Time: add setitem and missing value support (masking) #6028
Conversation
There was a problem hiding this comment.
This looks quite good. I tried to focus on high-level concerns only for now, and these are partially addressed in the comments. Mostly,
- We need to be careful with how we interact with
location - We should ensure we don't get performance regressions
- We need a way to pass in a mask; I'm not sure I like using
jd2=nanon input -- that would be an internal implementation detail.
Bit more comments in the main thread.
astropy/time/core.py
Outdated
| except Exception: | ||
| raise ValueError('cannot convert value to a compatible Time object') | ||
|
|
||
| if self.location != value.location: |
There was a problem hiding this comment.
location can be an array, in which case this statement would break. Now it is guaranteed that location is either a single element or an array with the correct shape, but the shape may have been broadcast, so one cannot just set an element. So, this needs some trickery.... But it also means in principle a different location is fine. Similarly, if value.location is None, I think it might be treated as OK if self.location is not None (but arguably only if self.location is a single element).
There was a problem hiding this comment.
I think that a non-scalar location is a corner case and that we could just raise an exception if either the self or value location is not a scalar or None. At least for now this would be fine and we can see if any users actually complain.
astropy/time/formats.py
Outdated
|
|
||
| @property | ||
| def jd2_filled(self): | ||
| return np.nan_to_num(self.jd2) |
There was a problem hiding this comment.
to ensure that the regular no-nan case is not slowed down too much:
return np.nan_to_num(self.jd2) if self.masked else self.jd2
There was a problem hiding this comment.
Yup, I had also thought about that.
astropy/time/formats.py
Outdated
| @@ -72,6 +73,11 @@ def _regexify_subfmts(subfmts): | |||
| return tuple(new_subfmts) | |||
|
|
|||
|
|
|||
| class TimeMaskedArray(np.ma.MaskedArray): | |||
There was a problem hiding this comment.
Why do we need a new class? It seems you want to avoid repr, but where is that a problem?
There was a problem hiding this comment.
Otherwise you get this:
In [9]: tm.cxcsec
Out[9]:
masked_array(data = [99.99999999999805 -- 299.999999999999],
mask = [False True False],
fill_value = 1e+20)
Instead of:
In [4]: tm.cxcsec
Out[4]: [99.99999999999805 -- 299.999999999999]
There was a problem hiding this comment.
But I think that's OK. Right now, if I don't mask anything, I get:
In [23]: Time(np.arange(50000, 50010), format='mjd').cxcsec
Out[23]:
array([-70329538.816, -70243138.816, -70156738.816, -70070338.816,
-69983938.816, -69897538.816, -69811138.816, -69724738.816,
-69638338.816, -69551938.816])
so why shouldn't a masked Time return a MaskedArray?
There was a problem hiding this comment.
I don't like the masked_array repr because:
- I don't need to see an explicit
data = .., which has--marking masked elements, ANDmask = [..], which is basically the same information. - The
fill_valueis just a silly thing to include. It is irrelevant most of the time. - The
data =is redundant. I know it is the data.
One can say this uses an old-school definition of repr, that it gives you the info to reproduce the object (although there it fails because it doesn't include dtype). But I think in this age of Jupyter notebook / interactive analysis, it is more important to have the object repr be a concise and visually-friendly representation of the object.
There was a problem hiding this comment.
For consistency it could be:
def __repr__(self):
return 'masked_array({})'.format(self)
There was a problem hiding this comment.
OK, got rid of the TimeMaskedArray wrapper.
|
For Now the above is obviously a bit elaborate, but while we perhaps could get rid of broadcasting, I think we should continue to allow single locations, especially as we will need to do the same for Now, given the need for dealing with attributes that do not necessarily share the objects shape, I think one way to make Also a suggestion: I think at some level setting items and having a mask are different issues; would it be an idea to decouple the two? If we do |
|
p.s. Obviously, just having For the mask, I think one decision we need to make is the extent to which this is a work-around for table, or general. E.g., you return masked array for all the properties, but what about |
My thinking is that this is general. Time properties (in particular all format properties) will be a masked array. Any Quantity output will just be a Quantity with In case you haven't guessed, I'm pushing for |
|
I think one principle that will keep the Time masking implementation manageable and simple is to not apply the mask to all non-format attributes, e.g. location. As it currently stands |
|
About splitting this into two PRs, in principle I agree that is the right thing. In practice it is going to make things go faster for me if I don't. I have a limited amount of time before the day-job pulls me back and substantially slows development. In fact I changed the title and you'll see that I'm about to include what could reasonably be a 3rd PR. Note that the 3rd would require 1 (setting) and 2 (masking), and 2 would require 1, so you can see how developing them independently just slows the process. |
|
@taldcroft - I'm much more uncomfortable with the mask than with Perhaps more importantly, just having |
|
p.s. I do worry quite a bit about unexpected consequences of making |
From my perspective this is completely internal and the fact that Now it is true that in this implementation, a
I'm tired of mixins being crippled. By adopting the NaN protocol they can be fully functional! I'm mostly thinking of join(), which is actually very useful and (except for inner) needs masking. |
True, but setting the representation values to |
|
About changing Time to be mutable, I have sent email to astropy-dev to request input. I agree on the idea of some attribute ( In general I think developers are very much used to the pitfalls of shared memory in numpy array objects, so I think we should enable writing by default. Since no existing code writes to Time objects, on the transition to 2.0 nothing would immediately break. For the small minority of cases where mutability is a problem, developers would have the opportunity to fix their code. This could be as simple (and back-compatible) as |
|
I like the idea of mirroring the numpy WRITEABLE flag since that allows new functionality to be implemented gradually but probably also requires that the default is An alternative paradigm would be to base a new |
|
@eteq - this is the PR for making |
|
I've been working on this but I see that making it for 2.0 is perhaps not likely at this point. |
There was a problem hiding this comment.
