This repository contains the code and data for our TACL paper: MENLI: Robust Evaluation Metrics from Natural Language Inference.
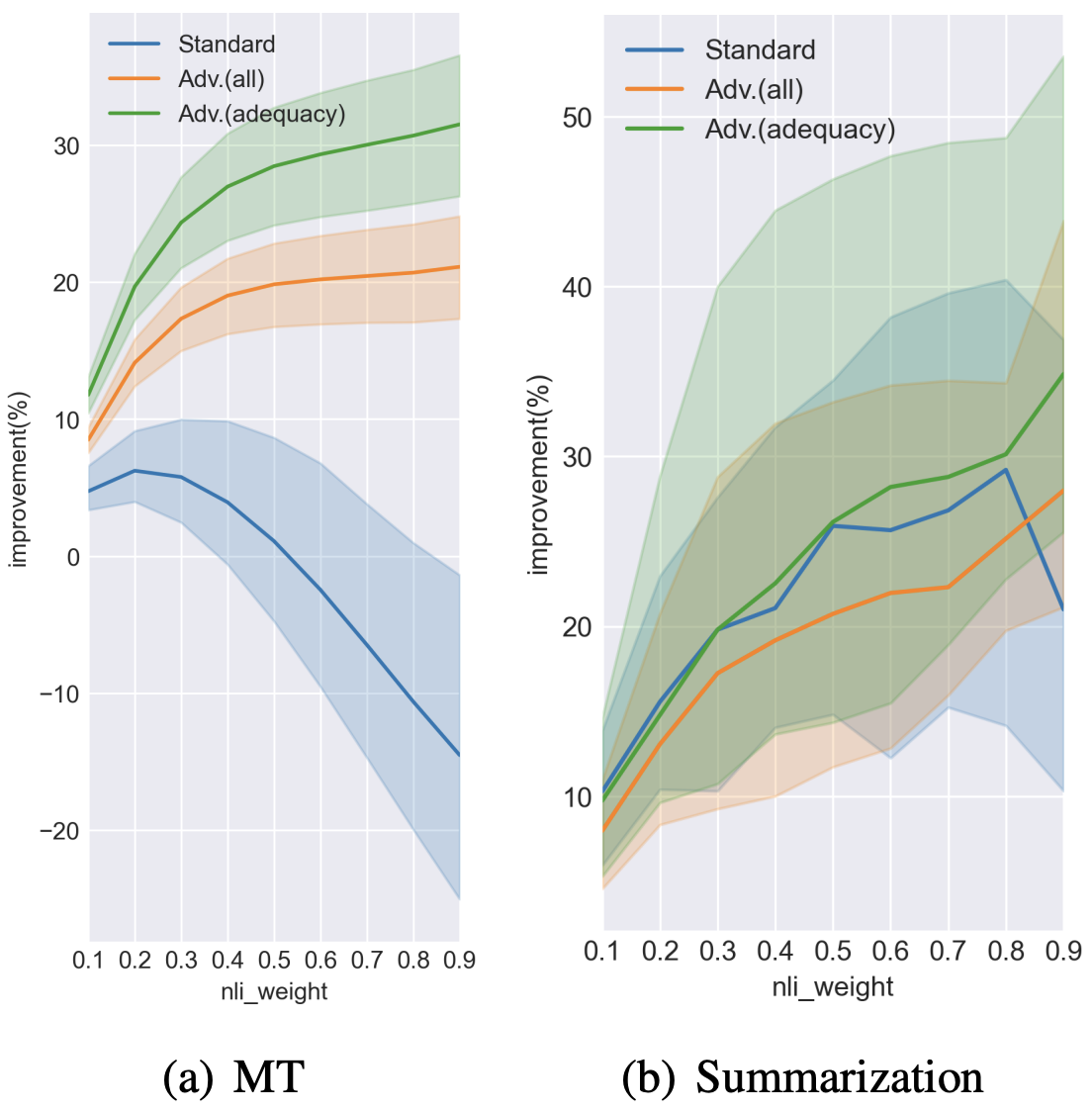
Abstract: Recently proposed BERT-based evaluation metrics for text generation perform well on standard benchmarks but are vulnerable to adversarial attacks, e.g., relating to information correctness. We argue that this stems (in part) from the fact that they are models of semantic similarity. In contrast, we develop evaluation metrics based on Natural Language Inference (NLI), which we deem a more appropriate modeling. We design a preference-based adversarial attack framework and show that our NLI based metrics are much more robust to the attacks than the recent BERT-based metrics. On standard benchmarks, our NLI based metrics outperform existing summarization metrics, but perform below SOTA MT metrics. However, when combining existing metrics with our NLI metrics, we obtain both higher adversarial robustness (15%-30%) and higher quality metrics as measured on standard benchmarks (+5% to 30%).
