


A tool to download tagged images from tumblr as well as add their urls and other associated data (tags etc.) to a database.
Get all the necessities:
pip install -r requirements.txt
or download individually:
Get tumblpy:
pip install python-tumblpy
Get PyQt5
pip install pyqt5
Download the repo.
Graphical (run.py)
Run:
python run.py
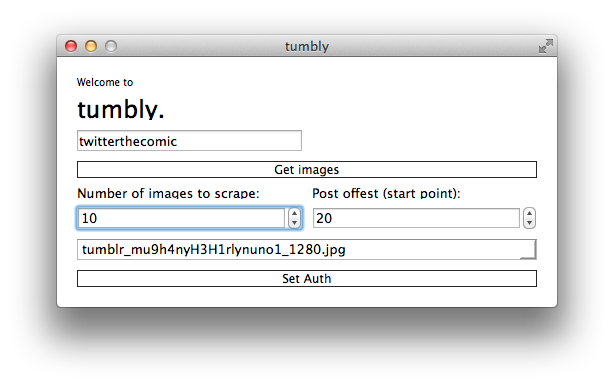
Click the 'Set Auth' button and add your consumer key and consumer secret.
(You do not need to do this if you have already set them by running tumblyCL.py).
Enter the tumblr username, number of images to download and the offset (defaults to 20).
Commandline/Terminal (tumblyCL.py)
Run the script with your arguments:
python tumblyCL.py -u -n -o
If this is the first time you have used the script, you will be prompted to add your consumer key and consumer secret, it will not work otherwise.
(You do not need to do this if you have already set them by running run.py).
usage: tumblyCL.py [-h] -u USERNAME -n NUMBER [-o START]
arguments:
-h, --help show this help message and exit
-u USERNAME, --username USERNAME
The username of the tumblr user whose tumblr you wish to scrape.
-n NUMBER, --number NUMBER
The number of images to scrape.
-o START, --start START
Post number to start from (offset).
- Required -u:
The tumblr username e.g. 'twitterthecomic' from 'twitterthecomic.tumblr.com'. - Required -n:
The number of images to download. - Optional -o:
Offset (what number post to scrape from), the default is 0.
Example:
python tumblyCL.py -u twitterthecomic -n 10
A databse will be created in the working directory alongside a folder to contain the downloaded images.
Each downloaded image's filename will be the tumblr username and an incremented number.
Currently does not support posts with multiple images and will ignore posts without tags.
- Fork it!
- Checkout the to do list below or any open issues.
- Create your feature branch:
git checkout -b my-new-feature - Commit your changes:
git commit -am 'Add some feature' - Push to the branch:
git push origin my-new-feature - Submit a pull request!