[ClickHouse vs Vertica vs GreenPlum] Сравнение производительности аналитических СУБД
https://clickhouse.yandex/benchmark.html

Excel как инструмент Проектирования хранилищ данных DWH Data Warehous
https://www.youtube.com/watch?v=5ThDc3PTpo4&index=32&list=PLrTrFnOkIFb0G8u6VwtUSbIgZDERNyAvm
[Николай Голов] Нюансы реализации колоночного хранения данных [Avito]
https://www.youtube.com/watch?v=Mu4K4T-SRfc&feature=youtu.be
[Николай Голов] Как мы считали трафик на Вертике [Авито]
https://www.youtube.com/watch?v=F3pCSytpZ6Q&list=PLrTrFnOkIFb0G8u6VwtUSbIgZDERNyAvm&index=35
[Николай Голов] зачем нужна нормализация в Big Data [Авито]
https://www.youtube.com/watch?v=2er-jebT9T0&list=PLrTrFnOkIFb0G8u6VwtUSbIgZDERNyAvm&index=33
[Николай Голов] Lambda architecture для realtime аналитики [Авито]
https://www.youtube.com/watch?v=D98nNXQMBso&list=PLrTrFnOkIFb0G8u6VwtUSbIgZDERNyAvm&index=34
VoltDB In-Memory Database Achieves Best-In-Class Results, Running in the Cloud, On the YCSB Benchmark https://www.voltdb.com/blog/2014/05/07/voltdb-memory-database-achieves-best-class-results-running-cloud-ycsb-benchmark/
https://drive.google.com/drive/folders/1YqYZIwWFvy1lP1NMOxrhZrMX7xZj-628
СУБД VoltDB 3.0, развиваемой под руководством Майкла Стоунбрейкера (Mike Stonebraker), одного из основателей проектов Ingres и PostgreSQL. СУБД VoltDB поддерживает горизонтальное масштабирование и ориентирована на обработку транзакций в реальном времени (OLTP). На недорогом кластере, собранном своими силами из обычных серверов, СУБД способна обрабатывать миллионы транзакций в секунду.

Идея VoltDB заключается в том, что все транзакции выполняются с помощью предварительно скомпилированных хранимых процедур, реализованных на Java, и все хранимые процедуры сериализуются, что позволяет VoltDB достичь самого высокого уровня изоляции и устранения блокировок. Использование устройства очень хорошее. В официальных результатах испытаний VoltDB может легко масштабироваться до 39 серверов (300 ядер), 120 разделов, обрабатывающих 1,6 миллиона сложных транзакций в секунду.
Разгадка высокой производительности VoltDB кроется в непохожей на традиционные схемы внутренней архитектуре, комбинирующей хранение данных в памяти с концепцией распределенной организации и разбиением содержимого БД по разделам (партицирование). Производительность VoltDB увеличивается почти линейно при добавлении дополнительных серверов в кластер. Каждый однопоточный раздел работает в автономном режиме, что исключает необходимость в блокировках и фиксации операций. Данные автоматически реплицируются внутри кластера, что позволяет добиться высокой доступности и исключает необходимость ведения журнала. Все данные каждого узла полностью прокэшированы в ОЗУ, что обеспечивает максимальную пропускную способность и исключает необходимость буферизации.
На одном сервере запускается несколько узлов VoltDB, каждый из которых привязывается к отдельному ядру CPU. Для сохранения данных на диск используется концепция снапшотов, отражающих срез данных, актуальных на момент создания снапшота. Работа с данными осуществляется через хранимые процедуры на языке Java, копии которых прикрепляются к каждому из разделов (ODBC/JDBC и прямое выполнение SQL-операторов для всей базы не поддерживается). При выполнении запроса, затрагивающего несколько разделов, в каждом из нужных разделов вызывается хранимая процедура, а затем результаты агрегируются.
