

A full-featured aptamer bioinformatics software collection for the comprehensive analysis of HT-SELEX experiments providing both, command line and graphical user interfaces.
AptaSUITE is a platform independent implementation of multiple algorithms designed for the identification of aptamer candidate sequences and the analysis of the SELEX process per se.
AptaSUITE is designed to be scalable with both data size and CPU count while minimizing the memory footprint by providing fast, off-heap data structures and storage solutions.
In its core, AptaSUITE consists of a collection of APIs and corresponding implementations facilitating storage, retrieval, and manipulation of aptamer data (such as sequences, aptamer counts in individual selection cycles, structure information and more). On top of these core data structures, a number of previously published algorithms have been implemented. Currently, these are AptaPLEX, AptaSIM, AptaMUT, AptaCLUSTER, and AptaTRACE.
If you have any issues or recommendations, please feel free to open a ticket.
Download the latest precompiled version from the release page or build the project from source. Click here for a list of system requirments for different platforms.
To open the GUI, either double-click on the executable jar file called aptasuite-x.y.z.jar or call the jar file from command line without parameters (x.y.z corresponds to the version you downloaded):
$ java -jar aptasuite-x.y.z.jar
Then, follow the instructions on the screen to get started.
To work with the command line interface, create a configuration file and call the desired routines of aptasuite. For instance, to import a particular dataset, cluster it, perform sequence-structure identification, and to export the demultiplexed pools to file, you would call
