Udacity nanodegree Project 3 - Behavior cloning Teaching a car to drive himself
Full report at: https://medium.com/@arnaldogunzi/teaching-a-car-to-drive-himself-e9a2966571c5#.8rzolwdnl
#Report on Udacity Project 3 — Behavior Cloning
#1. Objective
In the Project 3 of Udacity Self-Driving car nanodegree (www.udacity.com), we’re invited to design a system that drives a car autonomously in a simulated environment.
Illustration of the simulator

As a input, we’re given a simulator, a video-game. We use keyboard or joystick to drive around the circuit. The simulator records screen shots of the images and the decisions we made: steering angles, throttle and brake.
The mission is to create a deep neural network to emulate the behavior of the human being, and the put this network to run the simulator autonomously.
Inputs: Recorded images and steering angles Outputs: Predicted steering angles What to do: Design a neural network that successfully and safely performs the circuit by himself
Easy? No!
Look at my first attempt to do this project. The car fell in the river! Dozen of other attempts also failed: car out of the road, crashed in the bridge, and so on.
First of endless failed attempts
#2. Introduction: What the system must do
Something easy for a human being (recognition of images and correspondent steering angle) is very very hard for a computer.
##2.1 Image recognition and decision of steering angle
Image recognition of non-structured files is a hard task for a computer. For us, it is almost impossible not to see an image and recognize what is inside it. But, for a computer, a image is just a bunch of numbers. More specifically, it is an array of numbers for 0 to 255, in the three channels (Red, Green, Blue), for each pixel of the image.

What are the relevant features of a image to decide the steering angle? Are the clouds in the sky relevant? Is the river important? Are the lanes important? Or the colors of the road? What happens in the part of the circuit where there are not lines (like the dirty exit below?). These are trivial questions for humans, but a machine must be trained to consider the right features.

The problem is hard. This tutorial is also extensive. Be comfortable to jump sessions if necessary. I stressed also points that do not work. We learn more from mistakes than successes.
##2.2 The approach and tools
There are several possible methods to try to solve the problems above. The approach suggested by Udacity was to use image processing and deep neural networks.
The tools used were Keras (a wrapper running over Tensor Flow), OpenCV (to do some image transformations), numpy (matrix operations) and python (to put all these things together).
#3. Analysis of the images
The first input are images of a camera inside the car. There are three cameras: center, left and right.


Example of center and left cameras The second input is a csv file, each line containing the name of the correspondent image, steering angle, throttle, brake. The steering angle is normalized from -1 to 1, corresponding in the car to -25 to 25 degrees. The data provided by Udacity has 8036 images from each camera, resulting in 24108 images. In addition to it, we can generate our own data.
The bad news. Just input raw images to the network will not work.
Most of the images has the equivalent of zero steering angle. The curves are misrepresented, because most of time the car goes straight.
The network will not converge to a good solution. We have to preprocess the data: to do what is called “image augmentation”.
#4. Image augmentation
##4.1 Center and lateral images
So, we have data from lateral cameras. But what to do with it?
Following a suggestion from the great carND forum (by the way, almost all of these tips are from there), I added a correction angle of 0.10 to the left image, and -0.10 to the right one. The idea is to center the car, avoid the borders. ##4.2 Flip images
Another excellent tip. We can randomly choose to flip the image, and invert the steering angle. This way, we can neutralize some tendency of the human driver that drove a bit more to the left or to the right of the lane.

Original and flipped image
if np.random.uniform()>0.5:
X_in[i,:,:,:] = cv2.flip(X_in[i,:,:,:],1)
Y_in[i] = -p[i] #Flipped images
Be carefill to use the function correctly. Flip with parameter zero will do a wrong thing.

##4.3 Random lateral perturbation The idea is to move to image a randomly a bit to the left or the right, and add a proportional compensation in the angle value. In the end, I didn’t used this approach, but it is a good idea.
pix2angle = -0.05 #Opposed direction latShift = random.randint(-5,5) M = np.float32([[1,0,latShift],[0,1,0]]) imgTranslated = cv2.warpAffine(img,M,(img.shape[1],img.shape[0]))

##4.4 Resize
Because of computational limits, it is a good thing to resize the images, after cropping it. Using the size of NVIDIA paper (66 x 200 pixels) my laptop went out of memory. I tried (64 x 64), (64 x 96), (64 x 128)…
I also reduced the size of the stride of the convolutional layers. Since the image is smaller, the stride can also be smaller.