I left a few comments/questions below. In general, I agree we should merge this in soon and if others want to propose a better solution, then there is still time to change things.
But first, A couple of big picture questions/concerns:
-
Why can e.g.
t.mask[1] = Truenot be supported? For a Time object in a Table, it will be confusing for users if some columns support this and not others. -
If I mask a value, then unmask it, won't precision be lost due to
jd2being set to NaN temporarily? EDIT: I guess the point of the API here is that one can't 'unmask'?
I do worry a bit about having Time diverge too much from SkyCoord, but overall I think this PR does make table operations possible that weren't before, so to me it seems like a net improvement.
| if axis is not None: | ||
| approx = np.expand_dims(approx, axis) | ||
| else: | ||
| approx = np.max(jd, axis, keepdims=True) |
There was a problem hiding this comment.
Note that for 3.1 we are dropping Numpy < 1.13 so these kinds of blocks can be simplified. However #7058 will need a little work before being merged, so we can always just merge this as-is then remove later.
| (val2 is None or | ||
| val2.dtype == np.double and np.all(np.isfinite(val2)))): | ||
| # val1 cannot contain nan, but val2 can contain nan | ||
| ok1 = val1.dtype == np.double and np.all(np.isfinite(val1)) |
There was a problem hiding this comment.
Why isfinite and not isnan? This will catch inf/-inf
There was a problem hiding this comment.
This line for ok1 is the same as it has always been and says that the user input must be double and finite and not NaN. (isfinite(nan) is False).
The next line for ok2 is mostly the same but requires that all values be a finite number or NaN. (isinf(nan) is False).
Summary: same as before except that NaN is allowed for val2.
astropy/time/tests/test_basic.py
Outdated
| # Fails because the right hand side has location=None | ||
| with pytest.raises(ValueError) as err: | ||
| t[0, 0] = Time(-1, format='cxcsec') | ||
| assert 'cannot set to Time with different location' in str(err) |
There was a problem hiding this comment.
The error message doesn't seem quite right here - isn't the issue more that on the right the location isn't set so it's ambiguous?
There was a problem hiding this comment.
It's different in the sense that the left side has location = EarthLocation(...) while the right side has location = None. I think the exception will let the user diagnose the problem by hinting to print the location of left and right sides. I could make the exception message be .. different location attribute to be even more clear? Or something else?
There was a problem hiding this comment.
Yes, saying different location attribute - maybe could you explicitly say what the location is in each case? (expected ..., got ...)
|
|
||
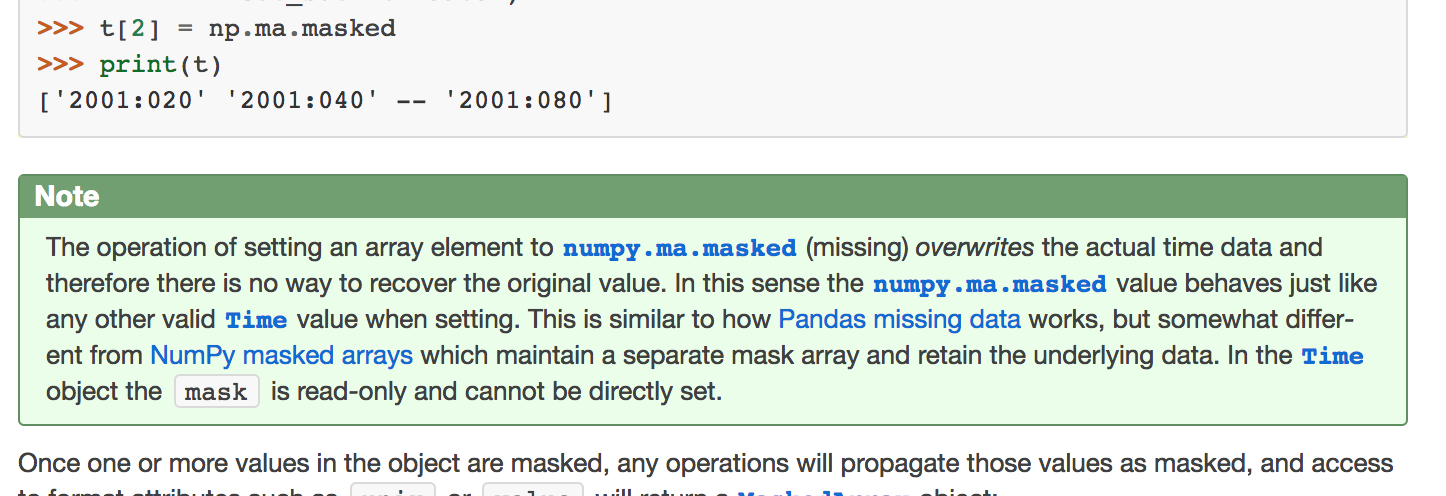
| >>> t.mask | ||
| array([False, False, True, False]...) | ||
| >>> t[:2] = np.ma.masked |
There was a problem hiding this comment.
