Problems with downloading The Pile #5604
Comments
|
Hi! You can specify from datasets import load_dataset, DownloadConfig
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets', download_config=DownloadConfig(resume_download=True)) |
|
@mariosasko , I used your suggestion but its not saving anything , just stops and runs from the same point . |
|
@mariosasko , it shows nothing in dataset folder |
|
|
Users with slow internet speed are doomed (4MB/s). The dataset downloads fine at minimum speed 10MB/s. Also, when the train splits were generated and then I removed the downloads folder to save up disk space, it started redownloading the whole dataset. Is there any way to use the already generated splits instead? |
|
@sentialx @mariosasko , anytime on my above script , am I downloading and saving dataset correctly . Please suggest :) |
|
@sentialx probably worth noting that |
Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
Here are the downloaded files:
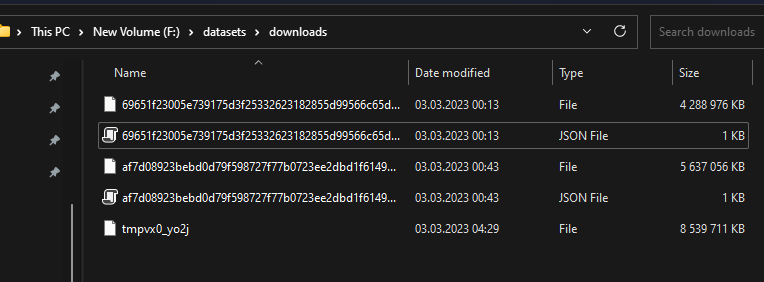
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
Expected behavior
The files should be downloaded correctly.
Environment info
datasetsversion: 2.10.1The text was updated successfully, but these errors were encountered: