{kind=link}
Kddl is intended to be a Swiss army knife for database models.
It takes a model or a running datasource as input, and an output format (current valid outputs are postgresql, kddl and plantuml).
Kddl is multiplaform (jvm, js, native) and can be used as a standalone application or as a library. The reverse engineering feature is only available on the jvm platform for now.
This tool is fully functional but is still in its infancy, it should gain many more features and formats over time. If you try it, be sure to give some feedback!
kddl [OPTIONS] > [output_file]
Options:
-i, --input -> mandatory; input file or JDBC URL (with credentials)
-f, --format -> mandatory; output format (value should be one of [kddl, plantuml, postgresql])
-d, --driver -> jdbc driver, needed when input is a JDBC URL (classname, must be present in the classpath)
-q, --quoted -> quoted identifiers
-u, --uppercase -> uppercase identifiers
-h, --help -> Usage info
Here's the example.kddl file, which should be enough to understand the syntax by example.
click to expand
// Definition for database geo// Supported data types: // boolean, integer, serial, long, float, double, numeric(n,p), money, // time, date, datetz, datetime, datetimetz, char, char(*n), varchar(n), text, // enum( 'value1' [,] 'value2' ...), blob, clob
// a database contains options and schemas database geo {
// a schema contains tables and links schema infra {
// a table contains fields, either given a type or a destination table table zone { *code varchar(10) // '*' stands for 'part of pk', otherwise pk is generated as needed !name varchar(50) // '!' stands for unique description text? // '?' stands for nullable field active boolean = false // default value } table department : zone // inherit a table from another (for engines which support table inheritance like PostgresQL) table city : zone { hasTrain boolean? } // declarations can be inlined table link { distance integer src_id --> zone // mandatory foreign key field dst_id --> zone hub_id --> zone? (down) // nullable foreign key field } city *--> department (up) // plantuml arrow direction can be specified}
schema client {
table contact { // no primary key definition; see below // gender, lastname, firstname // field types are optional for plantuml (use a coma to disambiguate) gender char? // field types are mandatory for postgresql firstname varchar(200) lastname varchar(200) } table location { name varchar(50) = 'untitled' // string literals use single quotes nature enum('depart', 'arrival') // enum types address text? } location *--> contact // will generate the implicit "contact_id serial" primary key in contact location *--> infra.zone // foreign key referencing a table in another schema}
}
To generate the plantuml graph definition script for this model, do:
kddl -i example.kddl -f plantuml > example.pu
plantuml -Tpng example.puAnd here's the result:
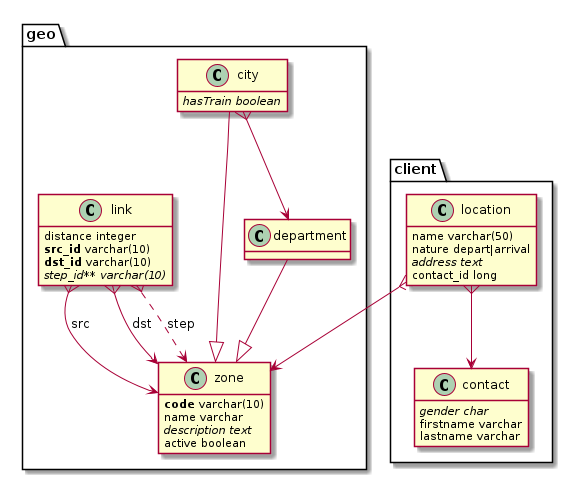
You may need to install plantuml, with something like sudo apt install plantuml on linux platforms.
To generate the PostgreSQL creation script for this model, do:
kddl -i example.kddl -f postgresql > example.sqlTo do the reverse, aka generate the kddl model file from a running JDBC database, you can do:
kddl -i jdbc://...<jdbc URL with credentials> -f kddl > output.kddl
You'll need to have gradle installed.
You first need to clone this repository and launch the install.sh script, which will build and install the kddl library in your local maven repository.
git clone https://github.com/arkanovicz/kddl.git
cd kddl
./install.shTo install the kddl command everywhere, assuming that ~/bin is in your path, do:
ln -s ~/<path_to_kddl_repository>/kddl.sh ~/bin/kddlPlease adapt the installation and run scripts.
$ ./gradlew build
- document library usage
- plugins for gradle [done in skorm] / maven
- db versionning handling (generation of update scripts from previous version, aka sql patches from two model versions)
- custom types
- more tests (for instance: inheritance from another schema's table)
- align fields (add a space if no field prefix)
- kddl files inclusions
- support enum(foo,bar) (without quotes) or juste foo|bar
- support merging of relations like: Service -- Carrier --* User
- handle enum names collisions
- option to reset target schema or not
- a field can be implied in one foreign key at most (but it may be a good practice...)
- multivalued foreign keys fields must be named after target primary key fields (quite the same...)
- enum fields of the same name share the same values (also a good practice!)