Because inside the model a image is just a matrix, a numpy command easily do this operation.
crop_img = imgRGB[40:160,10:310,:] #Throwing away to superior portion of the image and 10 pixels from each side of the original image = (160, 320)
It makes sense to do the transformations (like the lateral shift) before the cropping, since we’re losing information. Doing the opposite, we will feed the model with an image with a lateral black bar.
##4.6 Grayscale, YUV, HSV
I tried grayscale, full color, the Y channel of YUV, S channel of HSV…
All of this because my model wasn’t able to avoid the dirty exit after the bridge, where there is not a clear lane mark in the road.
Some conversion commands:
imgOut = cvtColor(img, cv2.COLOR_BGR2YUV) imgOut = cvtColor(img, cv2.COLOR_BGR2HSV)
S channel of Image in HSV formatBut the real problem was that OpenCV (cv2.imread command) reads a image in BGR, and the code in drive.py, in RGB. I used the conversion command of opencv to transform the image in RGB.
imgOut = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)

model.add(Convolution2D(1,1,1, border_mode = ‘same’,init =’glorot_uniform’,input_shape=(size1,size2,3)))
##4.7 Normalization Normalization is made because the neural network usually works with small numbers: sigmoid activation has range (0, 1), tanh has range (-1,1).
Images have 3 channels (Red, Green, Blue), each channel has value 0 to 255. The normalized array has range from -1 to 1.
X_norm = X_in/127.5–1
#5. Neural Networks
##5.1 Architecture Once the image processing and augmentation is done, it is time to design the Neural Network (NN) . But there are an infinite number of architectures of neural networks.
As a starting point, I used the NVIDIA End-to-End model (https://arxiv.org/abs/1604.07316), that has the configuration described below.
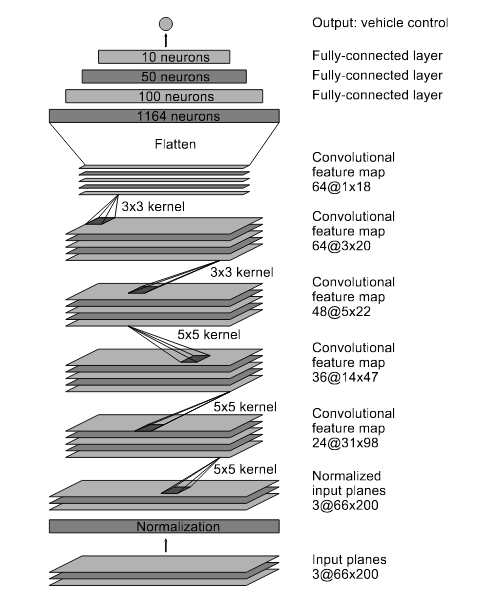
We can broadly describe the tasks of the NN in two: recognize relevant features and predict the steering angle. The recognition of features is carried by convolutional layer What is a convolution? A convolution operation is like a window that slides across the image and does a dot product. It works as a recognizer of some feature. For example, if the convolution of a triangle, the portion of the image that has that triangle will have maximum value, while some totally uncorrelated image will have minimum value. Source http://stats.stackexchange.com/questions/116362/what-does-the-convolution-step-in-a-convolutional-neural-network-doWhy so many convolutional layers? Each convolutional layer is a level of abstraction above the previous layer. As an analogy, the first layer recognizes the parts of a car, the second layer recognizes the car, the third layer recognizes the scenario with the car, and so on.
It is important to stress that we do not give the explicit features the image has to recognize. It is automatically done by the back-propagation of the neural network. It has some pros and cons. The pro is that we just feed the network. The con is that if it not work, we don’t have idea of why it didn’t work — is the network too small? Too big?
