more routine garbage collection in distributed? #1516
Comments
|
Are you running on master or latest release? There has been quite a bit of
activity on this recently.
…On Tue, Oct 31, 2017 at 6:33 PM, Julien Lhermitte ***@***.***> wrote:
I've noticed the memory seems to increase so I was worried of memory
leaks. I haven't noticed any (as I'm sure you were very confident I'd say
;-) ).
However, what I have noticed is that sometimes when a python process is
killed the memory usage on the cluster doesn't go to zero right away. This
can be problematic if the memory usage is quite large.
For example, let's say we have the following code, called
test_distributed.py
from distributed import Client
client = Client("IP:PORT") # put IP and PORT of sched hereimport numpy as np
def foo(a):
return a+1
arr = np.ones((100000000))
arr2 = np.zeros((100000000))
ff = client.submit(foo, arr)
ff2 = client.submit(foo, arr2)
If I manually run in 5 times (python test_distributed.py), I see the
following result for the memory usage:
[image: Memory profiles]
<https://camo.githubusercontent.com/101f556116e3b00ca9f40550eaf8d512babc1b08/68747470733a2f2f696d6775722e636f6d2f612f5a776b5a6c>
The memory usage goes up, then comes down when the process terminates, but
does not go to zero. When I run the same process, it goes up again, but
never exceeds the previous memory usage. So this suggests there is no
memory leak.
I figured this could perhaps have something to do with the python garbage
collection process, so I went one step further and ran the following script:
from distributed import Client
client = Client("IP:PORT") # put IP and PORT of sched here
def cleanup():
import gc
gc.collect()
client.submit(cleanup)
This brought down the memory back to zero.
[image: Memory profiles]
<https://camo.githubusercontent.com/134dc070abcca613c6e047fa42865f06b8bf2d75/68747470733a2f2f696d6775722e636f6d2f612f5a64525275>
My feeling is that the python garbage collector can sometimes be slightly
more aggressive with memory.
For long running applications like distributed, I think it could be a
good idea to force the garbage collection process every once in a while.
What do you think? Am I correct in my guess, and would there be a way to
resolve this on the distributed side? The other obvious solution is for
the user to run a cron script sending gc messages to the cluster. However,
this is not so clean (and for large intermittent loads may run at very
irregular times).
I sort of looked around to see if this was mentioned before, and didn't
see anything. I apologize if this is a repost. Thanks!
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#1516>, or mute the thread
<https://github.com/notifications/unsubscribe-auth/AASszDQt6k65E5XimUR0CJrGLmXsrqNkks5sx6BBgaJpZM4QNg-j>
.
|
|
The version is '1.19.3+17.g74cebfb' |
|
I pulled from master (made sure to delete the I see the same result. In passing, is there a way to see the version of distributed used on the bokeh server? That could be a nice feature. |
|
I recommend checking recent pull requests for the term GC. You'll find a few in the last few weeks. This may interest @ogrisel and @bluenote10 . Any desire to add an infrequent periodic |
If you're interested this could be added easily to the new HTML routes available in the |
I've noticed the memory seems to increase so I was worried of memory leaks. I haven't noticed any (as I'm sure you were very confident I'd say ;-) ).
However, what I have noticed is that sometimes when a python process is killed the memory usage on the cluster doesn't go to zero right away. This can be problematic if the memory usage is quite large.
For example, let's say we have the following code, called
test_distributed.pyIf I manually run in 5 times (
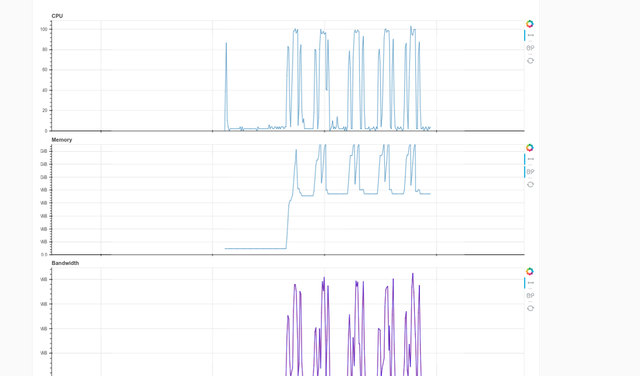
python test_distributed.py), I see the following result for the memory usage:The memory usage goes up, then comes down when the process terminates, but does not go to zero. When I run the same process, it goes up again, but never exceeds the previous memory usage. So this suggests there is no memory leak.
I figured this could perhaps have something to do with the python garbage collection process, so I went one step further and ran the following script:
This brought down the memory back to zero.
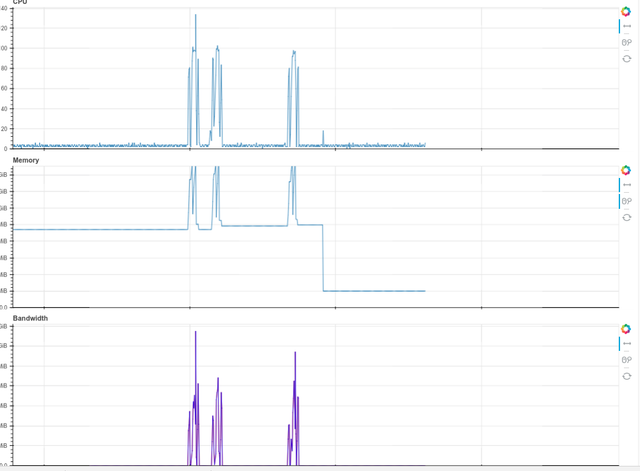
My feeling is that the python garbage collector can sometimes be slightly more aggressive with memory.
For long running applications like
distributed, I think it could be a good idea to force the garbage collection process every once in a while.What do you think? Am I correct in my guess, and would there be a way to resolve this on the
distributedside? The other obvious solution is for the user to run a cron script sending gc messages to the cluster. However, this is not so clean (and for large intermittent loads may run at very irregular times).I sort of looked around to see if this was mentioned before, and didn't see anything. I apologize if this is a repost. Thanks!
The text was updated successfully, but these errors were encountered: