Use ArrayPool for OrderedEnumerable temp arrays #8069
Conversation
|
How important as that "temporary" aspect? An iterator could potentially live for a long time. |
ArrayPool is ok if you don't give it back for a long time; it will just allocate more arrays |
| array[i] = buffer._items[map[i]]; | ||
| } | ||
| } | ||
| finally |
There was a problem hiding this comment.
There should be no scope for an exception here bar something very catastrophic (thread abort). The try…finally is perhaps not needed.
48ff8ce
to
1d8acb5
Compare
|
LGTM. CC: @stephentoub, @VSadov |
|
@weshaggard, validity of the code change aside, is this a valid dependency to take? |
| yield return buffer._items[map[i]]; | ||
| } | ||
| } | ||
| finally |
There was a problem hiding this comment.
do we strictly need to guarantee the return of the rented array no matter what?
Can we just return without putting this into a finally?
Using finally seems a bit heavy, especially in an iterator.
Also, depending on the pool implementation, it seems it might expose the pool to a potential corruption if someone Disposes the iterator twice concurrently on separate threads.
There was a problem hiding this comment.
The corruption issue might be relevant even without finally. That is really an issue of being possible to resume an iterator on multiple threads.
It would be very bad thing to do, but would we make it worse by exposing shared pool to that as well.
There was a problem hiding this comment.
Yeah, without finally we can't be sure that two threads won't both hit the last MoveNext() at the same time. I wonder though if the fact that that's going to break anyway might be enough to prevent it; the author will have enough bugs with this approach to stick with it.
There was a problem hiding this comment.
Could go more heavy handed with
var rentedMap = Interlocked.Exchange(ref map, null);
if (rentedMap != null)
{
ArrayPool<int>.Shared.Return(rentedMap);
}There was a problem hiding this comment.
do we strictly need to guarantee the return of the rented array no matter what?
Not strictly; and this currently wouldn't guarantee that e.g. if someone used the iterator out of the common constructs and didn't dispose it.
Can we just return without putting this into a finally?
This would make not returning a what's likely a Gen2 buffer more of a common case. However, is code with a broken comparer/allocator such a major even otherwise that not returning a buffer pretty minor by comparison to the overall exception that will be happening?
There was a problem hiding this comment.
Of course, since the iterators are the only places that need the finally and the interlocked, they are obviously the only places that pay the cost of them. As such it may be that the change pays off in the other uses, but not there.
There was a problem hiding this comment.
Odd, you are right - I had suspected it would be used for
list.OrderBy((item) => item).FirstOrDefault()
There was a problem hiding this comment.
@benaadams It doesn't because it can get away with not doing so, and skip a lot of cost. See #2401
There was a problem hiding this comment.
I see. break in a foreach is indeed a problem that would require finally.
Interlocked.Exch seems to be a sufficient solution for the theoretical double-free.
Generally, it is not common for iterators to be moved between threads/cores, so we can expect no sharing. In such cases interlocked should be relatively cheap.
Nice solution.
The dependency is probably OK for the .NET Core implementation of this library but would likely force us to pull System.Buffers into the full .NET Framework at some point, or not port these changes. I've not looked closely at the places that already depend on System.Buffers to see if that is already the case or not but just something to consider. Before we do take this dependency do we have any numbers that help justify the change? |
|
@weshaggard I'll get some metrics |
If that's the only penalty for failing to return the buffer, I think we're better off not guarding with finally. For one thing, it shouldn't be that common a case. |
| @@ -31,6 +33,12 @@ public IEnumerator<TElement> GetEnumerator() | |||
| { | |||
| yield return buffer._items[map[i]]; | |||
| } | |||
|
|
|||
| var rentedMap = Interlocked.Exchange(ref map, null); | |||
There was a problem hiding this comment.
This isn't the cheapest operation. It wouldn't surprise me if this cost more than the use of buffers saved, especially with small inputs.
There was a problem hiding this comment.
And am I right in remembering someone saying its cost was greater still on ARM?
There was a problem hiding this comment.