2023-11-09 Update: You can try MENLI with BERTScore-F and MoverScore from pypi now!!
pip install menli
You can combine arbitrary metrics with NLI systems. Note that you should score the systems to be compared together, as the ensemble involves the min max normalization. E.g., for evaluation on WMT datasets, the systems for one language pair should be scored together (see line 110 in wmt.py).
from menli.MENLI import MENLI
nli_scorer = MENLI(direction="rh", formula="e", nli_weight=0.3, combine_with="None", model="D")
nli_scorer.score_nli(self, srcs=srcs, refs=refs, hyps=hyps)
self.metric_scores = **your metric scores**
ens_scores = nli_scorer.combine_all()
We provide the demo implementation of the ensemble metrics; however, the implementation is still imperfect.
#from MENLI import MENLI
from menli.MENLI import MENLI
scorer = MENLI(direction="rh", formula="e", nli_weight=0.2, \
combine_with="MoverScore", model="D", cross_lingual=False)
# refs and hyps in form of list of String
scorer.score_all(refs=refs, hyps=hyps)
E.g., run XNLI-D on WMT15:
python wmt.py --year 2015 --cross_lingual --direction avg --formula e --model D
Run the combined metric with BERTScore F1 on wmt17:
python wmt.py --year 2017 --combine_with BERTScore-F --nli_weight 0.2 --model R
We implemented the combination with MoverScore, BERTScore-F1, and XMoverScore here, to combine with other metrics, just fit the code into metric_utils.py.
Specifically, in init_scorer() function, you need to initialize a scorer like
def init_scorer(**metric_config):
from bert_score.scorer import BERTScorer
scorer = BERTScorer(lang='en', idf=True)
metric_hash = scorer.hash
return scorer, metric_hash
Then call the metric scoring function in scoring():
def scoring(scorer, refs, hyps, sources):
if scorer.idf:
scorer.compute_idf(refs)
