{kind=link}
This dataset was the output of a project carried out by Aleph Insights and Committed Software on behalf of the Defence Science and Technology Laboratory (Dstl). The project aimed to create a 'gold standard' dataset that could be used to train and validate machine learning approaches to natural language processing (NLP); specifically focusing on entity and relationship extraction relevant to somebody operating in the role of a defence and security intelligence analyst. The dataset was therefore constructed using documents and structured schemas that were relevant to the defence and security analysis domain. Information about the dataset and the method used to build the dataset is summarised below.
The dataset is made up of a number of smaller datasets, which reflect the original source of the information. Each of these datasets may be under a separate licence, and licensing information is provided alongside the data.
Each dataset consists of three JSON files, which were exported from Mongo using mongoexport.
This file contains the documents themselves, along with metadata such as the original URL of the document. The fields are as follows:
{
_id,
title,
text,
sourceName,
sourceUrl,
wordCount,
sentenceCount
}
This file contains entities found within the dataset. The fields are as follows:
{
_id,
documentId,
begin,
end,
type,
value,
confidence
}
This file contains relationships found withing the dataset. The fields are as follows:
{
_id,
begin,
end,
sourceBegin,
sourceEnd,
source,
targetBegin,
targetEnd,
target,
type,
value,
documentId,
confidence
}
The text documents used as the basis for this dataset were selected on the basis of a dataset requirement framework (DSRF) which was developed specifically for this project. The DSRF required potential sources (i.e. the producers of text documents, such as media outlets) and the individual documents themselves to be assessed against a range of criteria before they were included in the dataset. In general terms the criteria sought to ensure:
- The dataset comprised task-specific documents focused on the topic of the conflict in Syria and Iraq;
- The dataset included a range of source and document types, which had differing levels of relevance to the overall ‘topic' of the dataset and possessed differing entity densities (i.e. some documents containing a high concentration of instances with others containing a lower concentration);
- Minimisation of the risk that the dataset included information which might contravene copyright legislation, be subject to data privacy/investigatory legislation, or contain graphic or potentially libellous material.
The dataset was annotated using two separate schemas for entities and relationships. The schema for entity types was inherited from previous work (notably the development of Baleen (specifically version 2.3)) and the schema for relationship categorisation was developed during the project. The schemas were not developed to be comprehensive, but merely to identify a range of entities and relationships that were likely to be of interest to an intelligence analyst. Various rules were developed throughout the project for the interpretation of the category types. The two schemas are presented in the tables below.
| Entity Name | Description |
|---|---|
| CommsIdentifier | An alias used to represent people, places, military units in electronic communication etc. Could be a call sign, an email address, a twitter handle. |
| DocumentReference | A unique (or semi unique) identifier for a document. |
| Frequency | A radio frequency used in electronic communication. |
| Location | A specific point, area or feature on earth. May be named (e.g. a city name) or referenced (e.g. with a coordinate systems) |
| MilitaryPlatform | A military ship, aeroplane, land vehicle or system or platform onto which weapons might be mounted. May be indicated by its abstract class (e.g. "tank"), or by specific designation or other aliases (e.g. "T-14 Armata") |
| Money | An amount of money or reference to currency |
| Nationality | Description of nationality, religious or ethnic identity |
| Organisation | A group of people, a government, a company, or a family. May be referenced by name (e.g. "the British Army") or in relying on context (e.g. "the Army"). May also be indicated by an abstract class (e.g. "rebels"). |
| Person | A specific person. May be a name (e.g. Barack Obama); by title, (e.g. "President of the United States"); a combination of title and name (e.g. "President Obama"); or by reference to some other entity (e.g. "The US's head of state") |
| Quantity | A quantity or amount of something (e.g. "1 kg") |
| Temporal | A specific date, or time or range of time (e.g. 10:30 PST; 12/09/2016; "Next week"; "Wednesday") |
| Url | A web URL |
| Vehicle | A non-military maritime, land or air vehicle. May be indicated by its abstract class (e.g. "airliner"); by a specific vehicle name (e.g. "Boeing 777"); or another related identifier (e.g. its flight name "MH370") |
| Weapon | A weapon. May be indicated by its abstract class (e.g. "rifle"), or by specific name or alias (e.g. "AK-47") |
| Relationship Name | Description |
|---|---|
| Co-located | Two or more entities in the same place at a given time (e.g. two vehicles being co-located) |
| Apart | Two or more entities in different places at a given time (e.g. two people being apart) |
| Belongs to | One entity being owned by another entity (e.g. one vehicle belonging to a person); or an entity being a member of another entity (e.g. a person being a member of an organisation) |
| In charge of | One entity controlling or having responsibility for another entity (e.g. an organisation being in charge of a building) |
| Has the attribute of | One entity being an attribute or associated quality of another entity (e.g. a type of weapon having the attribute of a quantity or a person having the attribute of a nationality) |
| Is the same as | One entity being used to mean the same thing as another entity (e.g. multiple names for the same person) |
| Likes | One entity being positively disposed towards another (e.g. a person likes a military platform) |
| Dislikes | One entity being negatively disposed towards another (e.g. a person dislikes another person) |
| Fighting against | One entity being in armed conflict against another entity (e.g. an organisation is fighting against another organisation) |
| Military allies of | One entity fighting alongside another entity on the same side of a conflict (e.g. one person being a military ally of another person) |
| Communicated with | An entity has had direct or indirect contact with another entity (e.g. met, spoken with, communicated remotely with, messaged, emailed) |
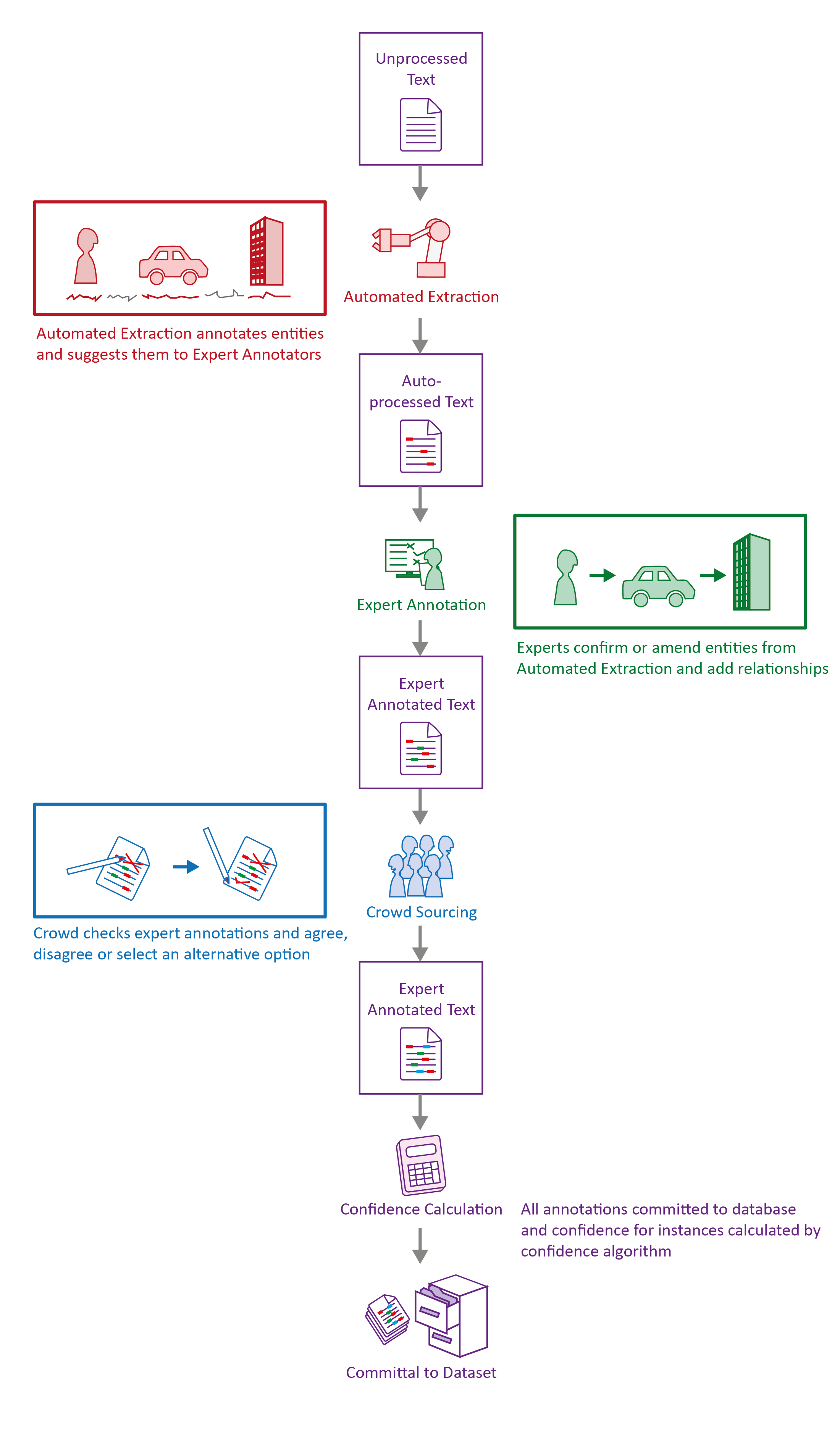
A hybrid approach, which combined automated extraction, expert annotation and crowdsourcing, was used to annotate the selected documents using the schemas described above. This hybrid approach involved the following sequential steps:
- Automated Extraction - where the Baleen automated extraction tool was applied to unprocessed text to assign entities to the text, acting as an initial cue for a human annotator;
- Expert Annotation - where domain experts within the project team applied entity and relationship annotations to text using a bespoke annotation tool developed for a related project;
- Crowdsourcing - where crowd workers were presented with text containing highlighted instances identified by the experts using Amazon's Mechanical Turk crowdsourcing platform, and were asked to provide their own classification of these annotations;
- Confidence Calculation - where confidence scores were calculated using a Bayesian model of annotation data generation ('IBCC'), to generate probability distributions for the ‘correct' annotation for each instance;
- Committal to Dataset - where all of the data described above was integrated, committed and stored in the underlying database, enabling retrieval, interrogation and, ultimately, its utilisation as a training or validation dataset.
Each part of the dataset is licensed separately. For licence information, see the LICENSE file in each sub-folder for full details. If you have any queries regarding this dataset, please contact oss@dstl.gov.uk.