Add support for sparse indexing [LUCENE-10396] #11432
Comments
|
Adrien Grand (@jpountz) (migrated from JIRA) One interesting question about this will be the read API. What I have in mind for now looks something like this: class SparseIndexProducer {
/**
* Get an iterator over ranges of doc IDs that may contain values that fall in the given range of values.
*/
DocIdRangeIterator getNumeric(FieldInfo field, long rangeMin, long rangeMax);
DocIdRangeIterator getSorted(FieldInfo field, long rangeMinOrd, long rangeMaxOrd);
DocIdRangeIterator getBinary(FieldInfo field, BytesRef rangeMin, BytesRef rangeMax);
}
class DocIdRange {
int first, last;
}
class DocIdRangeIterator {
/**
* Return the next range of doc IDs so that range.min is greater than or equal to the target.
*/
DocIdRange advance(int target);
} |
|
Robert Muir (@rmuir) (migrated from JIRA) an entire new file format abstraction for this one slow range query? is there any other use-case for this data? I'm concerned about complexity, this seems VERY specialized. |
|
Adrien Grand (@jpountz) (migrated from JIRA) Actually I think it would help make things faster not slower. IndexSortSortedNumericDocValuesRangeQuery already outperforms PointRangeQuery for ranges that match lots of documents, even more if the range query doesn't run on its own but within a conjunction. I would like to generalize this mechanism for secondary and tertiary sorts when the previous sort fields have a low cardinality (e.g. an e-commerce index sorted by category then price). And fold this logic into our query factory methods and top field collectors so that range queries would automatically take advantage of index sorting when they see it. I think we'd almost be guaranteed to make queries faster by leveraging this sparse index in the following cases:
|
|
Robert Muir (@rmuir) (migrated from JIRA) thanks @jpountz. I like that there is a sort use-case as well, although it is still an advanced/complex case (multi-field sort). What about facets (range or otherwise)? |
|
Adrien Grand (@jpountz) (migrated from JIRA) To clarify, I was thinking of the case when a user sorts on a single field at search time, which happens to be the secondary sort field on the index sort. Good question about range facets. Maybe it could help a bit in the sense that we could use this data structure to know that all docs within a range of doc IDs would go to a given bucket, and then we'd just need to count these documents, we wouldn't even have to look at their associated value. |
|
Adrien Grand (@jpountz) (migrated from JIRA) I'm also wondering if this could help better support pre-filtering with NN vectors. We could use these sparse indexes to produce Bits representations of the set of matching doc IDs that consist of a union of ranges, which we could then pass to the HNSW search logic as live docs? |
|
Adrien Grand (@jpountz) (migrated from JIRA) Another potential use-case we are interested in for Elasticsearch would be to have the ability to visit a single document per field value for a field that is the primary index sort. This has a few applications, one of them is to compute the number of unique values of this primary sort field for documents that match a query. The collector could implement |
|
Ignacio Vera (@iverase) (migrated from JIRA) I have been thinking on the ability if visiting a single documents per field value as explained for Adrien above and I think we can implement it in a not intrusive way for SortedDocValues that have low cardinality. The idea is to add the following method to the SortedDocValues api with a default implementation: /**
* Advances the iterator the the next document whose ordinal is distinct to the current ordinal
* and returns the document number itself. It returns {`@link`
* #NO_MORE_DOCS} if there is no more ordinals distinct to the current one left.
*
* <p>The behaviour of this method is <b>undefined</b> when called after the iterator has exhausted and may result in unpredicted behaviour.
*
* The default implementation just iterates over the documents and manually checks if the ordinal has changed but
* but some implementations are considerably more efficient than that.
*
*/
public int advanceOrd() throws IOException {
int doc = docID();
if (doc == DocIdSetIterator.NO_MORE_DOCS) {
return doc;
}
final long ord = ordValue();
do {
doc = nextDoc();
} while (doc != DocIdSetIterator.NO_MORE_DOCS && ordValue() == ord);
assert doc == docID();
return doc;
}When consuming the doc values, if the field is the primary sort of he index and the cardinality is low (average of documents per field >64?), then we will use a DirectMonotonicWriter to write the offset for each ord which should not use too much disk space. When producing the doc value, we will override this method with a faster DirectMonotonicReader implementation. |
|
Ignacio Vera (@iverase) (migrated from JIRA) I open a draft PR that shows the idea I exposed above. |
|
Robert Muir (@rmuir) (migrated from JIRA) If you just need the first document with the each value, why not use postings/TermsEnum? |
|
Ignacio Vera (@iverase) (migrated from JIRA) If I understand you correct, you mean leveraging the inverted index to get the first document per term. I tried that and my conclusion was that it was slower than manually iterate the doc values. |
|
Robert Muir (@rmuir) (migrated from JIRA) do we have any idea of the comparison? I'm just curious because it seems like doing TermsEnum.next() and getting first doc ID should be relatively optimized. The nice thing about it, is that it can already be done today without adding additional datastructures and APIs. The docvalues advanceOrd is a bit of a mismatch for column data structure, it seems like an inverted structure is more appropriate for this. |
|
Robert Muir (@rmuir) (migrated from JIRA) Also if performance changes are minor between the two solutions, perhaps we could speed terms/postings up for the sorted case to close the gap. For example, in the sorted case we could consider always writing SingletonDocID, and because of sorting, it could be delta-encoded. |
|
Ignacio Vera (@iverase) (migrated from JIRA) Here is the code I am using when using postings/TermsEnum from the inverted index which might be totally wrong / inefficient as unfortunately I am not an expert in this area: // position the terms enum on the current term
termsEnum.seekExact(sortedDocValues.lookupOrd(sortedDocValues.ordValue()));
// advance
if (termsEnum.next() == null) {
doc = sortedDocValues.advance(DocIdSetIterator.NO_MORE_DOCS);
} else {
termsEnum.postings(postingsEnum);
doc = sortedDocValues.advance(postingsEnum.nextDoc());
}This code performs ok for lower cardinality but it becomes slow for high cardinality. Similar to what I have done in the linked PR, I have indexed 50 million documents in a sorted index. The documents contain a SortedDocValues with a 10 bytes term and the term is indexed using a StringField as well. I checked the index size and the speed of retrieving the first document per term with different cardinalities and the results looks like: |
|
Robert Muir (@rmuir) (migrated from JIRA) The slowness is probably the lookupOrd? Can you avoid this? Just next() the termsenum to move on to the next ord. |
|
Robert Muir (@rmuir) (migrated from JIRA) I'd also modify the call to |
|
Ignacio Vera (@iverase) (migrated from JIRA) > The slowness is probably the lookupOrd? Can you avoid this? Just next() the termsenum to move on to the next ord. Not really because the call to advance can move the SortedDocValues iterator to a different ordinal. We need to position our TermsEnum in each call. That's one of the advantage of my proposal as everything advances together. > I'd also modify the call to termsEnum.postings() to be termsEnum.postings(postingsEnum, PostingEnum.NONE) I will try that and I will report back. |
|
Ignacio Vera (@iverase) (migrated from JIRA) More exactly, the SortedDocValues iterator might have been advanced to a different ordinal. |
|
Robert Muir (@rmuir) (migrated from JIRA) I don't understand why you are starting from an ordinal at all? it seems a bit of an XY problem. Doesn't the task start with a term (e.g. bytes or text)? the two terms dictionaries are "aligned". if you are just gonna next() thru the terms of the terms dict, you can make |
|