ARM has a weaker memory model by default so yes. Don't know if there is a better multi-threaded guard though. Unless just guard against double dispose and not multi threading?
There was a problem hiding this comment.
No. I'm afraid this will either be worth the cost of the interlocked, or not. (Or worse, worth it above a certain size, and not below, leaving us wondering about what sizes are seen in actual use). The guard against double-dispose would have to be a guard that considered multiple threads as a possibility, so it can't be escaped.
616a467
to
6593fce
Compare
|
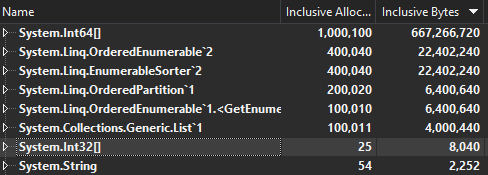
@weshaggard For a list of 100 random longs 100k iters of foreach (var item in enumerable.OrderBy((item) => item))
{
break;
}
var list = enumerable.OrderBy(item => item).Take(2).ToList();
var array = enumerable.OrderBy(item => item).Take(2).ToArray();
var value = enumerable.OrderBy(item => item).ElementAt(1);It saves 400k allocations and 169MB for the With Gen0 collections going from 285 to 231 execution time seems around the same; though will need to do longer runs to test. list of 1000 saves 1.6 GB of allocs |

|
It might be worth considering the iterators separately in metrics (for both time and allocations). Since they've accrued a different cost. |
|
Pre allocs Post allocs Obv |
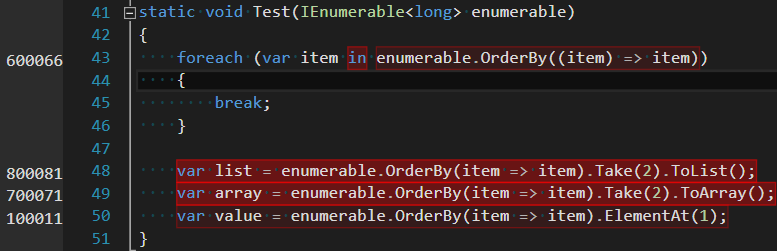
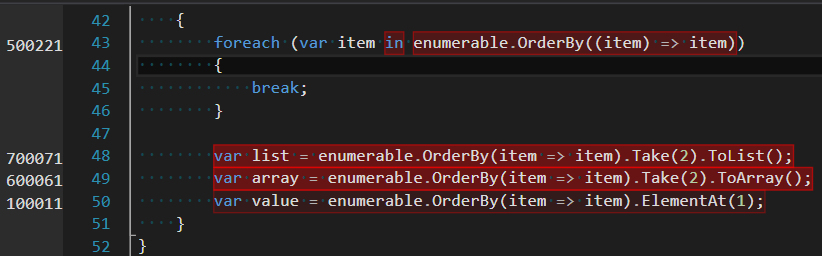
bf5ef7d
to
fe8e318
Compare
|
@jkotas, you've weighed in on ArrayPool usage elsewhere in corefx. Do you have an opinion here? |
|
Looks fine to me from the correctness point of view. I agree with @JonHanna that it would be better not protect the return of the buffer with finally. |
| return GetSmallEnumerator(buffer); | ||
| } | ||
|
|
||
| return GetEmptyEnumerator(); |
There was a problem hiding this comment.
If we're going to take this approach, then just letting GetSmallEnumerator do its thing with a count of 0 is probably fine.
|
Is the 32 threshold heuristic helping all the operations, or just the iterators? |
|
Its on all operations as its done at the Rent (probably should be a const) |
|
Yes, my question is whether it helps there. Where the other operations also suffering below 32? |
|
@JonHanna I think I'm going to have to use a profiler to dig in to what's happening in the 3 scenarios properly rather than just micro-benchmark them and let that evolve the approach. Iterators aren't the most straightforward code |
| private IEnumerator<TElement> GetEmptyEnumerator() | ||
| { | ||
| yield break; | ||
| } |
There was a problem hiding this comment.
