{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It is development stage would be updated soon by the end of march
In this we have converted PDF tables to xml and json files and provided them a gui Interface
In this project we will be analysing tables by using computer vision for the detection of the tables in Images/PDF for the maximum precision and after detection of the words then would be converting into different forms for the analysis by the end users
- Whole process should be fully automated
- Process should be economical for the maximising use-case
- OpenCV : for analysis of text in images and pdf
- For reducing the hindrance of the background color
- For converting the color images into grayscale this would help us to reduce the loss in images while converting
- Camelot
- For conversion of the images into dataframes that would help us to convert into different forms and help us to perform calculations on data
- pdf2Text
- For the analysis of two tables on the same page and for the analysis of the loss in data produced
& for the analysis part in different forms and formats we would be using 4. Pandas
- For calculations on data like pivot table and analysis of data in different streams
- Pymysql
- For sending the data into database so that we could use sql queries in bulk data for better analysis increase its usability.
Tkinter : for the making of the project interface
images/pdf in 99.2% precision in which there would no loss of data would take place As we are using computer vision for the analysis our second focus is to use minimum amount of computation and targeting maximum output to make our product usable economically
With our method users won’t be requiring any pre-trained dataset.
After our theoretical analysis we found that our methodology would be taking 1.2s for each analysis of tables in pdf and then we would be converting in different formats
Best thing of our methodology is that it can be combined with any different number of forms whether to combine in web-interface or graphical-user-interface.
To make this process simple we have provided an desktop application interface using tkinter
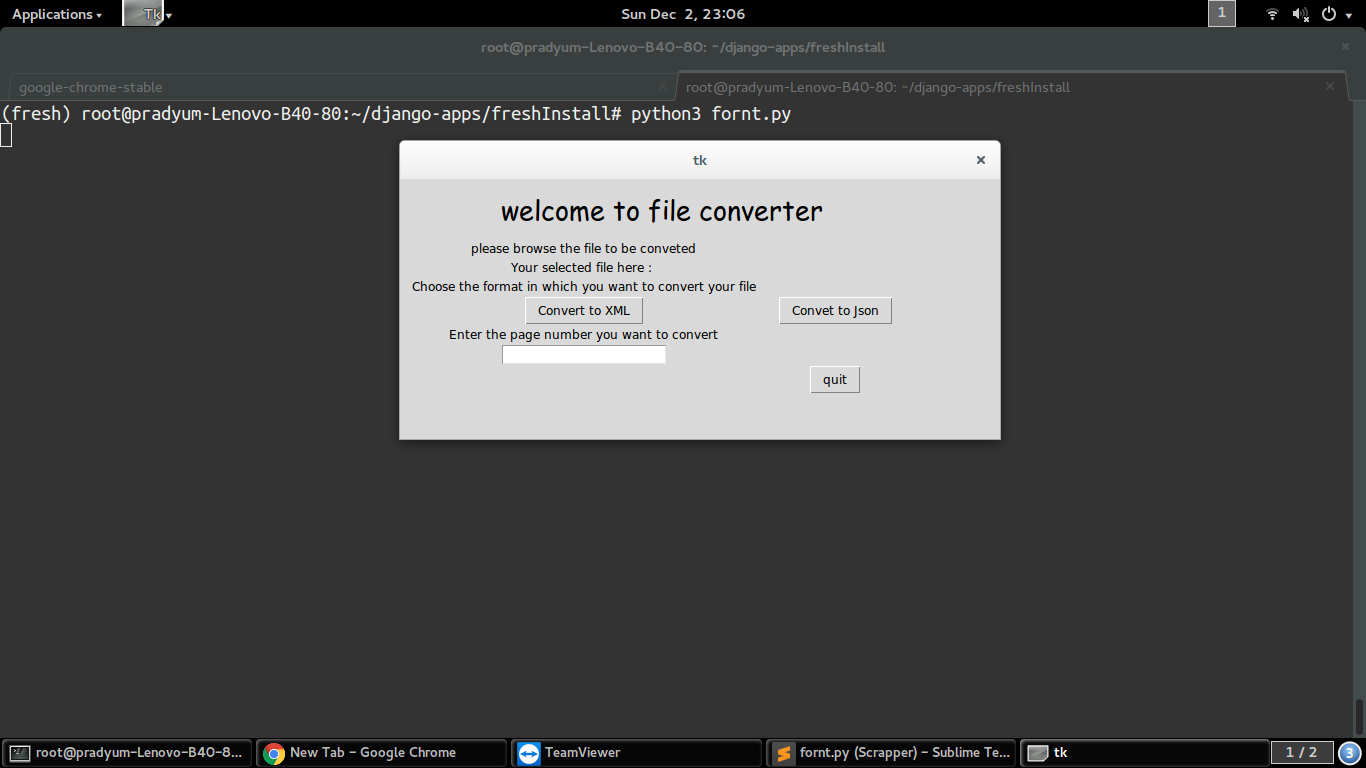




- This project does not work for streaming tables in PDFs
- For Images -- We would be converting images into pdf using FPDF for the final Challenge but due to some technical glitch in GUI we did not introduced feature in this version
Install Python3.6 from this link even if you have different python installed on your system this link would work
http://ubuntuhandbook.org/index.php/2017/07/install-python-3-6-1-in-ubuntu-16-04-lts/
$ wget https://bootstrap.pypa.io/get-pip.py
$ sudo python3 get-pip.py
$ sudo pip install virtualenv
