Tên đề tài : Tìm hiểu Delta-lake và mô hình kết nối với AWS
- Tìm hiểu Delta-lake và mô hình kết nối với AWS
- https://delta.io/
- Nguyễn Hiếu Đan - 19110345
- Dương Đức Thắng - 19110461
- Ninh Phạm Trung Thành - 19110456
Data Lake (hay Hồ dữ liệu) là một kho lưu trữ tập trung được thiết kế để lưu trữ, xử lý và bảo mật một lượng lớn dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc. Nó có thể lưu trữ dữ liệu ở định dạng gốc và xử lý mọi loại dữ liệu khác nhau, bỏ qua các giới hạn về kích thước. Nó cung cấp số lượng dữ liệu cao để tăng hiệu suất phân tích và tích hợp gốc.

Hadoop là một Apache framework mã nguồn mở cho phép phát triển các ứng dụng phân tán (distributed processing) để lưu trữ và quản lý các tập dữ liệu lớn. Hadoop hiện thực mô hình MapReduce, mô hình mà ứng dụng sẽ được chia nhỏ ra thành nhiều phân đoạn khác nhau được chạy song song trên nhiều node khác nhau. Hadoop được viết bằng Java tuy nhiên vẫn hỗ trợ C++, Python, Perl bằng cơ chế streaming. Hadoop giải quyết:
- Xử lý và làm việc khối lượng dữ liệu khổng lồ tính bằng Petabyte.
- Xử lý trong môi trường phân tán, dữ liệu lưu trữ ở nhiều phần cứng khác nhau, yêu cầu xử lý đồng bộ
- Các lỗi xuất hiện thường xuyên.
- Băng thông giữa các phần cứng vật lý chứa dữ liệu phân tán có giới hạ
Apache Spark là một framework mã nguồn mở tính toán cụm, được phát triển sơ khởi vào năm 2009 bởi AMPLab. Sau này, Spark đã được trao cho Apache Software Foundation vào năm 2013 và được phát triển cho đến nay.
Tốc độ xử lý của Spark có được do việc tính toán được thực hiện cùng lúc trên nhiều máy khác nhau. Đồng thời việc tính toán được thực hiện ở bộ nhớ trong (in-memories) hay thực hiện hoàn toàn trên RAM.
Spark cho phép xử lý dữ liệu theo thời gian thực, vừa nhận dữ liệu từ các nguồn khác nhau đồng thời thực hiện ngay việc xử lý trên dữ liệu vừa nhận được ( Spark Streaming).
Spark không có hệ thống file của riêng mình, nó sử dụng hệ thống file khác như: HDFS, Cassandra, S3,…. Spark hỗ trợ nhiều kiểu định dạng file khác nhau (text, csv, json…) đồng thời nó hoàn toàn không phụ thuộc vào bất cứ một hệ thống file nào.
Delta lake là một framework lưu trữ mã nguồn mở được ra mắt vào năm 2019 cho phép xây dựng kiến trúc datalake với các công cụ tính toán như Spark, PrestoDB, Flink, Trino, Hive và các API sử dụng Scala, Java, Rust, Ruby, and Python
- Delta Lake là một lớp lưu trữ nguồn mở đảm bảo độ tin cậy cho các hồ dữ liệu.
- Nó được thiết kế đặc biệt để hoạt động với Databricks File System (DBFS) và Apache Spark.
- Nó cung cấp khả năng xử lý dữ liệu hàng loạt và phát trực tuyến hợp nhất, giao dịch ACID và xử lý siêu dữ liệu có thể mở rộng.
- Nó lưu trữ dữ liệu của bạn dưới dạng tệp Apache Parquet trong DBFS và duy trì nhật ký giao dịch theo dõi chính xác các thay đổi đối với bảng.
- Nó làm cho dữ liệu sẵn sàng để phân tích.

