![]()
💥 CoAdapter:
🎨Demos | ⏬Download Models | 💻How to Test | 🏰Adapter Zoo
Official implementation of T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models.
- ✅ Mar. 16, 2023. We add CoAdapter (Composable Adapter). The online Huggingface Gadio has been updated
. You can also try the local gradio demo.
- ✅ Mar. 16, 2023. We have shrunk the git repo with bfg. If you encounter any issues when pulling or pushing, you can try re-cloning the repository. Sorry for the inconvenience.
- ✅ Mar. 3, 2023. Add a color adapter (spatial palette), which has only 17M parameters.
- ✅ Mar. 3, 2023. Add four new adapters style, color, openpose and canny. See more info in the Adapter Zoo.
- ✅ Feb. 23, 2023. Add the depth adapter t2iadapter_depth_sd14v1.pth. See more info in the Adapter Zoo.
- ✅ Feb. 15, 2023. Release T2I-Adapter.
🔥🔥🔥 Support CoAdapter (Composable Adapter).
You can find the details and demos about CoAdapter from coadapter.md




We propose T2I-Adapter, a simple and small (~70M parameters, ~300M storage space) network that can provide extra guidance to pre-trained text-to-image models while freezing the original large text-to-image models.
T2I-Adapter aligns internal knowledge in T2I models with external control signals. We can train various adapters according to different conditions, and achieve rich control and editing effects.

Put the downloaded models in the T2I-Adapter/models folder.
- You can find the pretrained T2I-Adapters, CoAdapters, and third party models from https://huggingface.co/TencentARC/T2I-Adapter.
- A base SD model is still needed to inference. We recommend to use Stable Diffusion v1.5. But please note that the adapters should work well on other SD models which are finetuned from SD-V1.4 or SD-V1.5. You can download these models from HuggingFace or civitai, all the following tested models (e.g., Anything anime model) can be found in there.
- [Optional] If you want to use mmpose adapter, you need to download the pretrained keypose detection models include FasterRCNN (human detection) and HRNet (pose detection).
- Python >= 3.6 (Recommend to use Anaconda or Miniconda)
- PyTorch >= 1.4
pip install -r requirements.txt- If you want to use the full function of keypose-guided generation, you need to install MMPose. For details please refer to https://github.com/open-mmlab/mmpose.
We provide some example inputs in huggingface, you can download these examples by:
python examples/download_examples.pyYou need to download the pretrained CoAdapters from huggingface first, and put them in the models folder
# test for stable diffusion v1.5
python app_coadapter.py --sd_ckpt models/v1-5-pruned-emaonly.ckpt# test for stable diffusion v1.5
python app.py --sd_ckpt models/v1-5-pruned-emaonly.ckpt
# test for other stable diffusion model, like Anything 4.5
python app.py --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt# when input color image
python test_adapter.py --which_cond color --cond_path examples/color/color_0002.png --cond_inp_type color --prompt "A photo of scenery" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_color_sd14v1.pth --scale 9
# when input non-color image, obtain the color image is also straightforward, just bicubic downsample to low res and nearst upsample normal res
python test_adapter.py --which_cond color --cond_path examples/sketch/scenery.jpg --cond_inp_type image --prompt "A photo of scenery" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_color_sd14v1.pth --scale 9

# when input non-depth image
python test_adapter.py --which_cond depth --cond_path examples/depth/sd.png --cond_inp_type image --prompt "Stormtrooper's lecture, best quality, extremely detailed" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_depth_sd14v1.pth
# when input depth image
python test_adapter.py --which_cond depth --cond_path examples/depth/desk_depth.png --cond_inp_type depth --prompt "desk, best quality, extremely detailed" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_depth_sd14v1.pth

# when input canny image
python python test_adapter.py --which_cond canny --cond_path examples/canny/toy_canny.png --cond_inp_type canny --prompt "Cute toy, best quality, extremely detailed" --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_canny_sd14v1.pth
# when input non-canny image
python python test_adapter.py --which_cond canny --cond_path examples/canny/rabbit.png --cond_inp_type image --prompt "A rabbit, best quality, extremely detailed" --sd_ckpt models/sd-v1-4.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_canny_sd14v1.pth

# when input sketch image
python test_adapter.py --which_cond sketch --cond_path examples/sketch/car.png --cond_inp_type sketch --prompt "A car with flying wings" --sd_ckpt models/sd-v1-4.ckpt --resize_short_edge 512 --cond_tau 0.5 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_sketch_sd14v1.pth
# when input non-sketch image
python test_adapter.py --which_cond sketch --cond_path examples/sketch/girl.jpeg --cond_inp_type image --prompt "1girl, masterpiece, high-quality, high-res" --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_sketch_sd14v1.pth


# when input non-pose image
python test_adapter.py --which_cond openpose --cond_path examples/openpose/iron_man_image.png --cond_inp_type image --prompt "Iron man, high-quality, high-res" --sd_ckpt models/sd-v1-5.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 1 --adapter_ckpt models/t2iadapter_openpose_sd14v1.pth
# when input openpose image
python test_adapter.py --which_cond openpose --cond_path examples/openpose/iron_man_pose.png --cond_inp_type openpose --prompt "Iron man, high-quality, high-res" --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 1 --adapter_ckpt models/t2iadapter_openpose_sd14v1.pth

# when input non-pose image
python test_adapter.py --which_cond keypose --cond_path examples/sketch/girl.jpeg --cond_inp_type image --prompt "1girl, masterpiece, high-quality, high-res" --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 1 --adapter_ckpt models/t2iadapter_keypose_sd14v1.pth
# when input pose image
python test_adapter.py --which_cond keypose --cond_path examples/keypose/person_keypose.png --cond_inp_type keypose --prompt "astronaut, best quality, extremely detailed" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_keypose_sd14v1.pth

# currently, only seg input is supported, if you need image as input, please let us know
python test_adapter.py --which_cond seg --cond_path examples/seg/motor.png --cond_inp_type seg --prompt "A black Honda motorcycle parked in front of a garage, best quality, extremely detailed" --sd_ckpt models/v1-5-pruned-emaonly.ckpt --resize_short_edge 512 --cond_tau 1.0 --cond_weight 1.0 --n_samples 2 --adapter_ckpt models/t2iadapter_seg_sd14v1.pth