If you want an empty enumerator when in Linq, you are better off using EmptyPartion<TElement>.Instance.GetEnumerator() which is already in use, and is a singleton.
|
Take a look at 950c153 which might be worth experimenting with. This uses
It also moves the logic for whether the array is rented or not up to the call, as I understand it was only the iterator use that was suffering below a certain size and should therefore have such logic (maybe I'm wrong on that). Of course it's also possible that this has changed the threshold enough to not need such logic anyway, and we can just always rent. |
|
@JonHanna excellent will give this a go |
|
Cool, the branch is https://github.com/JonHanna/corefx/tree/linq-array-pool-experiment if you want to grab the commit from there (I'm sure github has some way to find a branch with a commit and/or cherry-pick one without knowing it, but I don't know what it is). |
Sure # my fork, clone and checkout branch:
git clone https://github.com/jasonwilliams200ok/corefx
cd corefx
git checkout my-desired-wip-branch
# dotnet remote
git remote add dotnet https://github.com/dotnet/corefx
# your remote
git remote add jonhanna https://github.com/jonhanna/corefx
# first fetch your remote
git fetch jonhanna
# fetch will not merge or affect my branch in anyway
# find a commit I want from your branch: 'linq-array-pool-experiment'
git log jonhanna/linq-array-pool-experiment -10
(will show 10 commits, remove -10 to get all commits)
# cherry-pick a commit from any branch of your remote
git cherry-pick 950c153
# (generally, only first seven chars of commit has are required by git everywhere
# for example,
# https://github.com/JonHanna/corefx/commit/950c1533bc9fc709e66f7fc12f7dd48097318c0e
# vs.
# https://github.com/JonHanna/corefx/commit/950c153
# both point to same commit even on GitHub)
# conversely, to find what branch the commit belongs to:
git branch --contains 950c153
# outputs: linq-array-pool-experiment
# in case a commit has ancestry in many branches, it will list all of them
# to rebase my branch against one of your branch: 'linq-array-pool-experiment'
git pull --rebase jonhanna linq-array-pool-experiment
# to add commit(s) from your branch in my tree at a specific order
git rebase -i HEAD~4
# where 4 is number of commits in my branch I want to rearrange
# to accommodate commits from your branch.
# The interactive rebase command opens editor selected for git,
# I'd insert 'pick <commit-hash>', 'pick <commit hash>' where hashes are from
# your remote (or any remote I have added with 'git remote add')
# between the first four lines, save and close the editor.In case of merge conflicts in cherry-pick or rebase, the process will let you change the code and then you would need to |
|
@jasonwilliams200OK I don't see how you figured out which branch to do |
|
@JonHanna, given the commit, git can tell you which branch it belongs to with: |
|
@benaadams - just wonder if there still some work/investigation or plans to move forward with this PR? |
|
@VSadov needs some perf testing, will pursue it now tooling has been updated. |
|
@JonHanna's changes are much better; though don't seem to effect the Pre- allocs Post allocs |
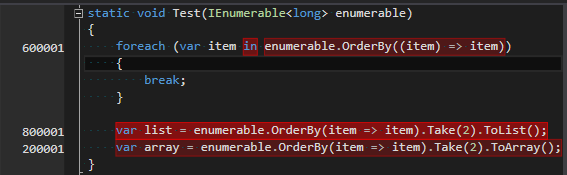
4c291cf
to
67179c1
Compare
|
Updated PR |
|
Its a little hard to measure as the allocations are so high; but across 1M+ iterations in 3 runs - so running on a 224GB RAM machine with server GC to cut down the GC interruptions before
after
So it looks better |
|
test Innerloop Windows_NT Debug Build and Test |
I'm not convinced. It looks like it might be ~1% faster, and maybe there's a gen0 GC improvement, but it's not clear. And this potential benefit has the cost of more complex code and a new dependency. I appreciate the effort, but do we really believe this is worthwhile and will have an impact that's worth the costs? |
Probably not; and it would cut the code out of any more holistic improvements (like stack promotion w/ escape analysis) if that ever happened. (I can hope 🎱 ) Will close |
ComputeMap's int[] array is used in limited private scope and only temporary for calculating the sort order.