DL‘s Lexer
DLex可以使用正规文法和正则表达式两种格式进行分析。由NFA到DFA的过程,默认对DFA进行最小化。
python .\cli.py -g .\test\rule.txt -d
python .\cli.py -g .\test\rule.txt -p -codefile .\test\codeGr.\test\codeGr中的内容:
import A
int main(){
string s = "helloWorld";
return 0;
}
row:1,col:0,value:import
row:1,col:6,value:A
row:2,col:0,value:int
row:2,col:3,value:main
row:2,col:8,value:(
row:2,col:9,value:)
row:2,col:10,value:{
row:3,col:4,value:string
row:3,col:10,value:s
row:3,col:12,value:=
row:3,col:14,value:"helloWorld"
row:3,col:27,value:;
row:4,col:4,value:return
row:4,col:10,value:0
row:4,col:12,value:;
row:5,col:0,value:}
python .\cli.py -g .\test\rule.txt -pk获得一个名为DFAresult的pickle文件。
为了便于得到token的类型,对于正则表达式采用每一种模式分别生成一个DFA的办法,所以需要有选择的进行画图。
比如,查看一个类型为COMPLEX的DFA,则:
python .\cli.py -r .\config.json -d -type 'COMPLEX'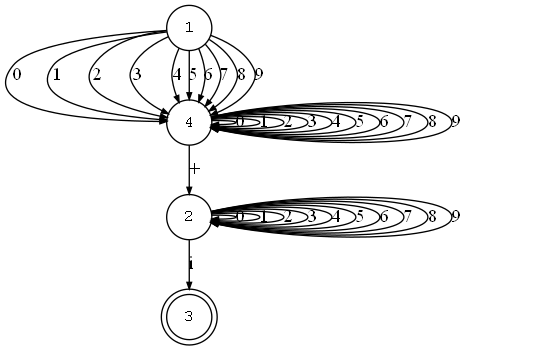
python .\cli.py -r .\config.json -p -codefile .\test\codeRe.\test\codeRe中的内容:
import A
int main(){
string s = "I want to say :\"helloWorld\"";
cp = 4+8i
se = 5E+9
int a=10
return 0;
}
"""sdfas
LexerError: Lexer error on 's' line: 9 column: 8
Token(IMPORT, 'import', position=1:6)
Token(ID, 'A', position=1:8)
Token(INT, 'int', position=2:3)
Token(MAIN, 'main', position=2:8)
Token(LP, '(', position=2:9)
Token(RP, ')', position=2:10)
Token(CLP, '{', position=2:11)
Token(STRING, 'string', position=3:10)
Token(ID, 's', position=3:12)
Token(ASSIGN, '=', position=3:14)
Token(STRINGVALUE, '"I want to say :\\"helloWorld\\""', position=3:46)
Token(SEMI, ';', position=3:47)
Token(ID, 'cp', position=4:6)
Token(ASSIGN, '=', position=4:8)
Token(COMPLEX, '4+8i', position=4:13)
Token(ID, 'se', position=5:6)
Token(ASSIGN, '=', position=5:8)
Token(SCIENCE, '5E+9', position=5:13)
Token(INT, 'int', position=6:7)
Token(ID, 'a', position=6:9)
Token(ASSIGN, '=', position=6:10)
Token(INTEGER, '10', position=6:12)
Token(RETURN, 'return', position=7:10)
Token(INTEGER, '0', position=7:12)
Token(SEMI, ';', position=7:13)
Token(CRP, '}', position=8:1)
Token(STRINGVALUE, '""', position=9:2)
python .\cli.py -r .\config.json -pk获得一个名为DFAresult的pickle文件。