Reference documentation
Terminology: let's use TS for time series, DS for data series. Let's use "entity" to mean either edge or a node.
- The basic unit of data in this plugin is a data series (DS). A DS consists of:
- an index variable X (e.g. time point, experiment condition) with N states X1, ..., XN
- one or more rows (dependent variables) Y1, .., YM** (e.g. expression). Each row has a unique ID and a name (which may not be unique).
- a mapping from entities (edges/nodes) to DS rows by a foreign key.
- Specific DS types differ in what types of data they store and what are their index variables. For example time series (TS) has time as index variable and floating point values for data.
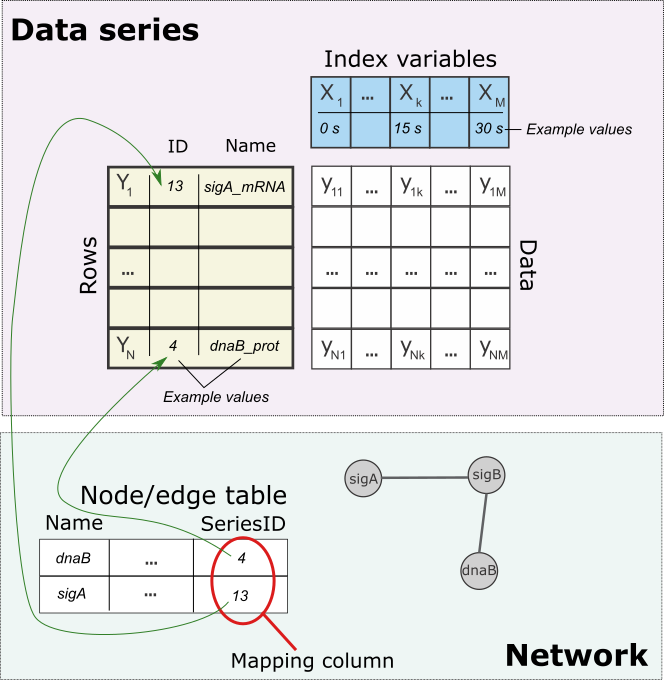
- Mapping
- The rows of DSs can be associated with both nodes and edges, (e.g. a TS for gene expression levels associated to nodes and a TS for a predicted regulatory effect of one gene on the other associated with edges).
- The mapping is based on a unique id of the rows which is stored in one of the columns of entity table.
- All mappings are relative to a network and entity type, i.e. mapping is always of the form "series S is associated with nodes/edges in network N via column C".
- It is allowed to have multiple entities mapped to same DS row. (e.g. in a metabolic network the cofactors are often represented by multiple nodes in the network, like ATP. All these cofactor nodes should be linked to the same dependent variable)
- Some DS rows and/or entities may remain unmapped.
- A DS can have multiple mappings in the same network to both nodes and/or edges.
Series can be imported through File -> Import -> Data Series. Currently tabular files (e.g., CSV/TSV) and SOFT files are supported. See the SOFT example and Tabular example for more details.
Series can be exported into a tab-separated file via File -> Export -> Data Series
The mappings of Data series to columns in node/edge tables can be modified via Apps -> Data Series -> Manage column mappings. There, you choose the parameters of the mapping, possibly creating a new column in the node/edge table. You can also automatically map the DS rows by matching row names with a given column in the node/edge table (exact match required). You can inspect the log to see, how many rows in the node/edge table have been succesfully mapped.

The full contents of the DS is visible in the Data Series tab in the table panel, while the visualisation of the DS rows mapped to selected nodes/edges is shown in the Data Series Visual tab. Checking Show series from neighbourhood displays the DS rows mapped to adjacent nodes/edges as well (i.e. for a selected edge, DSs mapped to both source and target node are shown).
Via Apps -> Data Series -> Remove Data Series.
Is the preferred way to perform smoothing to get instant feedback. See Smoothing example for more information.
Lets you manually specify all parameters for smoothing a time series. Currently (v0.9), only linear kernel smoothing is available.