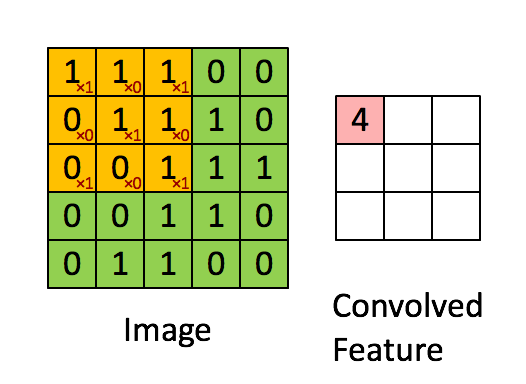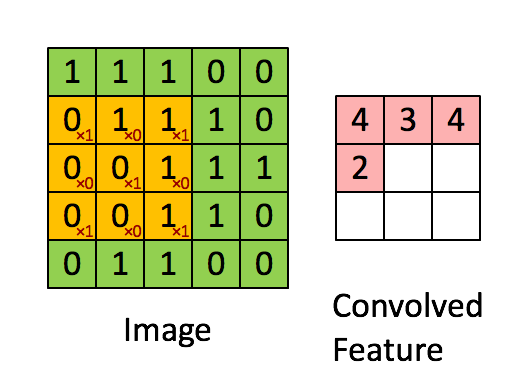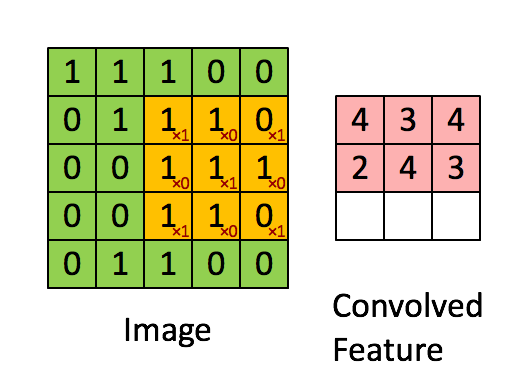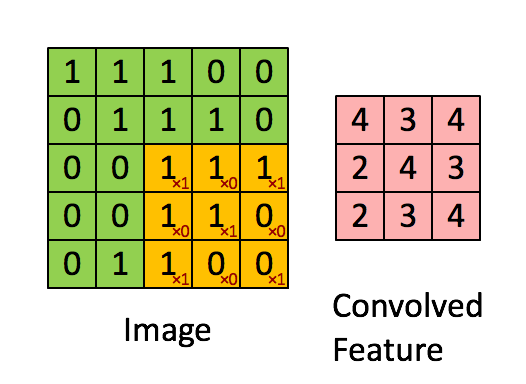
Given the features, how to decide about the steering angle?
It is done by fully connected layers after the convolutional ones. The matrix is flattened, because the spatial information of rows and columns doesn’t matter any longer. The NN is like a function that is feed with images, and for each image, give the steering angle as steering angle, which is compared to the angle of the human driver.
Another thing to note is that these techniques are very new. Much of these concepts are not well understood and consolidated. It is at the same time good, because we are at the frontier of knowledge, and scary, because sometimes we simply don’t know if something works or not.
##5.2 Loss error function
How to compare the predicted and actual angles?
Again, lots of choices: mean absolute error, mean squared error. To do not complicate much, and because it makes little difference at all, I used mean squared error. This value is just an indicator. The real test is if the the car really drives the circuit.
model.compile(optimizer=Adam(lr=LEARNING_RATE), loss=’mse’)
##5.3 Bigger / Smaller networks Because the NVIDIA model is heavy, I tried a smaller network. How small, or how big, is a one million (perhaps more) question. There’s no exact approach to decide this. Just some broad indicators: a too small network will not learn the solution, a too big network will overfit. There is a range that works well. And the way to find the model is testing endless combinations…
##5.4 Dropout A dropout layer, with probability of 50%, was used, after the first full connected layer. The idea of the dropout layer is very interesting. The network must be robust enough to do the forecast (or to clone the behavior) even without some of this connections. It is like trying to recognize an image just looking at parts of it. The 50% says only random half of the neurons in that layer will be kept in a fitting step. If it were 20%, it will keep 80% of the neurons in Keras. In TensorFlow, it is the opposite, 20% will be kept.
It is good to avoid overfitting. The network can be memorizing wrong features of the image. Memorize the trees of the road is a bad generalization. Dropout helps to avoid it.
Why dropout just the first full conected layer? And why 50%? Actually, there are several other possible solutions. There is no right single answer, a lot of this is empirical.
##5.5 Learning rate
A learning rate of 0.001 was used, with Adam optimizer. Adam optimizer is a good choice in general, because it fine tunes the learning rate automatically.
Source: https://www.quora.com/In-an-artificial-neural-network-algorithm-what-happens-if-my-learning-rate-is-wrong-too-high-or-too-lowToo small learning rate, and the model will not learn. Too big, and it will diverge. It remembers me a passage from Sun Tzu, something like this: If the front troops go to fast, the rear troops will be separated. If everyone goes too slow, we’ll not reach our destination.

##5.6 Activation function I tried tanh, because it has output range from -1 to 1. But there were convergence problems. The evidence of it was that the car had zero degree output. Or only 25 degree output. This is the vanishing gradient phenomena, where the gradient in the backpropagation process comes to zero and the neuron dies.
ELU activation function proved superior. This paper discusses that ELU is better than RELU, a function that avoids vanishing gradient but keeps the non-linearity of the network. (http://www.picalike.com/blog/2015/11/28/relu-was-yesterday-tomorrow-comes-elu/). There are other activation functions that can work, but I tested only these two.
Neural networks need data. High quality and big volume of data. In this case, Udacity provided a dataset to work on. But to complement it, we could also collect new data, by playing the simulator as a video-game and recording it.
There are two ways to control the car in the simulator: keyboard or joystick.
-
Keyboard: not recommended, unless you are a very good gamer. It is because the angles are sharper than using joystick. The dataset will have a lot of zeros and a lot of high angles. And it will be hard to a NN to generalize it. Garbage in, garbage out.
-
Joystick: I borrowed a PS3 joystick and tried to record my data. Added the collected data to the one provided by Udacity. But I’m a so horrible gamer that my data was useless. It gave a worst result. I threw it away and used only Udacity data. But, in general, if you are able to collect good data, it will make the NN task easier.
Some practical, useful tips for this project
Usually, training NN requires a large quantity of data. To load all of this in memory can take forever and exhaust the resources. I have a laptop with 8 Gb RAM. If I tried to load 24.000 colored images, it ran out of memory.
The Keras data generator function allows to load an train just a manageable amount of data per time. It means there we can use memory to perform other more critical tasks than just storing a large number of images. It is a great tool.
def generator(nbatch): … Load nbatch images and do the processing yield X_norm, Y_norm #Yield is the “return” for generators
Use of generator:
n_epoch =15 for e in range(n_epoch): print(“ETAPA %d” % e) for X_train, Y_train in generator(2000): model.fit(X_train, Y_train, batch_size=200, nb_epoch=1, verbose=1, validation_split=0.20) model.save_weights(“model_” + str(e) + “.h5”)
A naive mistake is to insert an activation function in the last layer. Since every layer has a non-linear activation, why not the last one?
The activation function introduces a non-linearity in the model. It is the feature that allows the network to do very hard generalizations. By backpropagation method, an correction proportional to the derivative of this activation function is done.
The NN of this model has several layers, thousands of neurons… and finishes with one single neuron. If it has activation, a non-linear correction will be backpropagated to the thousands of neurons behind. A small variation in the last neuron has great variation in the first layer. A non-linear variation in the last neuron will make the model oscillate like crazy among epochs, and can make convergence impossible.
There are so many hyper parameters that it becomes exponentially impossible to test all combinations.
Because it is a hard problem, and because it requires an expensive computational power, it is highly recommended to use the power of GPUs (Graphic Processing Units).
From the basic computer architecture, we find that there is a CPU, input devices (mouse, keyboard) and output devices (monitor, printer). With the evolution of computers, mainly because of the video-games, the graphics displayed in the computer became more and more complex, with more resolution. One solution designed to allow these heavy graphics was the GPUS.
A CPU is like a car. It moves very fast and transports few data. A GPU is like a train. It is slower than CPU, but transports several times more data. If you need to move millions of people, it is better to have a subway than to move them by car.
It was a hard task to install the drivers to use the GPU. Several days doing this. The first time, I got stuck in the login page that did not login anymore. Some panic at first, than some hours googling to solve the problem and I returned to zero… The following day, I tried another approach. Now it was succesfull.