$ java -jar path/to/aptasuite-x.y.z.jar -parse -cluster -predict structure -trace -export cycles
For a full list of commands, run
$ java -jar path/to/aptasuite-x.y.z.jar -help
Please see the Wiki for a detailed manual.
If you use AptaSuite in your work, please cite it as
AptaSUITE: A Full-Featured Bioinformatics Framework for the Comprehensive Analysis of Aptamers from HT-SELEX Experiments.
Hoinka, J., Backofen, R. and Przytycka, T. M. (2018).
Molecular Therapy - Nucleic Acids, 11, 515–517. https://doi.org/10.1016/j.omtn.2018.04.006
I addition, please cite the individual algorithms that aided your analysis. Details on how to cite these can be found in the Help -> How to Cite menu of the graphical user interface.
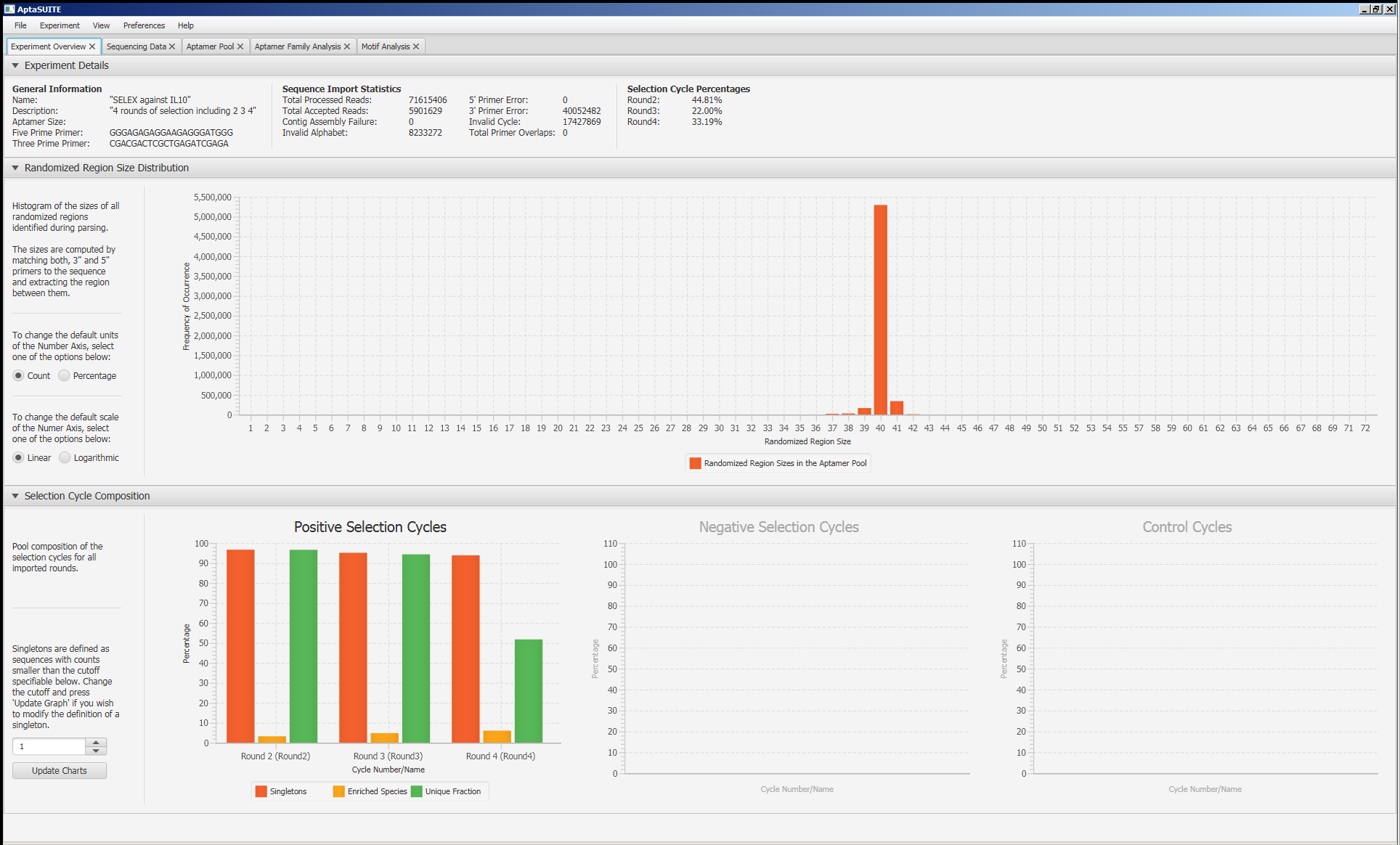 |
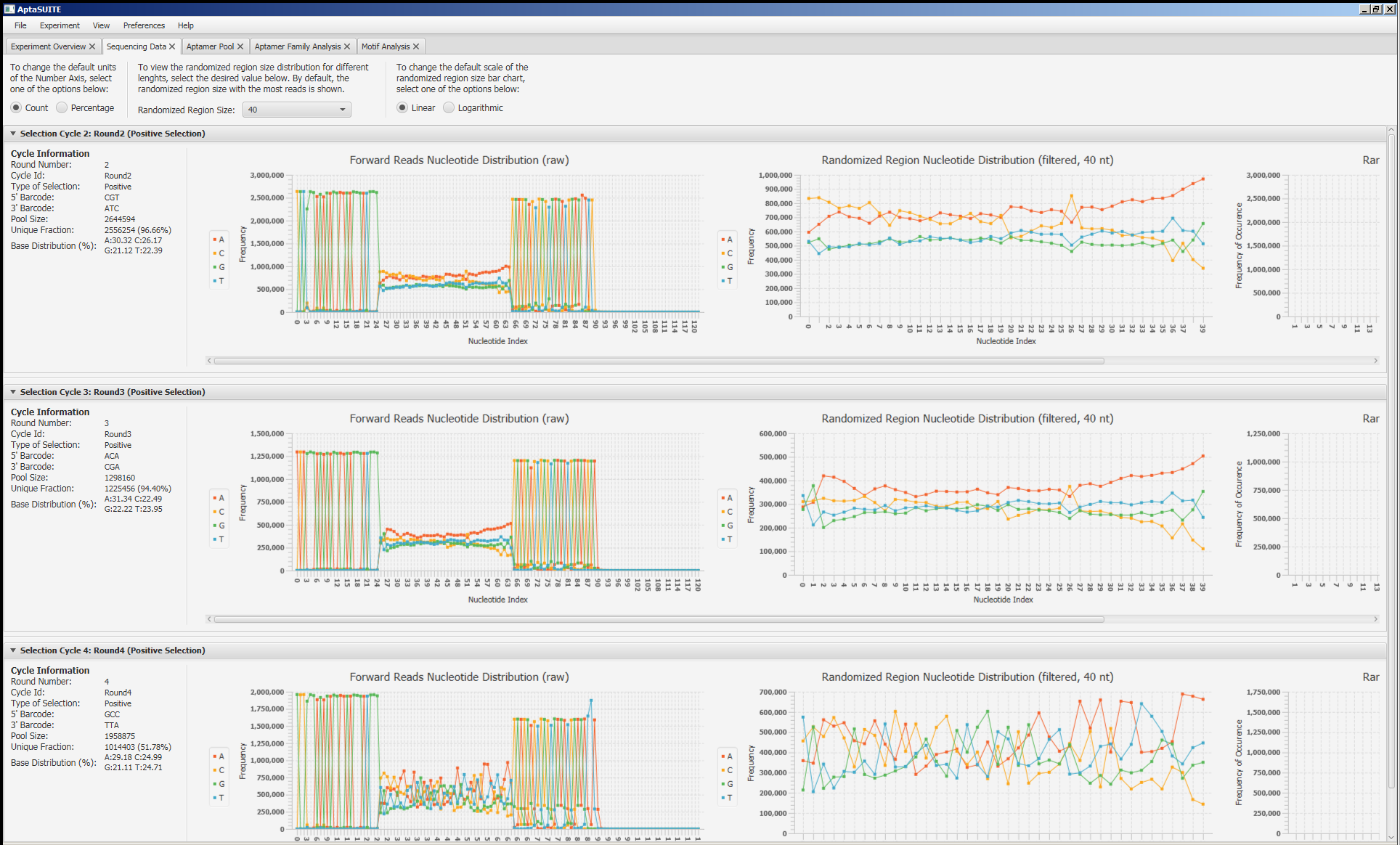 |
|---|---|
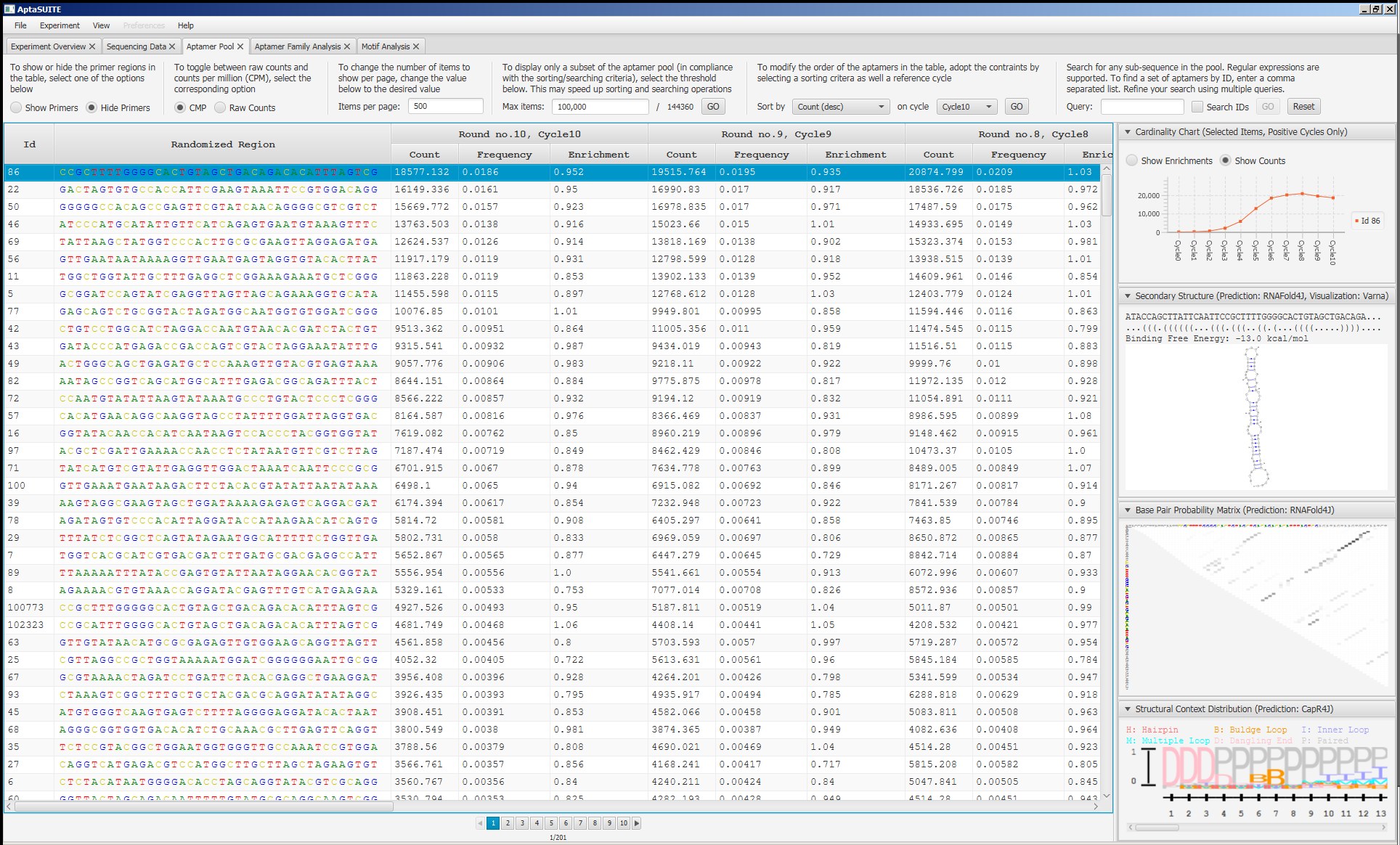 |
 |