{kind=link}
Collaboration on descriptions used in personal knowledge graph (PKG) practices.
The following layers are found among processes for developing knowledge graphs. Ostensibly these descriptions can apply across the range of available tools.
Discussion about these layers and iteration on their descriptions is needed.
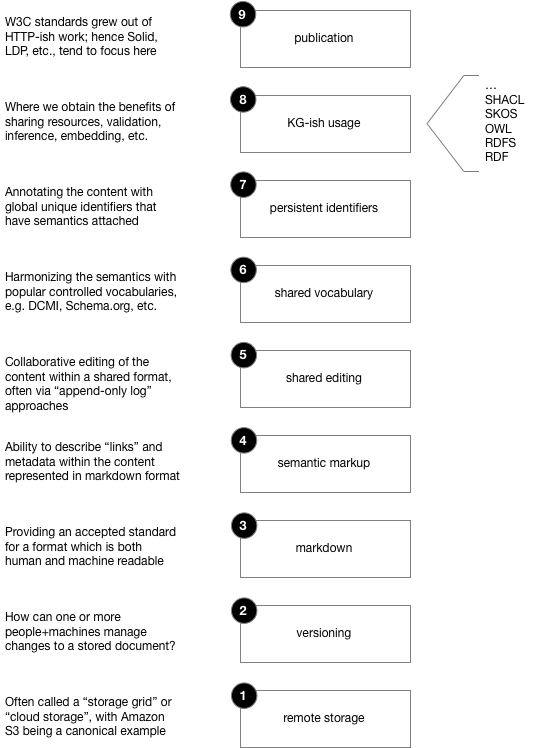
For example, the popular storage grids such as Amazon S3, Azure Storage, Google GCS, etc., are at Layer 1. These are amazingly robust and cost-effective, although relatively "raw" in the sense that they are neither file systems nor databases. Also, they are mostly designed for programmers (or applications) to use.
Use of remote storage distinguishes a PKG use case from the trivial case of one person merely using local storage on their local computer. It use implies capabilities for collaboration, publishing, disaster recovery, etc.
Services such as GitHub, GitLab, etc., are at Layer 2. These typically bundle the versioning semantics of a tool such as git along with a storage grid, then provide ways to publish (e.g., jumping all the way up to Layer 9). Graph-based data and metadata can be difficult to version – or rather, there are specialized methods and git doesn't necessarily understand.
This work is by definition transactional in nature.
The markdown at Layer 3 is one among many popular formats. It has the benefits of being relatively human-readable, even in its raw form. It's also native in Jupyter notebooks, as well as one of the most popular formats for documenting open source projects, and increasingly used among technical publishers as well.
The semantic markup at Layer 4 begins to add some semantic properties to content formatted in markdown. For example, means for adding links and other metadata. Services such as Obsidian and Roam are largely at this layer.
Layer 5 shared editing is what people commonly associate with Google Docs or Box. There's a programming technique called append-only logs which makes collaborative editing feasible to manage online. These services typically bundle Layer 1 storage, along with some aspects of Layer 2 versioning. Generally these services lack much awareness about markdown formats specifically, and tend to be MS Word lookalikes.
This work is by definition transactional in nature.
The shared vocabulary in Layer 6 is where a project attempts to harmonize their semantic markup with commonly used controlled vocabularies, such that the metadata references shared definitions. Examples include DCMI and Schema.org among many others.
In aggregate, this is where ontology gets described.
Layer 7 uses persistent identifiers to "populate" the semantic markup such that content can be referenced globally using unique identifiers. Each class of persistent identifier will have some "authority" backing it. For example, there are ISBN for books, ISSN for periodicals, ORCID for resesearchers, ROR for organizations, DOI for articles, etc. Using a URL is perhaps the simplest case.
Alternatively, a given organization be its own "authority", i.e., it may construct and publish it's own identifiers specific to its context.
This can be performed using URN that are composed of some local identifiers.
For example, each article posted on LinkedIn has a URN specific to LinkedIn, which gets exposed in public as part of that article's URL (web link).
For example, in the link: https://www.linkedin.com/feed/update/urn:li:activity:6774890201442582528/ the URN portion is urnli:activity:6774890201442582528 where the latter hex number is a kind of uuid defined within the context of LinkedIn.
The other elements composing the URN's structure help clarify the semantics about its domain and interpretation.
While semantic conventions such as dct:identifier may be used as "catch-alls" for representing persistent identifiers, unless a KG represents each class of identifier uniquely then it probably won't be able to do support effective queries, inference, validation, embedding, search, etc.,
In other words, "good enough" representation does not guarantee effective inference down the road in the KG use cases.
Within Layer 8 is where the knowledge graph work happens. Of course, this has its own internal layering: RDF for triples/quads, then RDFS schema for defining properties, then OWL for machine interpretability, and so on.
Both the Layer 6 ontology and the Layer 7 identifiers must exist as "overlays" atop the content – in other words, as semantic annotation – for the Layer 8 knowledge graph usage to make any sense. Sometimes this is described using the relatively dated terms TBox and ABox respectively, although these may introduce some distorted interpretation.
Finally, there's a presentation layer at the top – roughly similar to network layer models – where publishing the KGs occurs. Since the W3C standards emerged from world wide web, many of their notions (Solid, LDP, etc.) tend to fixate at this layer, without being especially mindful about practical details for some of the underlying foundations.
This layer is where many KG use cases provide features for public access. Publishing may be a matter of:
- web-based rendering
- search and query capabilities
- API access
Recognizing how the marketing departments of technology vendors tend to promise "all things to all people" in reality few if any commercial offerings provide support across the entire stack of these layers.
Effective practices in industry tend to:
- leverage a middle-out strategy in lieu of top-down EKG practices, where PKG practices may evolve into major components of middle-out projects
- integrate multiple libraries, tools, and services to provide coverage across the stack, depending on the needs of their use cases
Notably, the graph database vendors tend to focus on Layer 1 and the query aspects (mixed into either in Layer 8 or Layer 9) of search, while not providing especially effective solutions for the other layers.
Check the Requirements section
Check the Tools section
Check the Use Cases section