The use of GPUs was the difference between a reasonable time to solve the problem versus an impossible requirement of time. One single run of the model was taking 40 minutes in CPU, versus a bit more than 10 minutes in GPU. It makes a huge difference, when you work full time, have two little daughters and precious few hours per night to work on something else.
Besides the speed gain, there is the memory gain. My laptop has 8 Gb Ram. The video card (NVIVIA GeForce 920M), 2 Gb. It is like I was given an additional 2 Gb memory. With only CPUs, I couldn’t work on anything besides the model, because 100% of the resources where allocated on it. With GPU, I can run the model and do other things at the same time.
Using GPU is magic. Is like to give a Coke to someone in the desert. Or to buy a new car — the feeling of ‘how I was using that crap old one’. Or to find a shortcut in the route to the office: you’ll never use the long route again. Or to find a secret code in a game that give superpowers… 7.4 Save epochs and Load saved ones
A good tip is to save the epochs. Not every epoch, but something like each 3 epochs, like the code below. Because the NN fit takes so long, it is frustrating to spend half an hour running a model to discover it doesn’t work.
Too few epochs, and the model doesn’t generalize. Too many epochs, it can overfit. With saved epochs, at least you can have information about the behavior of different epochs.
if e % 3 ==0: #Save each 3 epochs model.save_weights(“model_” + str(e) + “.h5”)
The code below allows to load a saved weight. It it very useful, to keep the optimization from some saved point.
model.load_weights(“model.h5”)
I already cited the RGB BGR confusion. Other point of confusion is the sizes of images in OpenCV. I was wrongly confounding rows and columns. It is a good advice to do a double check. In general, each step in OpenCV must be checked visually, in Jupyter notebook for example. There are so many details, and one single wrong detail is able to mess everything.
Because there is one file to create the model and other to run it on simulator, every image transformation done in one must be done in the other. It is obvious, but I lost several days because the files were doing different transformations, and results didn’t made sense.
Udacity is an on-line platform. So there are not presential classmates to help, or discuss. The way to communicate to other is using foruns, facebook groups and studying other people’s projects in Github. Surely, it is not advised to copy someone’s project, but the idea is to understand different approaches and implement your own work.
In the college were I was graduated, nobody cheated. It was the honor code of the students. Here follows a link explaining it (in Portuguese): https://ideiasesquecidas.com/2016/04/05/confesso-que-colei/
Here is the Github link of this project. https://github.com/asgunzi/CarND-Simulator
And here is a video of the car performing the circuit. It still zig-zags a bit.
Teaching a car to drive, even in a controlled, very simplified environment, is not an easy task. The tools and techniques presented are very new. TensorFlow was released in dez 2015, for example.
Perhaps the task of driving is not easy, even for a human. I took almost one year to learn to drive: get used to the car, learn rules and so on.
Problems: Neural networks are still too heavy, requires too much computational power and processing. The design and training of the network is a painful process. The good side of it is that there are a lot of points to improve: there is still the whole future to be written!
I would like to thank Udacity for providing a so high level course in this emerging field, and a so great project.
This text was written while listening to “A Felicidade — Carminho canta Tom Jobim”. https://www.vituga.com/watch_video.php?v=YN56xhy6wRes
Arnaldo Gunzi — Consultant and Engineer Feb/2017
My personal blog: http://ideiasesquecidas.com
Udacity: https://www.udacity.com/
Tensor Flow: https://www.tensorflow.org/
Keras: http://keras.io/
Numpy, Scikit Learn: http://scikit-learn.github.io/stable
NVIDIA End-to-End: https://arxiv.org/abs/1604.07316
Le Cun paper: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
ELU: http://www.picalike.com/blog/2015/11/28/relu-was-yesterday-tomorrow-comes-elu/
Dropout: https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf