This rep is to solve multi object detection with deep neural networks.
I will start by implementing the first version of the YOLO network. The idea is to subsequently increase the complexity of architecture by implementing sub systems such as spatial transformer network, attention transformers, feature pyramid network, so on and so forth to see how each hyperparameter affects the accuracies.
The dataset is a subset of the VOC dataset which contains 5000 images annotated with bounding boxes of objects present in the images.
Let's visualze 25 images from the dataset. For this, I created a class for visualizing the dataset. It is fairly flexibe and modular. It randomly samples 25 images from the dataset directory and plots it on a grid with matplotlib. So far, it does it's job reasonably.
Let's run it!

The images appear to be of different sizes. Therefore there will be some pre-processing needed before feeding each to the network. Or perhaps not, if the network is fully-convolution. I will update these lines once I read the paper today.
Now let's take a look at the annotations.
There is a linker in a csv file named train.csv / test.csv which links image names to its labels which are store in a txt file.
The lables are essentially a txt file with variable row size. The entries in each row is space delimited by spaces. The first entry is the class label. There are 4 more floating point values after this which correspoding to the bounding box coordinates.
I wrote a small script on Jupyter notebook to visualize annotation / labels on a random image on the dataset. This script randomly selects a sample from the dataset and draws bounding boxes on them with opencv. I might add this functionality to the datasetVisualizer class later and make it modular and flexible.
Let's run it to see!

Okay so have two locomotives in this sample image.
The label values are normalized to the image dimensions and are as follows;
centre x:float
centre y:float
height: float
width: float
Constructing the YOLO model is a fairly straightforward task. The model architecture from the paper can be seen below
Link to paper: https://arxiv.org/abs/1506.02640

The network can be found in the model module.
To keep this doc short, I won't print out the summary of the model.
The objective function for the Yolo V1 network is to minimize a multipart function. It is as follows
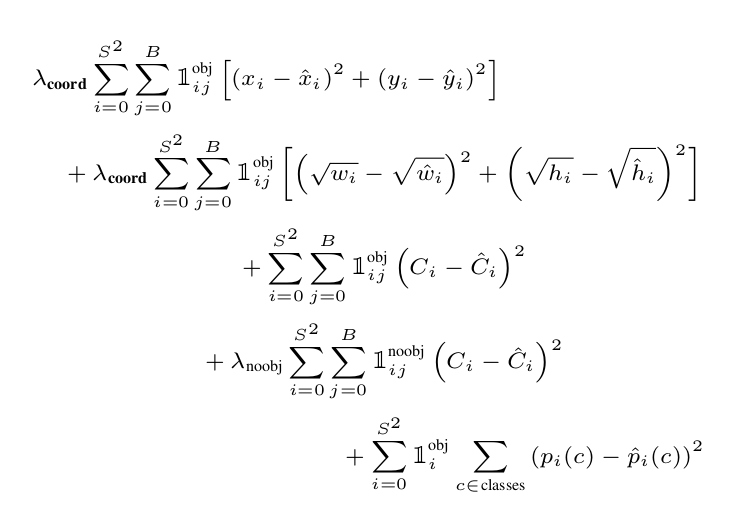
This is by far the trickiest part during setting up the model and its training.
The part that I struggled with most was not comprehending that the implementation of the loss function requires masking which can be very ingeniously implemented with torch classes and their member functions.