
This is a collection of perception scripts primarily aimed at use in a social robotics context. It combines various Deep Learning classifiers to build a model of people and their attributes. Working so far are modules for:
- Detection of 68 Face landmarks to be used by classifiers based on Dlib 68 Landmark
- Face ID using the 128D vector embedding from Dlib, in addition with some simple clustering logic
- Emotion recognition using iCog Emopy
- Eyes closed detection based on iCog EyeState Detection
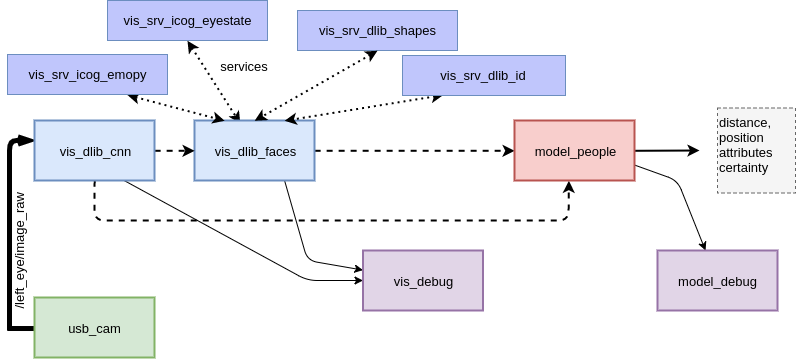
In addition this repository contains some config files and experimental scripts for use of this package on Hanson Robotics humanoid robots.
Currently, there are two publishers in ros_peoplemodel. One that outputs the integrated raw perceptions from the various modules at the topic /vis_dlib_faces, the other one applies some probabilistic smoothing of position and attributes and is published on /faces. You can demo this by launching the vis_debug.py script for raw perceptions and model_debug.py for probabilistic model.
Raw output at /vis_dlib_faces outputs raw array of Feature.msg messages, which include the following information. Note that all attributes can be empty in case of detection failure.
# Required fields:
sensor_msgs/Image crop
sensor_msgs/RegionOfInterest roi
# Optional fields
geometry_msgs/Point[] shapes
string face_id
float32[] emotions
float32[] eye_states
Probabilistic output at /faces outputs the following Feature.msg message. Note the added information of position and certainty added in this stage. Also note that all attributes can be empty in case of detection failure.
# Required fields:
sensor_msgs/Image crop
# World coordinates:
geometry_msgs/Point position
float32 certainty
# Attributes
geometry_msgs/Point[] shapes
string face_id
float32[] emotions
float32[] eye_states
Most of the modules used depend on GPU accelerated Dlib or Tensorflow. In order to use it please do the following:
- Install compatible NVIDIA drivers, CUDA and cuDNN.
- Install Dlib from source using graphics acceleration support (after compilation and all dependencies are installed, follow the instructions for Compiling Dlib's Python Interface)
- Install tensorflow-gpu.
- Install additional dependencies
numpy,scikit-images,opencv.
Upon first launch the system will download the necessary classifier models and extract them to the home folder of the user in ~/.dlib.
In launch/ there are several scripts to test the architecture:
webcam_single.launch: Can be used to launch the /camera node that will publish camera image.perception.launch: Launches the entire architecture as described above.- In addition
scripts/vis_debug.pywill show a window for debugging output of the raw visual perception scripts. - In addition
scripts/model_debug.pywill show a window for debugging the output of model_people node, which fuses the various visual classifiers into a model of perceived faces.
- Integration with a classifier for speaking detection
- Eventual integration with directional microphone to map what is spoken to individual faces.
- Integration with OpenPose and various classifiers for
- Body pose estimation (sitting, standing, waving, etc.)
- Hand pose estimation (open palm, fist, etc.)
- Integration wih Masked RCNN architectures to detect various categories of objects in the hands of people.
- Better packaging and setup.py