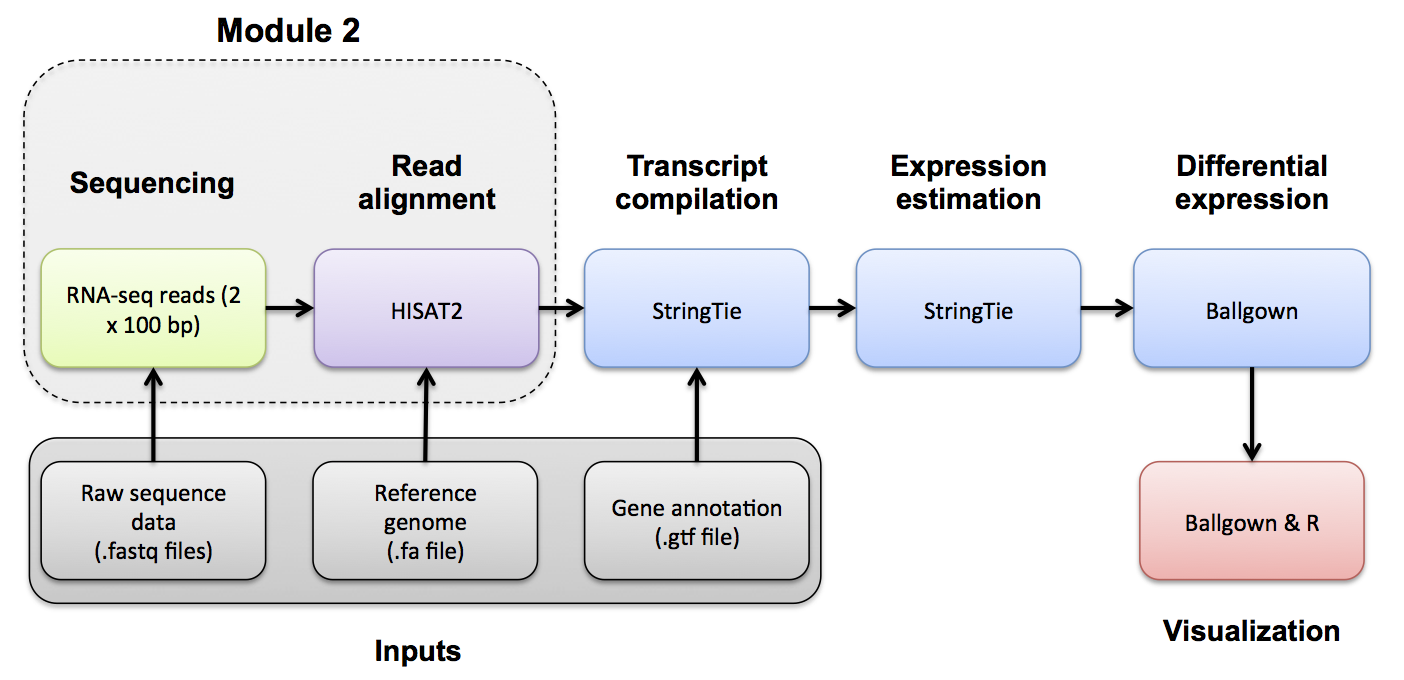
PostAlignment Visualization
Before we can view our alignments in the IGV browser we need to index our BAM files. We will use samtools index for this purpose. For convenience later, index all bam files.
echo $RNA_ALIGN_DIR
cd $RNA_ALIGN_DIR
find *.bam -exec echo samtools index {} \; | sh
Start IGV on your laptop. Load the UHR.bam & HBR.bam files in IGV. You can load the necessary files in IGV directly from your web accessible amazon workspace (see below) using 'File' -> 'Load from URL'. You may wish to customize the track names as you load them in to keep them straight. Do this by right-clicking on the alignment track and choosing 'Rename Track'.
UHR hisat2 alignment:
http://YOUR_DNS_NAME/workspace/rnaseq/alignments/hisat2/UHR.bam
HBR hisat2 alignment:
http://YOUR_DNS_NAME/workspace/rnaseq/alignments/hisat2/HBR.bam
Go to an example gene locus on chr22:
- e.g. EIF3L, NDUFA6, and RBX1 have nice coverage
- e.g. SULT4A1 and GTSE1 are differentially expressed. Are they up-regulated or down-regulated in the brain (HBR) compared to cancer cell lines (UHR)?
- Mouse over some reads and use the read group (RG) flag to determine which replicate the reads come from. What other details can you learn about each read and its alignment to the reference genome.
Try to find a variant position in the RNAseq data:
- HINT: DDX17 is a highly expressed gene with several variants in its 3 prime UTR.
- Other highly expressed genes you might explore are: NUP50, CYB5R3, and EIF3L (all have at least one transcribed variant).