Утилита voltadmin с реализация интерфейса командной строки для централизованного управления всем кластером VoltDB;
Для упрощения разработки высокопроизводительных приложений добавлена поддержка шаблона project.xml для размещения данных в кластере и команды compile для автоматической компиляции схемы. Расширены возможности изменения схемы БД на лету, добавлены команды для создания и изменения индексов, применимые для работающего кластера;
Используя распределенную в режиме реального времени среду вычислений Storm, как клиента VoltDB и потребителя Kafka, в полной мере используйте высокую доступность и низкую задержку структуры Storm. От генерации данных до входа в VoltDB задержка по каждому сегменту находится в пределах 16 мс. Если оптимизирована для агрегации небольших партийных записей, она может повысить пропускную способность, но уменьшить задержку записи.
Zookeeper сохраняет данные в конфигурации правил VoltDB, а топология Storm определяет данные, записанные в VoltDB через конфигурацию прослушивания. Из-за необходимости создания разумной схемы, стратегии хранения данных и приложений индекса, основанных на бизнес-сценариях.
Zookeeper для динамической конфигурации в реальном времени, которая может управлять измененными данными в VoltDB, а также управлять данными в разных схемах (одна и та же таблица, но с использованием разных стратегий разбиения на разделы и разбиение на несколько таблиц) ,

Таким образом, создается платформа приложений VoltDB с ежедневной записью 1 миллиарда записей в и из VoltDB и 24-часовых данных.
Aqua Data Studio provides a management tool for the VoltDB[1] relational database with administration capabilities and a database query tool.


При выполнении запроса Join также требуется соблюдать правило разделения VoltDB, из-за большого объема данных существуют определенные различия в структуре данных, а ресурсы памяти топологии Storm всегда ограничены.
Таким образом, мы использовали Zookeeper для динамической конфигурации в реальном времени, которая может управлять измененными данными в VoltDB, а также управлять данными в разных схемах (одна и та же таблица, но с использованием разных стратегий разбиения на разделы и разбиение на несколько таблиц) ,
====================
Thank you for your interest in VoltDB!
VoltDB is a horizontally-scalable, in-memory SQL RDBMS designed for applications that benefit from strong consistency, high throughput and low, predictable latency.
====================
VoltDB offers the fully open source, AGPL3-licensed Community Edition of VoltDB through GitHub here:
https://github.com/voltdb/voltdb/
Binary downloads of this edition and 30-day trials of the commercial editions of VoltDB can be downloaded from the VoltDB website at the following URL:
https://www.voltdb.com/try-voltdb/
The Community Edition has full application compatibility and provides everything needed to run a real-time, in-memory SQL database with datacenter-local redundancy and snapshot-based disk persistence.
The commercial editions add operational features to support industrial strength durability and availability, including per-transaction disk-based persistence, multi-datacenter replication, elastic online expansion, live online upgrade, etc..
For more information, please see our "Editions" page:
https://www.voltdb.com/product/editions/
====================
The latest development branch is master. We develop features on branches and merge to master when stable. While master is usually stable, it should not be considered production-ready and may also have partially implemented features.
Code that corresponds to released versions of VoltDB are tagged "voltdb-X.X" or "voltdb-X.X.X". To build corresponding OSS VoltDB versions, use these tags.
====================
Information on building VoltDB from this source repository is maintained in a GitHub wiki page available here:
https://github.com/VoltDB/voltdb/wiki/Building-VoltDB
====================
From the directory where you installed VoltDB, you can either use bin/{command} or add the bin folder to your path so you can use the VoltDB commands anywhere. For example:
PATH="$PATH:$(pwd)/bin/"
voltdb --version
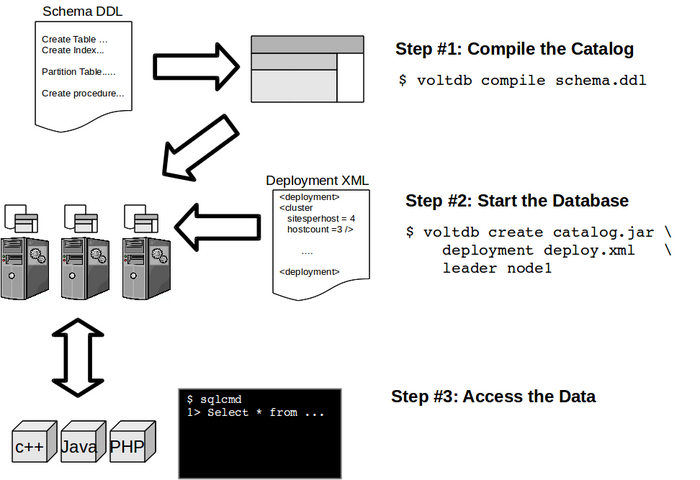
Then, initialize a root directory and start a single-server database. By default the root directory is created in your current working directory. Or you can use the --dir option to specify a location:
voltdb init [--dir ~/mydb]
voltdb start [--dir ~/mydb] [--background]
To start a SQL console to enter SQL DDL, DML or DQL:
sqlcmd
To launch the web-based VoltDB Management Console (VMC), open a web browser and connect to localhost on port 8080 (unless there is a port conflict): http://localhost:8080.
To stop the running VoltDB cluster, use the shutdown command. For commercial customers, the database contents are saved automatically by default. For open-source users, add the --save argument to manually save the contents of your database:
voltadmin shutdown [--save]
Then you can simply use the start comment to restart the database:
voltdb start [--dir ~/mydb] [--background]
Further guidance can be found in the tutorial: https://docs.voltdb.com/tutorial/. For more on the CLI, see the documentation: https://docs.voltdb.com/UsingVoltDB/clivoltdb.php.
You can find application examples in the “examples” directory inside this VoltDB kit.
The Voter app (“examples/voter”) is a great example to start with. See the README to learn what it does and how to get it running, or watch this 5 minute video demonstration of the Voter app: https://voltdb.com/resources/video/voltdb-how-tour-voter-example
The App Gallery has more information on additional examples, some in the kit and some on GitHub.
- App Gallery: https://voltdb.com/community/applications
- Supplemental Examples: https://github.com/VoltDB/?query=app-
The VoltDB Tutorial will walk you through building and running your first VoltDB application.
https://docs.voltdb.com/tutorial/
The VoltDB User Guide and supporting documentation is comprehensive and easy to use. It’s a great place for broad understanding or to look up something specific.
The VoltDB Product page contains info at a higher level. This page has in-depth descriptions of features that explain not just what, but why. It also covers use cases and competitive comparisons.
For information on using VoltDB virtualized, containerized or in the Cloud, see the the VoltDB website.
https://voltdb.com/run-voltdb-virtualized-containerized-or-cloud
If you have installed VoltDB from the distribution kit, you now have a directory containing this README file and several subdirectories, including:
- bin - Scripts for starting VoltDB, bulk loading data, as well as interacting with and managing the running database. Including:
- bin/voltdb - Start a VoltDB process.
- bin/voltadmin - CLI to manage a running cluster.
- bin/sqlcmd - SQL console.
- doc - Documentation, tutorials, and java-doc
- examples - Sample programs demonstrating the use of VoltDB
- lib - Third party libraries
- tools - XML schemas, monitoring plugins, and other tools
- voltdb - the VoltDB binary software itself including:
- license.xml - An embedded trial license.
- log4j files - Logging configuration.
- voltdbclient-version.jar - Java/JVM client for connecting to VoltDB, including native VoltDB client and JDBC driver.
- voltdb-version.jar - The full VoltDB binary, including platform-specific native libraries embedded within the jar. This is a superset of the client code and can be used as a native client driver or JDBC driver.
====================
VoltDB offers a pre-built binary distribution of VoltDB under a commercial license. It can be downloaded from the VoltDB website. This download includes a 30 day trial license.
When to use this open-source version:
- When developing applications (as long as they don't need VoltDB Export).
- When performance testing in non-redundant configurations.
- When reading or modifying source code.
When to use the commercial version:
- When disk persistence is required.
- When the VoltDB Export feature is required.
- When high availability features like redundant clustering, live node rejoin, and multi-datacenter replication are required.
If you have any questions or comments about VoltDB, we encourage you to reach out to the VoltDB team and community.
- VoltDB Forums - Create threads, post responses and search existing posts on our community forums at https://forum.voltdb.com.
- VoltDB Community Slack Channel - Get an invite to chat with community members and the VoltDB team at http://chat.voltdb.com.
This program is free software distributed under the terms of the GNU Affero General Public License Version 3. See the accompanying LICENSE file for details on your rights and responsibilities with regards to the use and redistribution of VoltDB software.