# test depth + keypose
python test_composable_adapters.py --prompt "1girl, computer desk, red chair best quality, extremely detailed" --depth_path examples/depth/desk_depth.png --depth_weight 1.0 --depth_adapter_ckpt experiments/train_depth/models/model_ad_70000.pth --depth_inp_type depth --keypose_path examples/keypose/person_keypose.png --keypose_inp_type keypose --keypose_adapter_ckpt models/t2iadapter_keypose_sd14v1.pth --keypose_weight 1.5 --cond_tau 0.7 --sd_ckpt models/anything-v4.5-pruned-fp16.ckpt --vae_ckpt models/anything-v4.0.vae.pt --n_sample 8 --max_resolution 524288
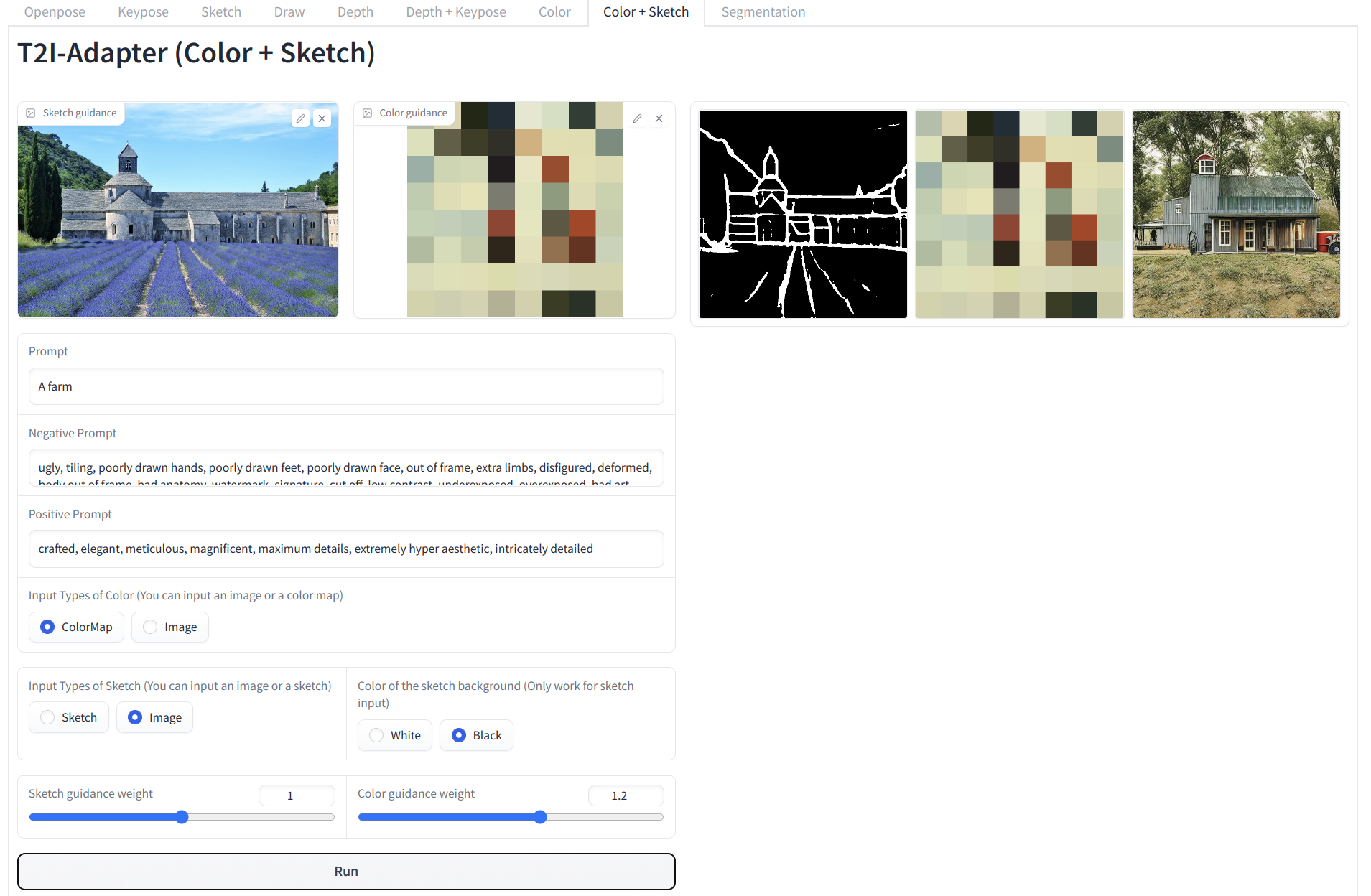
# test color + sketch
python test_composable_adapters.py --prompt "A farm, best quality, extremely detailed" --sketch_path examples/sketch/scenery.jpg --sketch_weight 1.0 --sketch_adapter_ckpt models/t2iadapter_sketch_sd14v1.pth --sketch_inp_type image --color_path examples/color/color_0001.png --color_inp_type image --color_adapter_ckpt models/t2iadapter_color_sd14v1.pth --color_weight 1.2 --cond_tau 1.0 --sd_ckpt models/v1-5-pruned-emaonly.ckpt --n_sample 1 --resize_short_edge 512
# test sketch + style
python test_composable_adapters.py --prompt "car" --sketch_path examples/sketch/car.png --sketch_weight 1.0 --sketch_adapter_ckpt models/t2iadapter_sketch_sd14v1.pth --sketch_inp_type image --style_path examples/style/cyberpunk.png --style_inp_type image --style_adapter_ckpt models/t2iadapter_style_sd14v1.pth --cond_tau 1.0 --sd_ckpt models/v1-5-pruned-emaonly.ckpt --n_sample 1 --resize_short_edge 512 --scale 9


The following is the detailed structure of a Stable Diffusion model with the T2I-Adapter.

The corresponding edge maps are predicted by PiDiNet. The sketch T2I-Adapter can well generalize to other similar sketch types, for example, sketches from the Internet and user scribbles.

The keypose results predicted by the MMPose. With the keypose guidance, the keypose T2I-Adapter can also help to generate animals with the same keypose, for example, pandas and tigers.

Once the T2I-Adapter is trained, it can act as a plug-and-play module and can be seamlessly integrated into the finetuned diffusion models without re-training, for example, Anything-4.0.


When combined with the inpaiting mode of Stable Diffusion, we can realize local editing with user specific guidance.


Adapter can be used to enhance the SD ability to combine different concepts.

We can realize the sequential editing with the adapter guidance.

Stable Diffusion results guided with the segmentation and sketch adapters together.

Thank haofanwang for providing a tutorial of T2I-Adapter diffusers.