- Are these variants previously known (e.g., present in dbSNP)?
- How should we interpret the allele frequency of each variant? Remember that we have rather unusual samples here in that they are actually pooled RNAs corresponding to multiple individuals (genotypes).
- Take note of the genomic position of your variant. We will need this later.
Using one of the variant positions identified above, count the number of supporting reference and variant reads.
First, use samtools mpileup to visualize a region of alignment with a variant.
cd $RNA_HOME
mkdir bam_readcount
cd bam_readcount
Create faidx indexed reference sequence file for use with mpileup
echo $RNA_REF_FASTA
samtools faidx $RNA_REF_FASTA
Run samtools mpileup on a region of interest
samtools mpileup -f $RNA_REF_FASTA -r 22:18918457-18918467 $RNA_ALIGN_DIR/UHR.bam $RNA_ALIGN_DIR/HBR.bam
Each line consists of chromosome, 1-based coordinate, reference base, the number of reads covering the site, read bases and base qualities. At the read base column, a dot stands for a match to the reference base on the forward strand, a comma for a match on the reverse strand, ACGTN for a mismatch on the forward strand and acgtn for a mismatch on the reverse strand. A pattern \+[0-9]+[ACGTNacgtn]+ indicates there is an insertion between this reference position and the next reference position. The length of the insertion is given by the integer in the pattern, followed by the inserted sequence. See samtools pileup/mpileup documentation for more explanation of the output:
Now, use bam-readcount to count reference and variant bases at a specific position.
First, create a bed file with some positions of interest (we will create a file called snvs.bed using the echo command).
It will contain a single line specifying a variant position on chr22 e.g.:
22 38483683 38483683
Create the bed file
echo "22 38483683 38483683"
echo "22 38483683 38483683" > snvs.bed
Run bam-readcount on this list for the tumor and normal merged bam files
bam-readcount -l snvs.bed -f $RNA_REF_FASTA $RNA_ALIGN_DIR/UHR.bam 2>/dev/null
bam-readcount -l snvs.bed -f $RNA_REF_FASTA $RNA_ALIGN_DIR/HBR.bam 2>/dev/null
Now, run again, but ignore stderr and redirect stdout to a file:
bam-readcount -l snvs.bed -f $RNA_REF_FASTA $RNA_ALIGN_DIR/UHR.bam 2>/dev/null 1>UHR_bam-readcounts.txt
bam-readcount -l snvs.bed -f $RNA_REF_FASTA $RNA_ALIGN_DIR/HBR.bam 2>/dev/null 1>HBR_bam-readcounts.txt
From this output you could parse the read counts for each base
cat UHR_bam-readcounts.txt | perl -ne '@data=split("\t", $_); @Adata=split(":", $data[5]); @Cdata=split(":", $data[6]); @Gdata=split(":", $data[7]); @Tdata=split(":", $data[8]); print "UHR Counts\t$data[0]\t$data[1]\tA: $Adata[1]\tC: $Cdata[1]\tT: $Tdata[1]\tG: $Gdata[1]\n";'
cat HBR_bam-readcounts.txt | perl -ne '@data=split("\t", $_); @Adata=split(":", $data[5]); @Cdata=split(":", $data[6]); @Gdata=split(":", $data[7]); @Tdata=split(":", $data[8]); print "HBR Counts\t$data[0]\t$data[1]\tA: $Adata[1]\tC: $Cdata[1]\tT: $Tdata[1]\tG: $Gdata[1]\n";'
Assignment: Index your bam files from Practical Exercise 6 and visualize in IGV.
- Hint: As before, it may be simplest to just index and visualize the combined/merged bam files HCC1395_normal.bam and HCC1395_tumor.bam.
- If this works, you should have two BAM files that can be loaded into IGV from the following location on your cloud instance:
- http://YOUR_DNS_NAME/workspace/rnaseq/practice/alignments/hisat2/
Questions
- Load your merged normal and tumor BAM files into IGV. Navigate to this location on chromosome 22: 'chr22:38,466,394-38,508,115'. What do you see here? How would you describe the direction of transcription for the two genes? Does the reported strand for the reads aligned to each of these genes appear to make sense? How do you modify IGV settings to see the strand clearly?
- How can we modify IGV to color reads by Read Group? How many read groups are there for each sample (tumor & normal)? What are your read group names for the tumor sample?
- What are the options for visualizing splicing or alternative splicing patterns in IGV? Navigate to this location on chromosome 22: 'chr22:40,363,200-40,367,500'. What splicing event do you see?
Solution: When you are ready you can check your approach against the Solutions
| Previous Section | This Section | Next Section |
|---|---|---|
| IGV | Alignment Visualization | Alignment QC |