Robert Muir (@rmuir) (migrated from JIRA) In fact, i don't see any need to involve docvalues at all for this feature. You can go thru terms dict and just read the first docID() of the first posting for each term and then you know how the terms map to these docid "ranges". No need to read the whole postings list, just get the first doc, since the index is sorted. No need to consult docvalues at all. This could be another way to implement whatever it is you are doing, that's what i referred to as "XY" problem. It seems to me, for mapping terms to ranges of documents for a sorted index, that the inverted index is the correct data structure. But maybe again, we need to optimize something here so that getting that first doc is even faster for dense terms for this use case: e.g. inlining SingletonDocID (delta) for terms when the index is sorted on the field, so that its all super-efficient solely from the terms dictionary. |
|
Ignacio Vera (@iverase) (migrated from JIRA) I think you are assuming that we always visit all terms in the index. The iteration might be driven by the result of a query that contains a subset of the documents. In pseudo-code would look like: DocIdSetIterator iterator = executeQuery();
SortedDocValues sortedDocValues = getSortedDocValues();
int doc = iterator.nextDoc();
while (doc != DocIdSetIterator.NO_MORE_DOCS) {
if (sortedDocValues.advanceExact(doc)) {
BytesRef bytesRef = sortedDocValues.lookupOrd(sortedDocValues.ordValue());
consume(bytesRef);
// advance our iterator to the next document with different ordinal
doc = iterator.advance(sortedDocValues.advanceOrd());
} else {
doc = iterator.nextDoc();
}
}I don't see how to do this efficiently with the inverted index only. |
|
When fields are sorted on numeric values, it could be possible to use a learned-index approach instead of raw binary search, something like the PGM Index. It is very compact (something like 0.02% of the indexed values) and 2x to 3x faster than binary search. |
On Elasticsearch we're more and more leveraging index sorting not as a way to be able to early terminate sorted queries, but as a way to cluster doc IDs that share similar properties so that queries can take advantage of it. For instance imagine you're maintaining a catalog of cars for sale, by sorting by car type, then fuel type then price. Then all cars with the same type, fuel type and similar prices will be stored in a contiguous range of doc IDs. Without index sorting, conjunctions across these 3 fields would be almost a worst-case scenario as every clause might match lots of documents while their intersection might not. With index sorting enabled however, there's only a very small number of calls to advance() that would lead to doc IDs that do not match, because these advance() calls that do not lead to a match would always jump over a large number of doc IDs. I had created that example for ApacheCon last year that demonstrates the benefits of index sorting on conjunctions. In both cases, the index is storing the same data, it just gets different doc ID ordering thanks to index sorting:
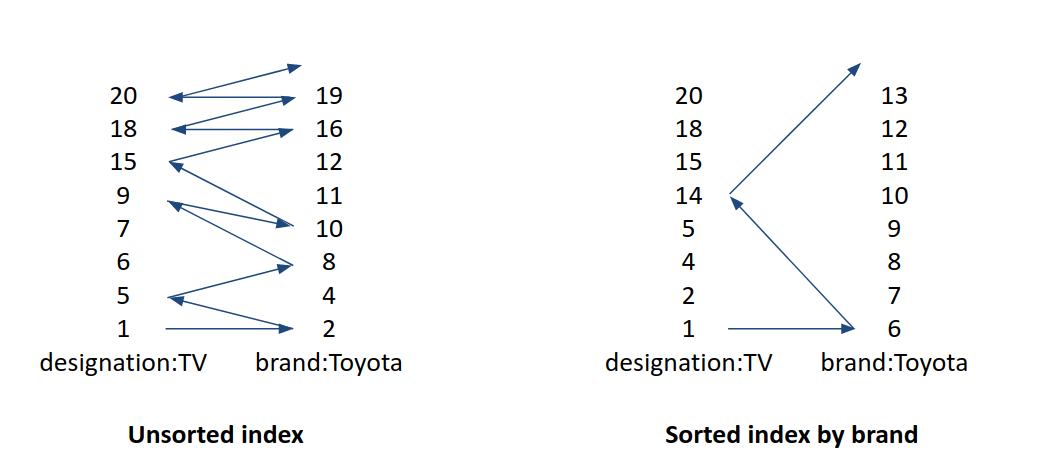
While index sorting can help improve query efficiency out-of-the-box, there is a lot more we can do by taking advantage of the index sort explicitly. For instance
IndexSortSortedNumericDocValuesRangeQuerycan speed up range queries on fields that are primary sort fields by performing a binary search to identify the first and last documents that match the range query. I would like to introduce sparse indexes for fields that are used for index sorting, with the goal of improving the runtime ofIndexSortSortedNumericDocValuesRangeQueryby making it less I/O intensive and making it easier and more efficient to leverage index sorting to filter on subsequent sort fields. A simple form of a sparse index could consist of storing every N-th values of the fields that are used for index sorting.DocValuesSkipperto be able to skip many docs at once: Add levels to DocValues skipper index #13563DocValuesSkipperinSortedSetDocValuesRangeQueryTake advantage of the doc value skipper when it is primary sort #13592DocValuesSkipperinNumericLeafComparator#13838Migrated from LUCENE-10396 by Adrien Grand (@jpountz), updated Jun 29 2022
Attachments: sorted_conjunction.png
Pull requests: #979
The text was updated successfully, but these errors were encountered: