Add example app: pivot chart maker #5894
Conversation
|
Hi @mmowers thanks for the PR! Regarding the CI test failures there are just a few edits needed to satisfy the linter: |
examples/app/pivot/theme.yaml
Outdated
| @@ -0,0 +1 @@ | |||
|
|
|||
There was a problem hiding this comment.
If there aren't any customizations made in this file, it can just be omitted entirely.
| # Ignore everything in this directory | ||
| * | ||
| # Except this file | ||
| !.gitignore |
There was a problem hiding this comment.
I have this gitignore file because users are able to download csv files to this folder.
examples/app/pivot/main.py
Outdated
| wdg['y_major_label_size'].on_change('value', update_sel) | ||
| wdg['circle_size'].on_change('value', update_sel) | ||
| wdg['bar_width'].on_change('value', update_sel) | ||
| wdg['line_width'].on_change('value', update_sel) |
There was a problem hiding this comment.
since these are all getting the same callback, it might be a little more economical in terms of code to use a loop, somethign like:
for name in widget_names:
wdg[name].on_change('value', update_sel)
| Modeled,ID,gas,2024,2753007.082 | ||
| Modeled,ID,gas,2026,2782479.991 | ||
| Modeled,ID,gas,2028,2917963.431 | ||
| Modeled,ID,gas,2030, |
There was a problem hiding this comment.
This may be a bit large to check into the repo directly. We should consider putting it in bokeh.sampledata and using it from there (and using the mtcars data from there as well)
There was a problem hiding this comment.
I've reduced the size of this csv to 6 KB, and removed cars.csv. Let me know if that is sufficient.
| PLOT_HEIGHT = 300 | ||
| PLOT_FONT_SIZE = 10 | ||
| PLOT_AXIS_LABEL_SIZE = 8 | ||
| PLOT_LABEL_ORIENTATION = 45 |
There was a problem hiding this comment.
These could go in theme.yaml I think
There was a problem hiding this comment.
These variables are just used as defaults for the widgets. But the styling itself is coming from the widget values, not directly from these variables. Let me know if you have another idea of how to do this. In the meantime, I've removed theme.yaml.
|
I've left some initial review comments. I think there are some other things we can do like add a screenshot and link to the top level |
|
Thanks @bryevdv! I've added a commit to address your comments. |
|
@mmowers getting closer! First, there was an upstream dependency change that caused our unit tests to all start failing. You will need merge/rebase on master to get those green again. After your lastest commit, there are still some (new) linter issues to fix: I do think we need to figure out what to do about the large CSV. One option would be to have a download script or function that will fetch the CSV files the first time the app is run (or make a warning that instructs how to download them) Also I think my comment about the |
|
Thanks @bryevdv! I'll try to get these changes done tomorrow. One clarification before I do: I updated the csv file and now it is 6 KB. I'm not sure you saw that because the comment is collapsed as it is associated with an outdated file. I'm more than willing to add a function to automatically fetch the csv when the app is initially loaded, but wanted to make sure you were aware of its updated size before I make the change. Thanks again! |
|
Hi @bryevdv , I've pushed some updates. The csv file is now down to 2K, so hopefully that's small enough (let me know if it isn't). For the examples/app readme, the png needs to be uploaded to http://bokeh.pydata.org/static/. I have the PNG here: https://github.com/mmowers/superpivot/blob/master/pivot.PNG. Thanks again! |
|
@mmowers It think 2k is probably an OK size. I will upload the image to the pydata site this week. It looks like the test failure was spurious, so I've restarted it. Apart from that I just want to have a change to check out the branch and run the example directly, which I should be able to get to in the next few days. |
|
@bryevdv , |
|
Hi @mmowers I am overwhelmed with some other tasks right now. If you can resize the image to be the same width as the existing thumbnails in the apps README that would be a huge help actually. |
|
Hi @bryevdv , |
|
Hi @mmowers I have uploaded the thumbnail to this location: http://bokeh.pydata.org/static/pivot_t.png I added the I also checked out the branch and ran it locally. It's very cool! In general my main observation is that it does not actively prevent unusable combinations of parameters, and when a user makes a selection that is not reasonable, then the only indication is an exception printed in the console. Here are some observations/suggestions, in no particular order:
I'm definitely not saying all these things need to happen before this example is merged, but I wanted to at least get a record of them. However, we are shooting for the 20th for a release, so if you have any more time to work on this in the next ~2 weeks, I think getting a few of these changes in would add alot of polish. Understand completely if you do not have bandwidth over that time frame. Let me know what you think! |
|
Thanks much @bryevdv for the suggestions! I think I can knock a few of these out before the 20th.
Also wondering, do you or any other Bokeh maintainers have any performance improvement suggestions? I'm wondering if you can see offhand anywhere that the code is significantly under-performing its potential. Thanks again! |
|
|
Hi @bryevdv , I've made the changes we agreed on. Regarding colors, I'm actually using colors from a Spectral palette in bokeh. To make them more clear, I increased opacity from 0.6 to 0.8. Are distinctions clearer now? Let me know what you think! |
|
@mmowers I fetched the branch and took a quick look and the changes are pretty fantastic at a glance. I will take a closer look over the weekend. I don't expect to have many if any comments, thanks for the great example! |
|
@mmowers on master I get errors like this when I try to change to a new csv: is this working for you? Edit: seem to get them with Edit 2: Oh, it's because there are no default axes selected. |
|
Not for now, but a future improvement would be to handle datetime dimensions better, e.g. not turn every date into a categorical coordinate:
|

{kind=link}
{kind=link}
|
@bryevdv , thanks for the datetime note. I haven't yet viewed a csv with dates. On the error, I noticed it before too, but it didn't seem to prevent anything from working. However, with a large enough data set with many plots that I'm switching out, I'll experience some pretty significant slowdowns during which those errors will continually spawn for a few seconds. I've added to the instructions at the top of the page, including a note that users need to select x-axis and y-axis after they switch a data source. I also cleaned up a flake issue and it looks like all checks are good now. Thanks again! |
|
@mmowers OK looks good, I only have one more small ask. The para at the top is pretty monolithic. Do you mind deleting the "Instructions:" at the beginning (it seems evident to me at least that they are instructions without that reminder), and splitting the rest into 2 or 3 paragraphs? |
|
@bryevdv, |
|
Going ahead and merging now. FYI this will fail when it is merged due to an unrelated problem ( Thanks @mmowers ! |
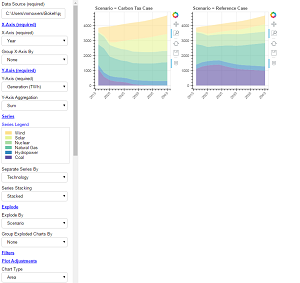
This bokeh app creates pivot charts from data, similar to Excel's pivot chart functionality, but with the additional ability to explode into multiple pivot charts.