A project focus on recommendation of CHV terms from social media, based on dataset UMLS
and platform Apcache Spark.
Conceptual idea is shwon in flowing figure.
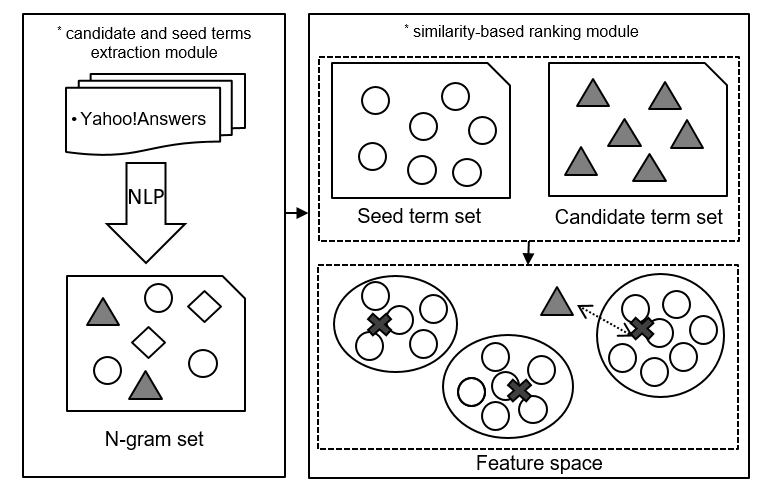
- We first extract n-gram from Yahoo!Answers textual dataset (of course, you can use any other textual dataset);
- Second, identify the CHV terms using fuzzy matching method with UMLS database. We also call these terms as seed terms. The other terms which do not match with any CHV term is considered as candidate terms.
- Third, we use K-means algorithm to train a model from the identified CHV terms, and we get K centers for the model..
- Fourth, we calculate the distance between a candidate term to all the K centers, and we choose the shortest distance as the score to measure whether we should recommend a term as a CHV term. The smaller the score is, the more likely a candidate term should considered as a CHV term.
The workflow of the project is shown in following figure.

For more detail of the methodology, please read our paper.
- Download this project use:
git clone https://github.com/henryhezhe2003/simiTerm.git. I recommend to use an IDE such as IDEA. It is a maven project, so it should be easy to build it. Add an environment variableCTM_ROOT_PATH, which indicates the root directory of the project. The tool will find the configuration file and resource file in the project directory. - Add the dependency package int
libsdirectory to the project, see file ( docs/dependency-package.jpg), and set the environment variableCTM_ROOT_PATHto be the root directory of the project. The program will look for configuration file and other resource files (e.g. stopwords.txt) based on this root directory. - Prepare the UMLS data for test. (This step may take lots of time) You can follow the Sujit's post Understanding UMLS or the documentation of UMLS. At the end, you will import the UMLS data into Mysql.
- Build index database for fuzzy matching.
Run the test function: com.votors.umls.UmlsTagger2Test.testBuildIndex2db, or
run
java -cp Clinical-Text-Mining-0.0.1-SNAPSHOT-jar-with-dependencies.jar:/data/ra/stanford-corenlp-3.6.0-models.jar com.votors.umls.BuildTargetTermin terminal. and it will create a index table from UMLS database - Good luck and enjoy it!
you can run the class com.votors.ml.Clustering in the IDEA directly. You probably need to set the maximum memory larger: -Xmx5000m
or submit it to Spark cluster:
spark-submit --master spark://127.0.0.1:7077 --deploy-mode cluster --num-executors 9 --driver-memory 10g --executor-memory 2048m
--executor-cores 1 --class com.votors.ml.Clustering --conf 'spark.executor.extraJavaOptions=-DCTM_ROOT_PATH=/data/ra/Clinical-Text-Mining
-cp /data/ra/stanford-corenlp-3.6.0-models.jar:/usr/bin/spark/spark-run/conf/:/usr/bin/spark/spark-run/lib/spark-assembly-1.6.0-hadoop2.6.0.jar:/usr/bin/spark/spark-run/lib/datanucleus-core-3.2.10.jar:/usr/bin/spark/spark-run/lib/datanucleus-rdbms-3.2.9.jar:/usr/bin/spark/spark-run/lib/datanucleus-api-jdo-3.2.6.jar'
--driver-java-options=-DCTM_ROOT_PATH=/data/ra/Clinical-Text-Mining
--files /data/ra/Clinical-Text-Mining/conf/default.properties,/data/ra/Clinical-Text-Mining/conf/current.properties
/data/ra/Clinical-Text-Mining/target/Clinical-Text-Mining-0.0.1-SNAPSHOT-jar-with-dependencies.jar > result_yahoo_rank.txt 2>spark.log
- UMLS data
- StanfordNLP
Anyone interested in the project is welcome!