- Hỗ trợ ACID transaction.
- Tận dụng sức mạnh xử lý phân tán của Spark để xử lý tất cả siêu dữ liệu cho các bảng quy mô hàng petabyte với hàng tỷ file một cách dễ dàng.
- Time travel - Dễ dàng truy cập và hoàn lại những phiên bản trước của dữ liệu.
- Định dạng mở lưu trữ dưới Parquet file.
- Hợp nhất Batch & Streaming, Source & Sink.
- Dễ dàng thay đổi lược đồ hiện tại của bảng để phù hợp với dữ liệu.
- Hiệu suất nhanh với Apache Spark.
- Hỗ trợ MERGE, UPDATE, DELETE và phát trực tuyến UPSERTS.
Delta Lake thuộc Transaction Layer nằm trên đỉnh storage layer của data lake để nhận dữ liệu đáng tin cậy trong các hồ dữ liệu đám mây như Amazon S3 và ADLS Gen2 .
Delta Lake đảm bảo dữ liệu nhất quán, đáng tin cậy với các giao dịch ACID, lập phiên bản dữ liệu tích hợp và kiểm soát để đọc và ghi đồng thời.
Nó còn cho phép tái tạo báo cáo dễ dàng và đáng tin cậy.
Kiến trúc Delta Lake là một cải tiến lớn so với kiến trúc Lambda truyền thống.
Ở mỗi giai đoạn, Delta-lake dữ liệu của mình thông qua một quy trình được kết nối cho phép chúng kết hợp luồng công việc theo lô(Batch workflow) và luồng(Stream) thông qua kho lưu trữ tệp được chia sẻ với các giao dịch tuân thủ ACID.
Delta lake sắp xếp dữ liệu của mình thành các lớp hoặc thư mục được xác định là Bronze, Silver và Gold như sau:
- Bảng Bronze có dữ liệu thô được nhập từ nhiều nguồn khác nhau (dữ liệu RDBMS, tệp JSON, dữ liệu IoT, v.v.).
- Các bảng Silver sẽ cung cấp một cái nhìn tinh tế hơn về dữ liệu của chúng tôi. Delta lake kết hợp các trường từ nhiều bảng Bronze khác nhau để cải thiện hồ sơ phát trực tuyến(streaming records) hoặc cập nhật trạng thái tài khoản dựa trên hoạt động gần đây.
- Bảng Gold cung cấp tổng hợp các bản báo cáo ở business-level thường được sử dụng để lập bảng điều khiển và báo cáo. Điều này sẽ bao gồm các tổng hợp như doanh số hàng tuần trên mỗi cửa hàng, người dùng trang web hoạt động hàng ngày hoặc tổng doanh thu mỗi quý của bộ phận.
Kết quả cuối cùng là thông tin chi tiết có thể hành động, bảng điều khiển và báo cáo về các số liệu kinh doanh.
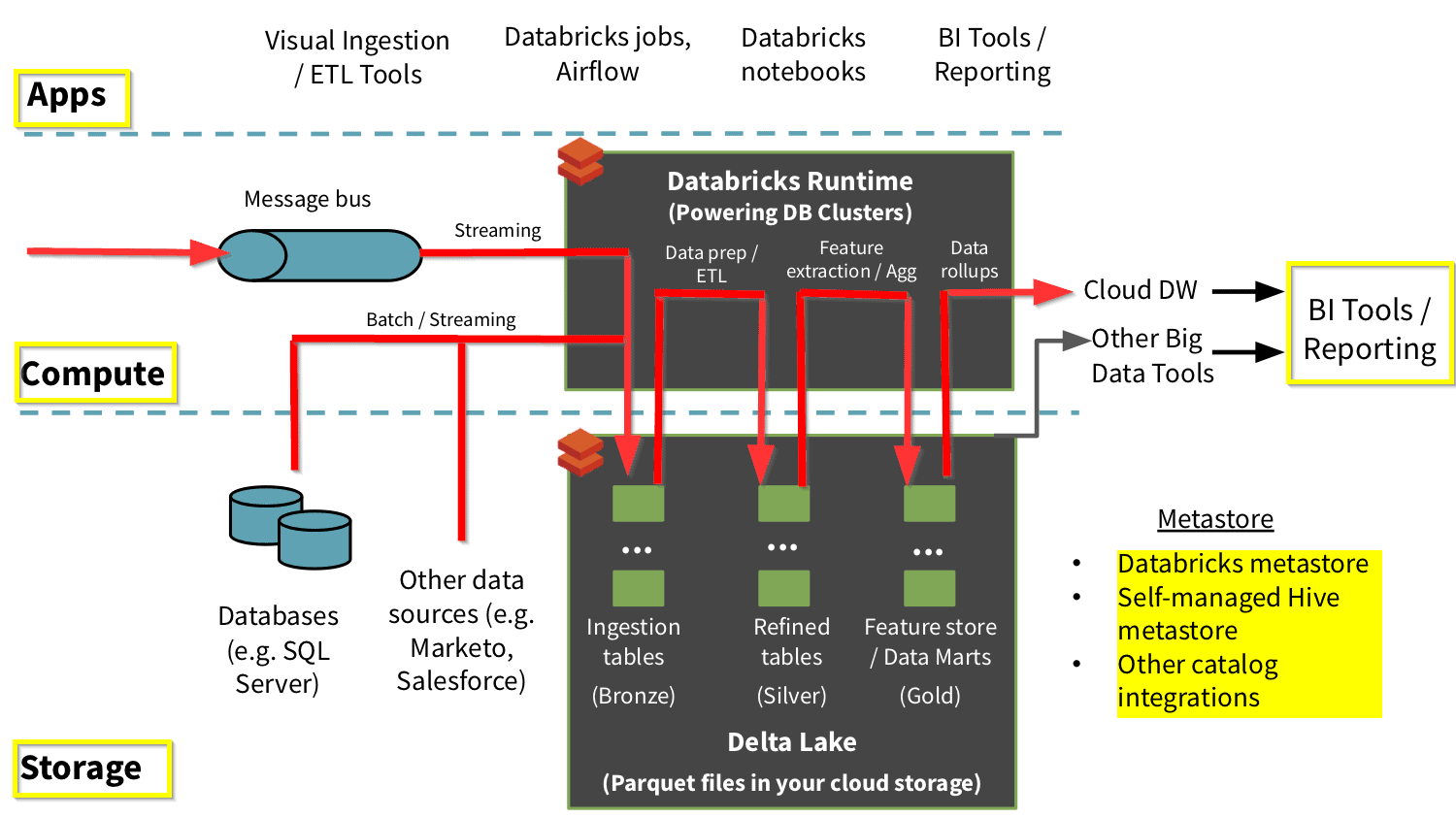
Để nhờ vào delta lake kết hợp với các dịch vụ AWS mà chúng sẽ sẽ xây dựng được 1 hệ thống lakehouse có đầy đủ tính năng hoàn chỉnh.

- S3 là nơi lưu trữ chính của các Batch data
- Kinesis là nơi xử lý tiếp nhận dữ liệu thời gian thực theo luồng từ các dịch vụ khác của aws hoặc ngoài aws.
- Delta lake được deploy trên các nền tảng của AWS có thể kiểm soát đăng nhập bảo mật bằng IAM và Role
- Tiếp là Delta lake sẽ kết hợp cũng AWS glue để xử lý dữ liệu
- Ridshift và Athena cho phép truy vấn sắp xếp lại dữ liệu để đưa ra QuickSight thành những bản báo cáo và gửi đến người dùng cuối
- Cài đặt được spark và delta-lake trên instance EC2 kết nối với S3 và thực hiện các câu lệnh truy vấn, xử lý dữ liệu theo delta-lake framework bằng cách ssh vào EC2 instant
- Cấu hình EMR cho phép sử dụng delta-lake framework và thực hiện truy vấn dữ khai thác dữ liệu qua EMR notebook.
 Tạo 1 instance EC2 như bài thực hành lab đã học với cấu hình tối thiểu 2 vCPUs. Có thể xài bất cứ hệ điều hành gì ở đây em chọn ubuntu vì tính quen thuộc và ổn định.
Tạo 1 instance EC2 như bài thực hành lab đã học với cấu hình tối thiểu 2 vCPUs. Có thể xài bất cứ hệ điều hành gì ở đây em chọn ubuntu vì tính quen thuộc và ổn định.


Tạo 1 bucket S3 để lưu trữ dữ liệu. Lưu ý: Ở đây do tài khoản lab leaner không hỗ trợ IAM nên em public nó luôn để sử dụng.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1594969687722",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::delta-lake-ute",
"arn:aws:s3:::delta-lake-ute/*"
]
}
]
} Kết nối trực tiếp đến EC2 instance để dụng.
Có thể thông qua SSH để truy cập vào vì nhanh và đơn giản em truy cập trực tiếp ở website aws
Kết nối trực tiếp đến EC2 instance để dụng.
Có thể thông qua SSH để truy cập vào vì nhanh và đơn giản em truy cập trực tiếp ở website aws
 Sử dụng lệnh để cài đặt java và python.
Yêu cầu cài đặt Python > 3.8 và jdk > 11
Sau đó cài pip3 để cài đặt package cần sử dụng
Sử dụng lệnh để cài đặt java và python.
Yêu cầu cài đặt Python > 3.8 và jdk > 11
Sau đó cài pip3 để cài đặt package cần sử dụng
python3 –verion
java –version
apt-get update
apt install openjdk-11-jre-headless
sudo apt install python3-pip
pip install pyspark==3.2.2
from pyspark.sql import SparkSession
spark_jars_packages = "com.amazonaws:aws-java-sdk:1.12.246,org.apache.hadoop:hadoop-aws:3.2.2,io.delta:delta-core_2.12:1.2.1,"
spark = (
SparkSession.builder.master("local[*]")
.appName("PySparkLocal") # tên app
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") # phần extension sql sẽ là deltasparksession
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") #set catalog là thư viện delta
.config("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") # sử dụng s3a hỗ trợ lên tới tệp 5TB
.config("spark.hadoop.fs.AbstractFileSystem.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") # tương tự
.config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.S3SingleDriverLogStore") # lưu log tại S3
.config("spark.hadoop.fs.s3a.connection.timeout", "3600000") #time out
.config("spark.hadoop.fs.s3a.connection.maximum", "1000") # connection tối đa
.config("spark.hadoop.fs.s3a.threads.max", "1000") # số thread tối đa
.config("spark.jars.packages", spark_jars_packages) # các jars package được khai báo wor trên
.config("spark.sql.sources.partitionOverwriteMode", "dynamic") # Ghi đè các phân vùng
.config("spark.databricks.delta.schema.autoMerge.enabled", "true") # tự động merge
.config("spark.hadoop.fs.s3a.endpoint", "s3.us-east-1.amazonaws.com") # đầu cuối s3
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider") #cung cấp credentials
.getOrCreate()
)Dòng đầu tiên là import thử viện
Dòng thứ 2 khải báo các thư viện core để sử dụng
Dòng thứ 3 đến cuối là confuration cấu hình và build SparkSession

 Import dữ liệu từ: https://stats.govt.nz/large-datasets/csv-files-for-download/
Import dữ liệu từ: https://stats.govt.nz/large-datasets/csv-files-for-download/
 Đọc file csv với header bằng lệnh:
Đọc file csv với header bằng lệnh:
df = spark.read.option("recursiveFileLookup", "true").option("header","true").csv("s3://delta-lake-ute/machine-readable-business-employment-data-mar-2022-quarter.csv")Sau đó thực hiện tạo một view tạm và thực hiện câu truy vấn:
df.createOrReplaceTempView("employment_tbl")
spark.sql("select Series_title_2,count(*) as count from employment_tbl group by Series_title_2 order by 2 desc").show(truncate=False) mục đích của câu lệnh này là lấy ra các tile và đếm số lượng của nhân viên trong title đó từ file csv
 Sử dụng các câu lệnh sau bằng spark và delta lake:
Sử dụng các câu lệnh sau bằng spark và delta lake:
Tạo data frame
df_groupby = spark.sql("select Series_title_2,count(*) as count from employment_tbl group by Series_title_2 order by 2 desc")Lưu data frame dưới dạng delta format
df_groupby.write.format("delta").save("s3://delta-lake-ute/sample_data/")Đọc data delta format
df = spark.read.format("delta").load("s3://delta-lake-ute/sample_data/")Show ra data đã đọc
df.show()Kiểm tra S3 ta thấy file có phần mở rộng là panquet đó là dạng file của delta làm việc Dạng file này sẽ cho tốc độ truy vấn nhanh gấp nhiều lần csv

Ute-delta-lake: dùng để lưu dữ liệu khi làm việc
Ute-erm-boostrap: dùng để lưu file cho việc bootstrap của emr service
Tạo 1 file với tên là deltajarinstall.sh với nội dung:
#!/bin/bash
sudo curl -O --output-dir /usr/lib/spark/jars/ https://repo1.maven.org/maven2/io/delta/delta-core_2.12/2.0.0/delta-core_2.12-2.0.0.jar
sudo curl -O --output-dir /usr/lib/spark/jars/ https://repo1.maven.org/maven2/io/delta/delta-storage/2.0.0/delta-storage-2.0.0.jar
sudo python3 -m pip install delta-spark==2.0.0
Ở dịch vụ cloud shell nhập lệnh sau để tạo emr install với pyspark core là delta lake:
aws emr create-cluster \
--name "emr-delta-lake-blog" \
--release-label emr-6.7.0 \
--applications Name=Hadoop Name=Hive Name=Livy Name=Spark Name=JupyterEnterpriseGateway \
--instance-type m5.xlarge \
--instance-count 1 \
--ec2-attributes SubnetId='subnet-0017deaed524d4e72' \
--use-default-roles \
--bootstrap-actions Path="s3://ute-erm-boostrap/deltajarinstall.sh"



Chọn cấu hình như hình.




Mở notebook và chọn PySpark Kernel

Cài đặt chạy apache spark với delta core
Sau đó import thư viện dùng để chạy các lệnh truy vấn delta
%%configure -f
{
"conf": {
"spark.sql.extensions": "io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog": "org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}
from delta.tables import *
from pyspark.sql.functions import *
Sử dụng bucket được public của aws(Amazon Product Reviews Dataset) để đọc và viết data delta
https://us-east-1.console.aws.amazon.com/s3/home?region=us-east-1&bucket=amazon-reviews-pds

Set deltaPath là vị trí s3 bucket được tạo ởbước 1
Kiểm tra spark đọc file banquet từ public bucket:
deltaPath = "s3://ute-delta-lake/delta-amazon-reviews-pds/"
df_parquet = spark.read.parquet("s3://amazon-reviews-pds/parquet/product_category=Gift_Card/*.parquet"
df_parquet.printSchema()
Tiến hành lưu các file theo định dạng delta xuống bucket S3 đã tạo ở bước 1
Kiểm tra thấy lưu thành công nghĩa là việc cài đặt đã hoàn tất thành công.
df_parquet.write.mode("overwrite").format("delta").partitionBy("year").save(deltaPath)
Đọc và show lên lại file vừa lưu:
df_delta = spark.read.format("delta").load(deltaPath)
df_delta.show()
Sử dụng lại kho dữ liệu của amazone customer review dataset được quyền sủ dụng cho mục đích học thuật.
https://us-east-1.console.aws.amazon.com/s3/home?region=us-east-1&bucket=amazon-reviews-pds

Sau đó chúng ta đọc toàn bộ file .parquet từ danh mục Gift_Card của dữ liệu aws public và lưu vào df_parquet
Sau đó chúng ta sử dụng SQL để lưu về bucket đã chuẩn bị từ trước của chúng ta theo từng năm 1
deltaPath = "s3://ute-delta-lake/delta-amazon-reviews-pds/"
df_parquet = spark.read.parquet("s3://amazon-reviews-pds/parquet/product_category=Gift_Card/*.parquet")
df_parquet.printSchema()
df_parquet.write.mode("overwrite").format("delta").partitionBy("year").save(deltaPath)
spark.conf.set('table.location', deltaPath)


