{kind=link}
{kind=link}
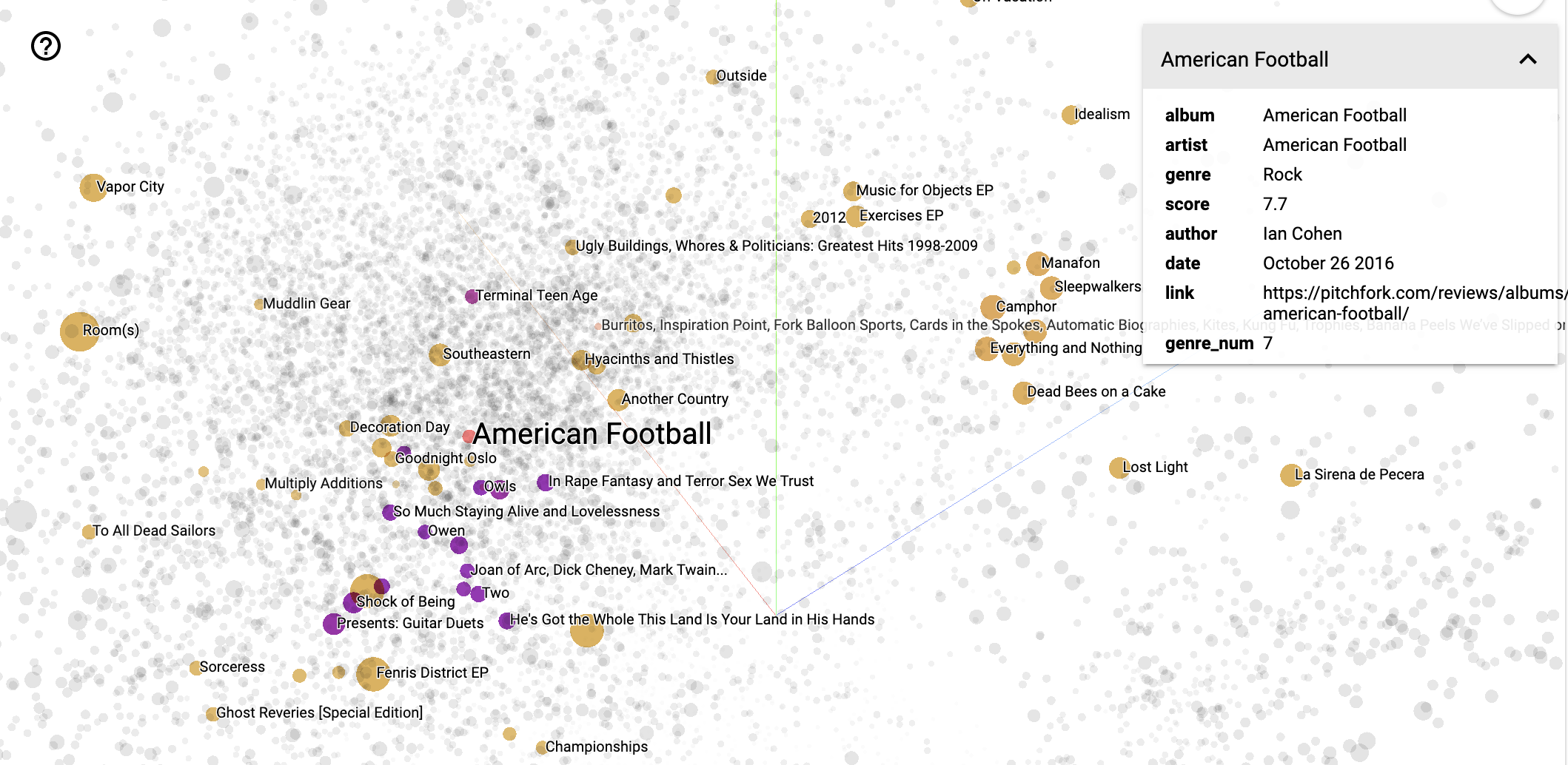
[demo] (built upon Tensorflow's Standalone Embedding Projector)
[download] [Reddit discussion]
This dataset lists 20873 pitchfork review articles from Jan. 5, 1999 to Jan. 11, 2019, covering entries like genre, date, score, review content, etc. Each review article corresponds to one album.
We first create a weighted graph where each node represents an album. We compute the TF-IDF value between every two reviews and get a pairwise similarity matrix of all reviews(albums). Note that we do not use state-of-the-art text representation models like BERT as such representation reflects little information on the entities mentioned (which can be crucial for clustering related albums). Based on the intuition that an album's review is likely to mention similar artists/albums, we use TF-IDF to capture the keywords that may matter for describing the similarity of two albums. We set a threshold to filter out all edges below the bar and a sparser but more informative weighted graph is obtained.
We apply weighted node2vec on the obtained graph using the default hyperparameters.