$ virtualenv venv
$ . venv/bin/activate # for activation of the virtualenv
Now you will find (venv) on the next line
to deactivate this use do it after all our work is complete
$deactivate
we would be installing pandas from source
sudo pip install https://files.pythonhosted.org/packages/e1/d8/feeb346d41f181e83fba45224ab14a8d8af019b48af742e047f3845d8cff/pandas-0.23.4-cp36-cp36m-manylinux1_x86_64.whl
if you require different version of pandas for new python release please refer this link
https://pypi.org/project/pandas/#files
this link would work for ubuntu14 also so its fine if you have earlier version of ubuntu
https://www.pyimagesearch.com/2018/05/28/ubuntu-18-04-how-to-install-opencv/
This installation would only work if python3.6 & Pandas 0.23.4 & openCV is installed CORRECTLY else try again
$ sudo apt install python-tk ghostscript
Run the following to check the ghostscript version.
$ gs -version
sudo pip install camelot-py
https://camelot-py.readthedocs.io/en/latest/user/install.html#install
https://media.readthedocs.org/pdf/camelot-py/latest/camelot-py.pdf
pip install pymysql
pip install argparse
pip install
import pymysql
import argparse
import camelot
parser = argparse.ArgumentParser(description='PDF Page to SQL')
parser.add_argument('-i','--input',help="PDF file name",required=True)
parser.add_argument('-p','--page',help="Enter page num",required=True)
args = parser.parse_args()
#show Values
print("input file name {}".format(args.input))
print("Page num is {}".format(args.page))
tables = camelot.read_pdf(args.input,pages=args.page)
tables[0].to_csv('foo.csv')
tables.export('foo.csv',f='csv')
data = tables[0].df
# print(data)
user = 'root'
passw = 'root'
host = 'localhost'
database = 'data_2'
conn = pymysql.connect(host=host, user=user, passwd = passw, unix_socket="/var/run/mysqld/mysqld.sock")
conn.cursor().execute("CREATE DATABASE IF NOT EXISTS {0}".format(database))
conn = pymysql.connect(host=host,
user=user,
passwd = passw,
db = database,
charset = 'utf8')
data.to_sql(name = database, con = conn, if_exists = 'replace')
python3 scriptName -i pdfName.pdf -p 61
here input file stands for -i input file pdfName and -p stands for page number
After the script is completed you will find a database named data_2 in which table would be found
Change these details according to you user = 'root' passw = 'root' host = 'localhost' database = 'data_2'
1.This will work for ONLY MYSQL 2.For Only ONE PAGE ONE TABLE 3.For Simple use case you will find foo.csv whenever this scipt is used for that perticular table
https://github.com/socialcopsdev/camelot/issues/120
https://colab.research.google.com/drive/1gLEP8M_fCceKJ539Kvme_6fenev_Cfm3#scrollTo=TO_eCo_uYwDV
$ deactivate