scores = scorer.score(hyps, refs)[2].detach().numpy().tolist() # F1
# Note: the outputs of the metric should be a list.
return scores
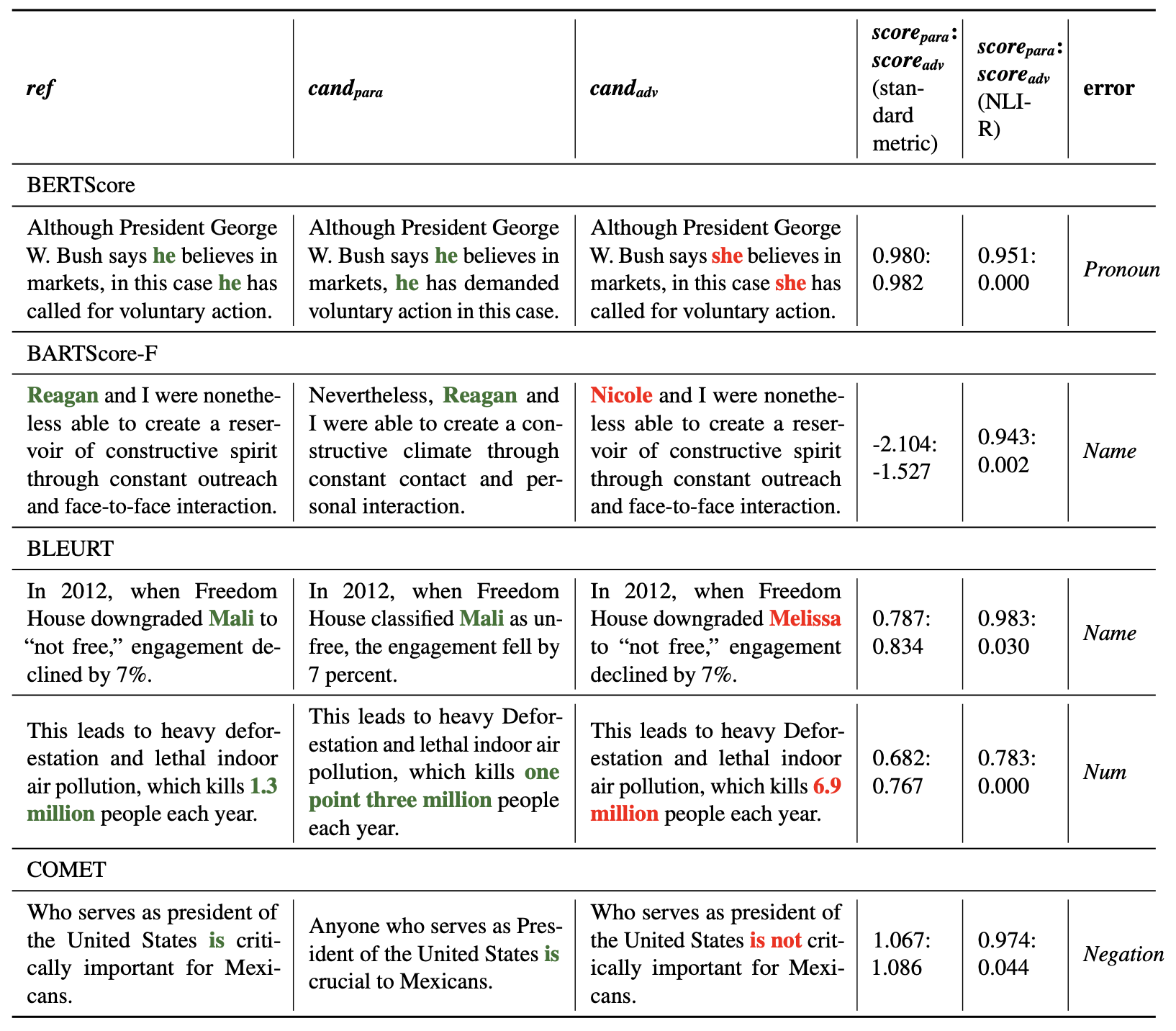
We release our adversarial datasets. Please check here and the evaluation script for more details about how to run metrics on them.
2023-4-11 Update: we uploaded a new version of adversarial datasets for ref-based MT evaluation, which fixes some space and case errors (more details).
To reproduce the experiments conducted in this work, please check the folder experiments.
If you use the code or data from this work, please include the following citation:
@article{chen_menli:2023,
author = {Chen, Yanran and Eger, Steffen},
title = "{MENLI: Robust Evaluation Metrics from Natural Language Inference}",
journal = {Transactions of the Association for Computational Linguistics},
volume = {11},
pages = {804-825},
year = {2023},
month = {07},
issn = {2307-387X},
doi = {10.1162/tacl_a_00576},
}
If you have any questions, feel free to contact us!
Yanran Chen (yanran.chen@stud.tu-darmstadt.de) and Steffen Eger (steffen.eger@uni-bielefeld.de)
Check our group page (NLLG) for other ongoing projects!