Scripts to manage my digital comics collection.
CBZ utility can be used on both archives, to cleanup existing cbz/cbr/cb7, and folders, to create a new cbz archive. Folders are processed recursively to find folders containing files, but archives inside a processed folder won't be cleaned up. Options include:
- preserving OSX tags (for archives only)
- flatten the directory structure (same as -j option on zip)
- rename files using natural sort
Thanks to The Unarchiver, you can also process PDF files for cleanup !
Requires
- Python 2.7+
- jdberry/tag (if using the --tags option) (
brew install tag) - natsort (
pip install natsort) - The Unarchiver command line tools (
brew install unar)
Usage
usage: cbz.py [-h] [-t] [-r] [-f] [-d DESTINATION] infiles [infiles ...]
CBZ utility
positional arguments:
infiles
optional arguments:
-h, --help show this help message and exit
-t, --tags Preserve OSX tags (uses
https://github.com/jdberry/tag)
-r, --rename Rename files using natural sort
-f, --flatten Flatten archive by removing folder structure
-d DESTINATION, --destination DESTINATION
Destination for processed files. If unspecified
working directory is used instead
OSX Automator
You can hook up the scripts using Automator to have a right-click action:
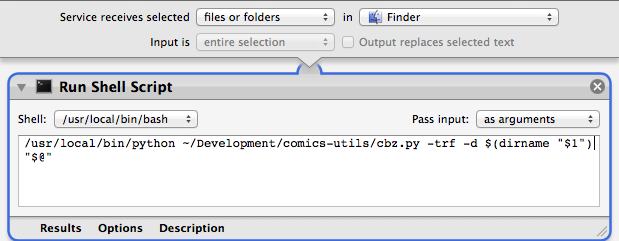
You can also configure it as a folder action, to automatically perform post-processing for instance:
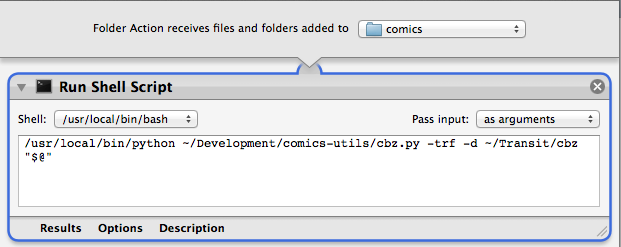
Use OSX tags to create a replica of your directory structure for easy synchronization with any third party tool or cloud provider.
Folders have to be tagged sync (works on parent folders as well).
Files tagged read are ignored.
You have to edit the source code to change the source and destination folders.
Requires
- Python 2.7+
- jdberry/tag
Usage
> python sync-folder.py