Dùng spark để đọc dữ liệu lên Dùng lệnh show để tiến hành show ra dữ liệu đã đọc
df_delta = spark.read.format("delta").load(deltaPath)
df_delta.show()
%%sql
SELECT * FROM delta.`s3://ute-delta-lake/delta-amazon-reviews-pds/` LIMIT 10
df_delta.createOrReplaceTempView("aws_product_review")
spark.sql("select marketplace,customer_id,review_date from aws_product_review LIMIT 30").show(30)
Chuyển US sang USA
deltaTable = DeltaTable.forPath(spark, deltaPath) #khai báo 1 datatable
deltaTable.update("marketplace = 'US'",{ "marketplace":"'USA'"}) # Thay đổi toàn bộ marketplace US thành USA
#hoặc
%%sql
update delta.`s3://ute-delta-lake/delta-amazon-reviews-pds/`
set marketplace = 'USA' where marketplace = 'US'
df_delta.filter("verified_purchase = 'N'").show() #Xem dữ liệu trước khi xóa
deltaTable.delete("verified_purchase = 'N'") #Xóa dữ liệu
df_delta.filter("verified_purchase = 'N'").show() #Show lại sau khi xóa
Lưu ý rằng phương thức xóa chỉ loại bỏ dữ liệu khỏi phiên bản mới nhất của bảng. Những hồ sơ này vẫn có mặt trong các snap shot cũ hơn của dữ liệu.
prev_version = deltaTable.history().selectExpr('max(version)').collect()[0][0] - 1
prev_version_data = spark.read.format('delta').option('versionAsOf', prev_version).load(deltaPath)
prev_version_data.filter("verified_purchase = 'N'").show(10)
deltaTable.history(100).select("version", "timestamp", "operation", "operationParameters").show(truncate=False) # show ra lịch sử chỉnh sửa
df_time_travel = spark.read.format("delta").option("versionAsOf", 0).load(deltaPath) # đọc lại verion 0 ở lịch sử chỉnh sửa và show ra ta có thể thấy là marketplace vẫn là US trước khi sửa
df_time_travel.show()
Tạo ra 1 list gồm 2 item để thực hiện upsert update XODE và insert XOA1 vì nó chưa tồn tại
Sau đó tạo 1 frame chứa data để upsert
spark.sql("select * from aws_product_review where review_id in ('R315TR7JY5XODE', 'R315TR7JY5XOA1')").show() # show kết quả trước khi upsert
data_upsert = [ {"marketplace":'US',"customer_id":'38602100', "review_id":'R315TR7JY5XODE',"product_id":'B00CHSWG6O',"product_parent":'336289302',"product_title" :'Amazon eGift Card', "star_rating":'5', "helpful_votes":'2',"total_votes":'0',"vine":'N',"verified_purchase":'Y',"review_headline":'GREAT',"review_body":'GOOD PRODUCT',"review_date":'2014-04-11',"year":'2014'},
{"marketplace":'US',"customer_id":'38602103', "review_id":'R315TR7JY5XOA1',"product_id":"B007V6EVY2","product_parent":'910961751',"product_title" :'Amazon eGift Card', "star_rating":'5', "helpful_votes":'2',"total_votes":'0',"vine":'N',"verified_purchase":'Y',"review_headline":'AWESOME',"review_body":'GREAT PRODUCT',"review_date":'2014-04-11',"year":'2014'}
]
df_data_upsert = spark.createDataFrame(data_upsert)
df_data_upsert.show()
(deltaTable
.alias('t')
.merge(df_data_upsert.alias('u'), 't.review_id = u.review_id')
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute())
spark.sql("select * from aws_product_review where review_id in ('R315TR7JY5XODE', 'R315TR7JY5XOA1')").show() # show sau khi khi upserthttps://towardsdatascience.com/getting-started-with-delta-lake-spark-in-aws-the-easy-way-9215f2970c58 https://aws.amazon.com/vi/blogs/big-data/build-a-high-performance-transactional-data-lake-using-open-source-delta-lake-on-amazon-emr/ https://garystafford.medium.com/building-a-simple-data-lake-on-aws-df21ca092e32