I think you should explain that it's not possible (and why) to set the mask using e.g. t.mask[:2] = True
There was a problem hiding this comment.
I've re-reviewed this after having taken some time to think. Apart from some of the minor inline comments above which still hold, I think we should actually go ahead and merge this. My main argument for this is that this doesn't introduce any API that I think we would want to revert in future. For example, I think that regardless of the internal implementation, doing things like:
>>> t[1] = Time.now()
or
>>> t[1] = np.ma.masked
are great. If anything, we'd probably want to allow similar behavior in SkyCoord (that is, setting a single SkyCoord element to another SkyCoord).
I would like to consider in future that we allow e.g.:
t.mask[1] = True
i.e. a mutable mask, and this would require a separate mask array (so that unmasking works) but my point is that the API additions here are already a step forward and I don't see the point in delaying this. I don't think there are API additions here that we'll want to revert (and as far as I can tell there is no API being broken).
|
The syntax of |
Right, I think that given the NaN-based implementation we shouldn't allow this since unmasking doesn't work. I was not aware that Numpy were moving away from that. In any case, my point is that |
|
Realizing I've had several out-of-band conversations on this without commenting in this PR... I haven't been able to review in detail but I have some general thoughts. To summarize, now that @astrofrog clarified that the NaN part was implementation and not visible to the user, I'm fine with this. I'm not convinced we don't want mutable masks in a general sense (e.g. one could argue this might be good in
I didn't appreciate that either... I'm also not sure that I agree - I think one of the advantages of table is that it allows this. But I think it's a moot point for this PR (see above). |
I don't know that this is true. It can just be messy for arrays with a structured dtype (which part does one mask). |
|
@mhvk - agreed it is not critical to this discussion nor necessarily the viewpoint of astropy, but I stand by my statement. 😄 From https://docs.scipy.org/doc/numpy-1.13.0/reference/maskedarray.generic.html#modifying-the-mask:
|
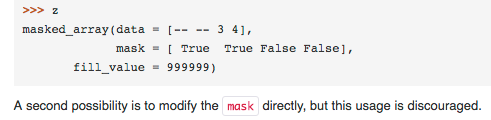
|
I agree with you (and the documentation) that it is better to just write |
|
@astrofrog - I think I addressed your comments.
Thanks to all for your reviews! |
|
@taldcroft - looks good! This is good to go :) |
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
Moving the cache to Time itself seems more logical, since apart from the mask, all the handling of cache state is done in Time. Indeed, it was on Time before setting of Time elements was introduced in astropygh-6028. This just moves it back now that the mask handling is much simpler. One resulting change is that any cached format information still needs be deleted when changing format, since it can be out of date.
This is an implementation of the necessary bits to fully support table join, hstack, and vstack for the Time class.
It includes new functionality for Time masking and setting, along with an implementation of the info class
new_like()method.Masking: there was discussion about whether to do this with
np.naninternally or usingMaskedArray. I first did the latter and got something mostly working (passing most but not all tests), but it ended up getting messy. In particular the interactions withQuantitygot ugly because Quantity knows how to play withndarraybut notMaskedArrayin arithmetic etc.But it looks like the
np.nansolution is fine, with the unexpected twist that using this strictly injd2makes life a lot easier because it is easy to locally set thenanvalues to0before entering any ERFA functions. This avoids thedubiousvalues problem.Setting: I think it is time to make
Timemutable! Admittedly I haven't thought super hard about pitfalls yet, but I think just being careful about clearing the cache is enough. This is going to be needed to makeTimework in table operations (and probably Time series) where you need masking and item setting.To do: