The purpose of this solution accelerator is to demonstrate how scores estimating the probability a given household will purchase from a product category (or similar grouping of products) within a future period may be derived. These propensity scores are commonly used in marketing workflows to determine which offers, advertisements, etc. to put in front of a given customer and to identify subsets of customers to target for various promotional engagements.
A typical pattern in calculating propensity scores is to derive a set of features from a combination of demographic and behavioral information and then train a model to predict future purchases (or other desired responses) from these. Scores may be calculated in real-time but quite often these are calculated in advance of the future period, persisted and retrieved for use throughout that period.
We may think of each of these three major activities, i.e. feature engineering, model training, and customer scoring, can be thought of as three distinct but related workflows to be implemented to build a sustainable propensity scoring engine. In this solution accelerator, each is tackled in a separate notebook to help clarify the boundaries between each:
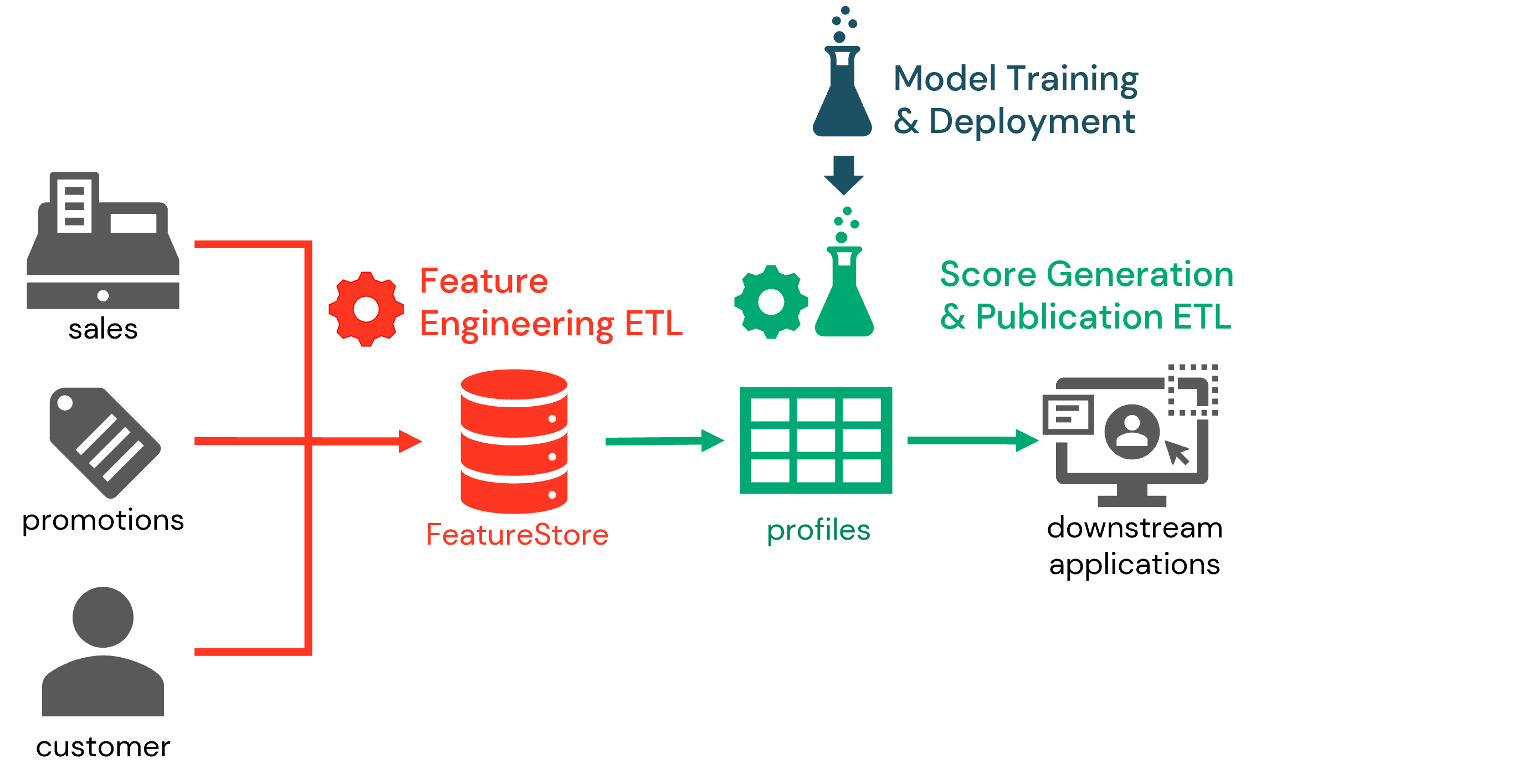
Across these notebooks, we will strive to produce propensity scores that provide us the likliehood a customer (household) will purchase products within a category in the next 30 days based on features generated from customer interactions taking place in various periods from over the last couple years. In real-world implementations, the forward looking period may be shorter or longer depending on the specific needs driving the scoring and feature generation may be more or less exhaustive than what is shown here. Still, organizations seeking to build a robust propensity scoring pipeline should find value in the concepts explored in each stage of the demonstrated process.
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
To run this accelerator, clone this repo into a Databricks workspace. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs.
The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.