a custom config provider.
# Bug fixes
Druid 0.21.0 contains 30 bug fixes, you can see the complete list here.
# Post-aggregator computation with subtotals
Before 0.21.0, the query fails with an error when you use post aggregators with sub-totals. Now this bug is fixed and you can use post aggregators with subtotals.
# Indexers announce themselves as segment servers
In 0.19.0 and 0.20.0, Indexers could not process queries against streaming data as they did not announce themselves as segment servers. They are fixed to announce themselves properly in 0.21.0.
# Validity check for segment files in historicals
Historicals now perform validity check after they download segment files and re-download automatically if those files are crashed.
# StorageLocationSelectorStrategy injection failure is fixed
The injection failure while reading the configurations of StorageLocationSelectorStrategy is fixed.
# Upgrading to 0.21.0
Consider the following changes and updates when upgrading from Druid 0.20.0 to 0.21.0. If you're updating from an earlier version than 0.20.0, see the release notes of the relevant intermediate versions.
# Improved HTTP status codes for query errors
Before this release, Druid returned the "internal error (500)" for most of the query errors. Now Druid returns different error codes based on their cause. The following table lists the errors and their corresponding codes that has changed:
| Exception | Description | Old code | New code |
|---|---|---|---|
| SqlParseException and ValidationException from Calcite | Query planning failed | 500 | 400 |
| QueryTimeoutException | Query execution didn't finish in timeout | 500 | 504 |
| ResourceLimitExceededException | Query asked more resources than configured threshold | 500 | 400 |
| InsufficientResourceException | Query failed to schedule because of lack of merge buffers available at the time when it was submitted | 500 | 429, merged to QueryCapacityExceededException |
| QueryUnsupportedException | Unsupported functionality | 400 | 501 |
There is also a new query metric for query timeout errors. See New query timeout metric for more details.
# Query interrupted metric
query/interrupted/count no longer counts the queries that timed out. These queries are counted by query/timeout/count.
# context dimension in query metrics
context is now a default dimension emitted for all query metrics. context is a JSON-formatted string containing the query context for the query that the emitted metric refers to. The addition of a dimension that was not previously alters some metrics emitted by Druid. You should plan to handle this new context dimension in your metrics pipeline. Since the dimension is a JSON-formatted string, a common solution is to parse the dimension and either flatten it or extract the bits you want and discard the full JSON-formatted string blob.
# Deprecated support for Apache ZooKeeper 3.4
As ZooKeeper 3.4 has been end-of-life for a while, support for ZooKeeper 3.4 is deprecated in 0.21.0 and will be removed in the near future.
# Consistent serialization format and column naming convention for the sys.segments table
All columns in the sys.segments table are now serialized in the JSON format to make them consistent with other system tables. Column names now use the same "snake case" convention.
# Known issues
# Known security vulnerability in the Thrift library
The Thrift extension can be useful for ingesting files of the Thrift format into Druid. However, there is a known security vulnerability in the version of the Thrift library that Druid uses. The vulerability can be exploitable by ingesting maliciously crafted Thrift files when you use Indexers. We recommend granting the DATASOURCE WRITE permission to only trusted users.
# Permission issues in running the docker-based Druid cluster
If you run the Druid docker cluster for the first time in your machine, using the 0.21.0 image can create internal directories with the root account. As a result, Druid services can fail due lack of permissions. This issue is filed in #11166.
If you are using docker compose, you can use the below commands to work around this issue. These commands will create internal directories first using an old image and then start services using the 0.21.0 image.
$ cd ${PREV_SRC_DIR}
$ docker-compose -f distribution/docker/docker-compose.yml create
$ cd ${0.21.0_SRC_DIR}
$ docker-compose -f distribution/docker/docker-compose.yml upIf you are not using docker compose, you can directly pass the volume parameter for /opt/druid/var when you start services using the 0.21.0 image. For example, you can run the command below to start the coordinator service.
$ docker run -v /path/to/host/dir:/opt/druid/var apache/druid:0.21.0 coordinatorFor a full list of open issues, please see Bug .
# Credits
Thanks to everyone who contributed to this release!
@a2l007
@abhishekagarwal87
@asdf2014
@AshishKapoor
@awelsh93
@ayushkul2910
@bananaaggle
@capistrant
@ccaominh
@clintropolis
@cloventt
@FrankChen021
@gianm
@harinirajendran
@himanshug
@jihoonson
@jon-wei
@kroeders
@liran-funaro
@martin-g
@maytasm
@mghosh4
@michaelschiff
@nishantmonu51
@pcarrier
@QingdongZeng3
@sthetland
@suneet-s
@tdt17
@techdocsmith
@valdemar-giosg
@viatcheslavmogilevsky
@viongpanzi
@vogievetsky
@xvrl
@zhangyue19921010