This repository contains software required for participation in the NIPS 2018 Challenge: AI for prosthetics. See more details about the challenge here. See full documentation of our reinforcement learning environment here. In this document we will give very basic steps to get you set up for the challenge!
In this competition, you are tasked with developing a controller to enable a physiologically-based human model with a prosthetic leg to walk and run. You are provided with a human musculoskeletal model, a physics-based simulation environment where you can synthesize physically and physiologically accurate motion, and datasets of normal gait kinematics. You are scored based on how well your agent adapts to requested velocity vector changing in real time.

To model physics and biomechanics we use OpenSim - a biomechanical physics environment for musculoskeletal simulations.
We took into account comments from the last challenge and there are several changes:
- You can use experimental data (to greatly speed up learning process)
- We released the 3rd dimensions (the model can fall sideways)
- We added a prosthetic leg -- the goal is to solve a medical challenge on modeling how walking will change after getting a prosthesis. Your work can speed up design, prototying, or tuning prosthetics!
You haven't heard of NIPS 2017: Learning to run? Watch this video!

Anaconda is required to run our simulations. Anaconda will create a virtual environment with all the necessary libraries, to avoid conflicts with libraries in your operating system. You can get anaconda from here https://www.continuum.io/downloads. In the following instructions we assume that Anaconda is successfully installed.
We support Windows, Linux, and Mac OSX (all in 64-bit). To install our simulator, you first need to create a conda environment with the OpenSim package.
On Windows, open a command prompt and type:
conda create -n opensim-rl -c kidzik opensim python=3.6.1
activate opensim-rl
On Linux/OSX, run:
conda create -n opensim-rl -c kidzik opensim python=3.6.1
source activate opensim-rl
These commands will create a virtual environment on your computer with the necessary simulation libraries installed. Next, you need to install our python reinforcement learning environment. Type (on all platforms):
conda install -c conda-forge lapack git
pip install git+https://github.com/stanfordnmbl/osim-rl.git
If the command python -c "import opensim" runs smoothly, you are done! Otherwise, please refer to our FAQ section.
Note that source activate opensim-rl activates the anaconda virtual environment. You need to type it every time you open a new terminal.
To execute 200 iterations of the simulation enter the python interpreter and run the following:
from osim.env import ProstheticsEnv
env = ProstheticsEnv(visualize=True)
observation = env.reset()
for i in range(200):
observation, reward, done, info = env.step(env.action_space.sample())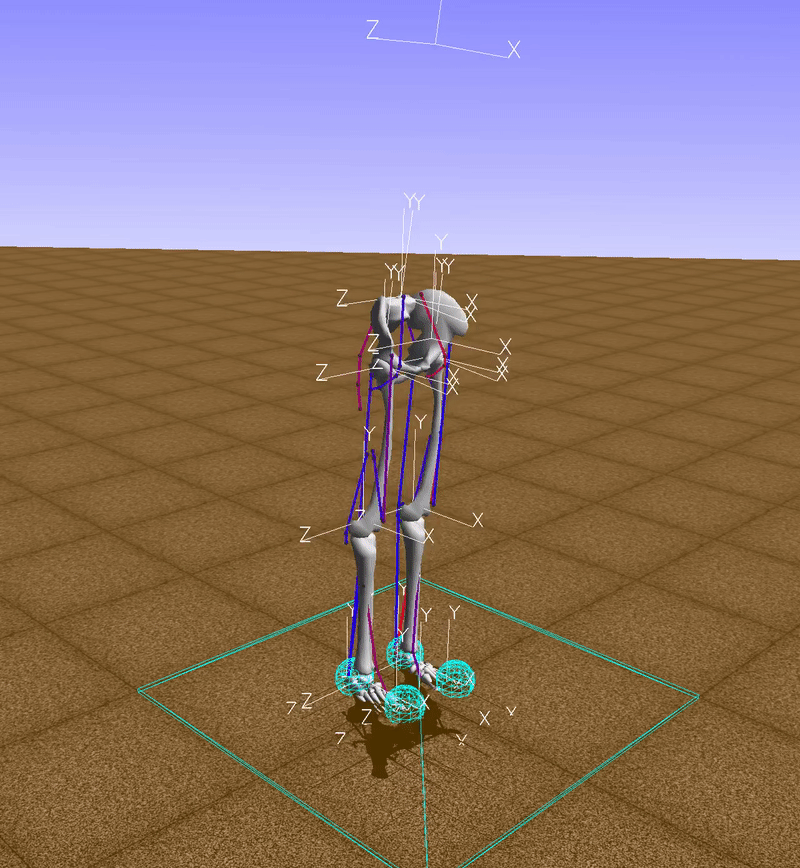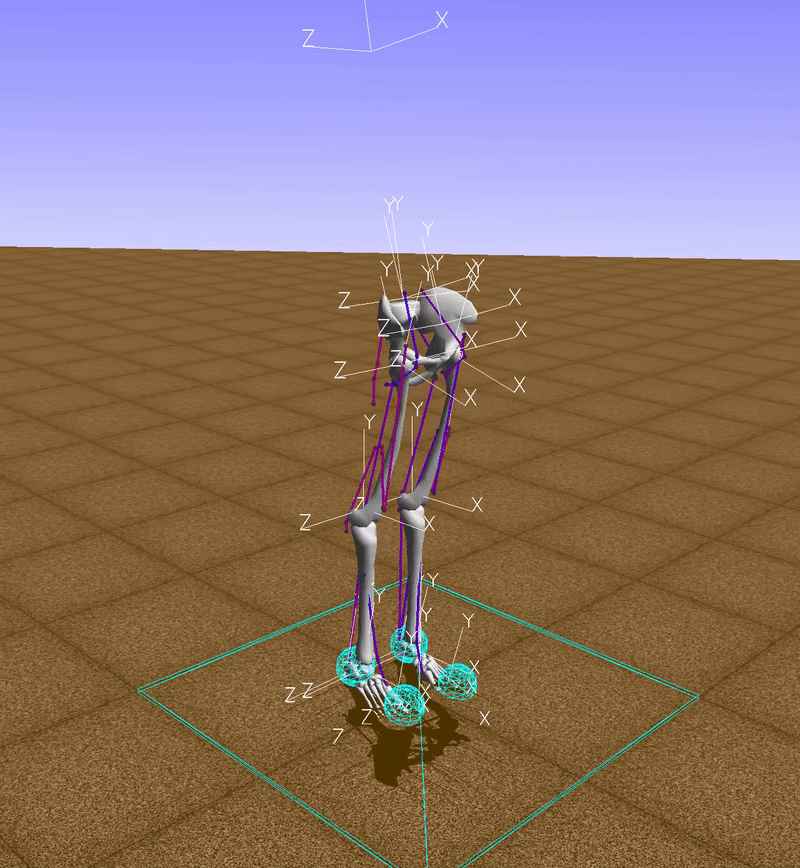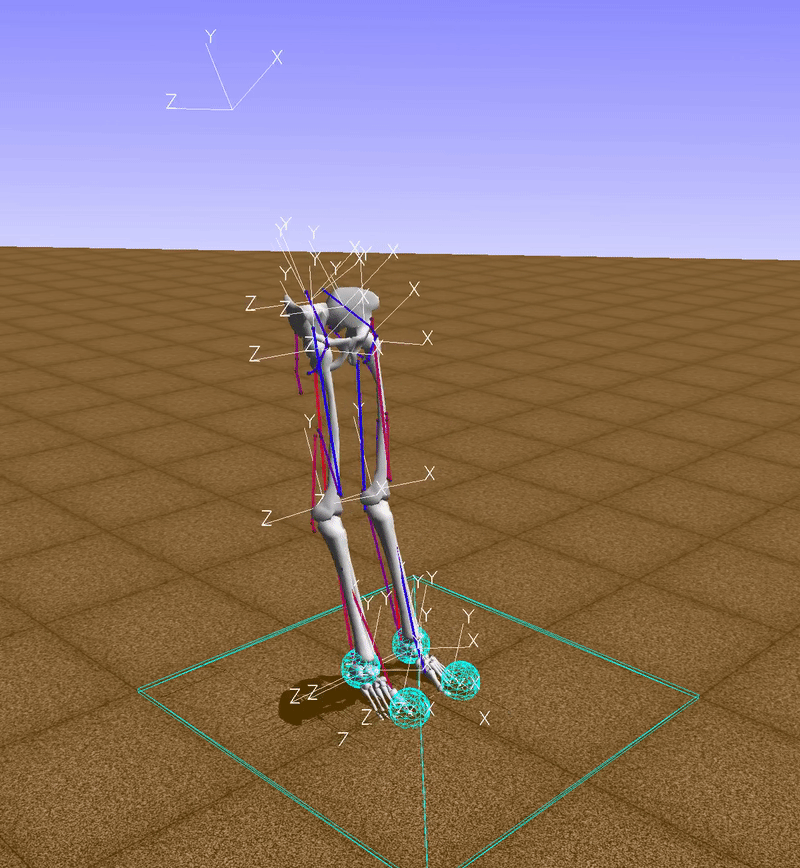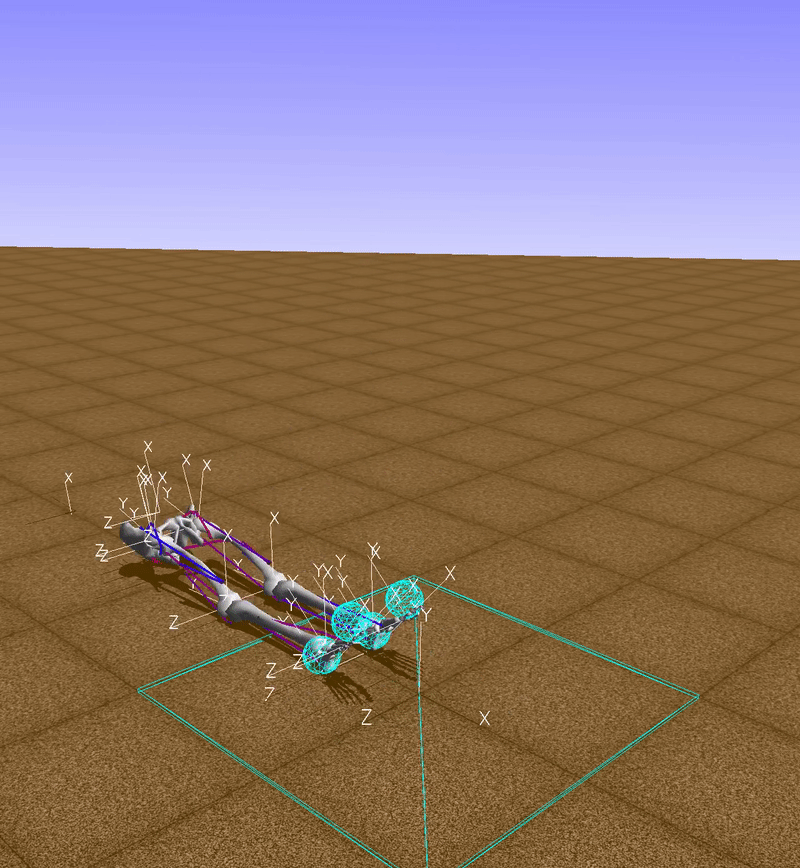
The function env.action_space.sample() returns a random vector for muscle activations, so, in this example, muscles are activated randomly (red indicates an active muscle and blue an inactive muscle). Clearly with this technique we won't go too far.
Your goal is to construct a controller, i.e. a function from the state space (current positions, velocities and accelerations of joints) to action space (muscle excitations), that will enable to model to travel as far as possible in a fixed amount of time. Suppose you trained a neural network mapping observations (the current state of the model) to actions (muscle excitations), i.e. you have a function action = my_controller(observation), then
# ...
total_reward = 0.0
for i in range(200):
# make a step given by the controller and record the state and the reward
observation, reward, done, info = env.step(my_controller(observation))
total_reward += reward
if done:
break
# Your reward is
print("Total reward %f" % total_reward)You can find details about the observation object here.
Assuming your controller is trained and is represented as a function my_controller(observation) returning an action you can submit it to crowdAI through interaction with an environment there:
import opensim as osim
from osim.http.client import Client
from osim.env import ProstheticsEnv
# Settings
remote_base = "http://grader.crowdai.org:1729"
crowdai_token = "[YOUR_CROWD_AI_TOKEN_HERE]"
client = Client(remote_base)
# Create environment
observation = client.env_create(crowdai_token)
# IMPLEMENTATION OF YOUR CONTROLLER
# my_controller = ... (for example the one trained in keras_rl)
while True:
[observation, reward, done, info] = client.env_step(my_controller(observation), True)
print(observation)
if done:
observation = client.env_reset()
if not observation:
break
client.submit()In the place of [YOUR_CROWD_AI_TOKEN_HERE] put your token from the profile page from crowdai.org website.
Your task is to build a function f which takes the current state observation (a dictionary describing the current state) and returns the muscle excitations action (19-dimensional vector) maximizing the total reward. The trial ends either if the pelvis of the model falls below 0.6 meters or if you reach 300 iterations (corresponding to 10 seconds in the virtual environment).
The objective is to run at a constant speed of 3 meters per second. The total reward is 9 * s - p * p where s is the number of steps before reaching one of the stop criteria and p is the absolute difference between horizonal velocity and 3.
In the second round the task is also to follow a requested velocity vector. However, in this round the vector will change in time and it will be a random process. We will provide the distribution of this process in mid-July.
You can test your model on your local machine. For submission, you will need to interact with the remote environment: crowdAI sends you the current observation and you need to send back the action you take in the given state.
Read more about evaluation here.
In order to avoid overfitting to the training environment, the top participants will be asked to resubmit their solutions in the second round of the challenge. The final ranking will be based on the results from the second round.
Additional rules:
- Organizers reserve the right to modify challenge rules as required.
Read more in the official documentation
- Osim-rl interface
- How to train a model?
- More on training models
- Experimental data
- Physics underlying the model
- Frequently Asked Questions
- Citing and credits
- Understanding the Challenge - Great materials from @seungjaeryanlee on how to start