Model Hub hanging in model's loading #9518
Comments
|
Adding some more info: The api call returns to the model endpoint {"error":"Model Musixmatch/umberto-wikipedia-uncased-v1 is currently loading","estimated_time":10}Then while the model is loading a new error comes out: Thank you! |
|
pinging @Narsil ! :) |
|
Hi @loretoparisi , Sorry for the delayed answer. The problem was linked to you tokenizer that somehow had a failure when it was transformed automatically into a Fast one. (Actually it worked well, but the result could not be saved properly). I fixed your tokenizer by adding the precomputed result for Fast tokenizer: Everything seems to be working properly now (and loads fast) |
|
@Narsil the inference outputs seem weird though, like the tokenizer doesn't uncase inputs: https://huggingface.co/Musixmatch/umberto-wikipedia-uncased-v1?text=Roma+%C3%A8+la+%3Cmask%3E+d%27Italia
|

|
|
@Narsil thank you for your help, there is anything that we can do/test by our side? cc @simonefrancia |
Sure, this means that there's some missing config for the tokenizer. See this model for example: https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France.
not sure what you mean here. cc @n1t0 |
I can't make any choice about what's more reasonable for the end model, the current tokenizer is exactly what
This: https://github.com/huggingface/moon-landing/blob/master/front/js-src/lib/widgets/text-classification.ts#L45 |
|
@Narsil I think there are several different things going on here:
from transformers import AutoTokenizer, pipeline
def run_input(input):
tok_slow = AutoTokenizer.from_pretrained("Musixmatch/umberto-wikipedia-uncased-v1", use_fast=False)
p_slow = pipeline("fill-mask", model="Musixmatch/umberto-wikipedia-uncased-v1", tokenizer=tok_slow)
ids_slow = tok_slow.encode(input)
p_output_slow = p_slow(input)
tok_fast = AutoTokenizer.from_pretrained("Musixmatch/umberto-wikipedia-uncased-v1", use_fast=True)
p_fast = pipeline("fill-mask", model="Musixmatch/umberto-wikipedia-uncased-v1", tokenizer=tok_fast)
ids_fast = tok_fast.encode(input)
p_output_fast = p_fast(input)
print("Running with input: ", input)
print("SLOW:")
print(ids_slow)
print(p_output_slow)
print("FAST:")
print(ids_fast)
print(p_output_fast)
run_input("Roma è la <mask> d'Italia")
run_input("roma è la <mask> d'italia")Gives the following output: Running with input: Roma è la <mask> d'Italia
SLOW:
[5, 31908, 3, 31912, 79, 97, 51, 32004, 7, 31931, 3, 11007, 6]
[
{'sequence': "<s> <unk>oma è la lingua d'<unk>talia</s>", 'score': 0.04120568186044693, 'token': 1476, 'token_str': '▁lingua'},
{'sequence': "<s> <unk>oma è la città d'<unk>talia</s>", 'score': 0.023448798805475235, 'token': 521, 'token_str': '▁città'},
{'sequence': "<s> <unk>oma è la dea d'<unk>talia</s>", 'score': 0.022841867059469223, 'token': 4591, 'token_str': '▁dea'},
{'sequence': "<s> <unk>oma è la terra d'<unk>talia</s>", 'score': 0.02243848517537117, 'token': 1415, 'token_str': '▁terra'},
{'sequence': "<s> <unk>oma è la capitale d'<unk>talia</s>", 'score': 0.01755419932305813, 'token': 3152, 'token_str': '▁capitale'}
]
FAST:
[1, 31904, 0, 31908, 75, 93, 47, 32001, 3, 31927, 0, 11003, 2]
[
{'sequence': "<s> <unk>oma è laà d'<unk>talia</s>", 'score': 0.4644460380077362, 'token': 31936, 'token_str': 'à'},
{'sequence': "<s> <unk>oma è la<mask> d'<unk>talia</s>", 'score': 0.41339975595474243, 'token': 32001, 'token_str': '<mask>'},
{'sequence': "<s> <unk>oma è laena d'<unk>talia</s>", 'score': 0.02151116542518139, 'token': 408, 'token_str': 'ena'},
{'sequence': "<s> <unk>oma è laè d'<unk>talia</s>", 'score': 0.01422190386801958, 'token': 31935, 'token_str': 'è'},
{'sequence': "<s> <unk>oma è la ten d'<unk>talia</s>", 'score': 0.0057907504960894585, 'token': 685, 'token_str': '▁ten'}
]
Running with input: roma è la <mask> d'italia
SLOW:
[5, 764, 97, 51, 32004, 7, 31931, 31911, 11007, 6]
[
{'sequence': "<s> roma è la bandiera d'italia</s>", 'score': 0.13166911900043488, 'token': 3525, 'token_str': '▁bandiera'},
{'sequence': "<s> roma è la capitale d'italia</s>", 'score': 0.0553407184779644, 'token': 3152, 'token_str': '▁capitale'},
{'sequence': "<s> roma è la nazionale d'italia</s>", 'score': 0.04516282677650452, 'token': 918, 'token_str': '▁nazionale'},
{'sequence': "<s> roma è la zona d'italia</s>", 'score': 0.022440679371356964, 'token': 1740, 'token_str': '▁zona'},
{'sequence': "<s> roma è la regione d'italia</s>", 'score': 0.02204475924372673, 'token': 1472, 'token_str': '▁regione'}
]
FAST:
[1, 760, 93, 47, 32001, 3, 31927, 31907, 11003, 2]
[
{'sequence': "<s> roma è la<mask> d'italia</s>", 'score': 0.9972749352455139, 'token': 32001, 'token_str': '<mask>'},
{'sequence': "<s> roma è laà d'italia</s>", 'score': 0.001777052297256887, 'token': 31936, 'token_str': 'à'},
{'sequence': "<s> roma è la pai d'italia</s>", 'score': 0.00022994846221990883, 'token': 14871, 'token_str': '▁pai'},
{'sequence': "<s> roma è la raffigura d'italia</s>", 'score': 0.00011272338451817632, 'token': 15184, 'token_str': '▁raffigura'},
{'sequence': "<s> roma è la hiv d'italia</s>", 'score': 0.00011238666047574952, 'token': 28952, 'token_str': '▁hiv'}
]As you can see, the output using the slow tokenizer seems fine, while the other doesn't. |
|
Okay this is now fixed: https://huggingface.co/Musixmatch/umberto-wikipedia-uncased-v1/commit/713d59922ccb4b5fc31a527ce2d785c23533363b This 4 offset in the tokens is hardcoded for Camembert based tokenizers : I'm doing a pass on all BPE based spm to check various behaviors. |
|
Hi @Narsil, We see something not usual that replaces token. In this example mask token is not replaced by a single BPE token, but an entire sentence and that sounds strange. |

|
@simonefrancia are you referring to the third result in the screenshot? |
|
@julien-c yes. My doubt is that input sentence is repeated for the third result. |
|
I think it's the widget's intended behavior for BPE when we are not able to display the BPE token by itself. But we can take a look... How are the other results, are they sensible? |
|
I confirm it's the widget because suggested result is len <2, it's trying to repeat the full sentence instead of just the token. |
|
I found other interesting cases, for example this one, when mask is at starting point.
In case we don't specify anything before
Hope this can help you. |
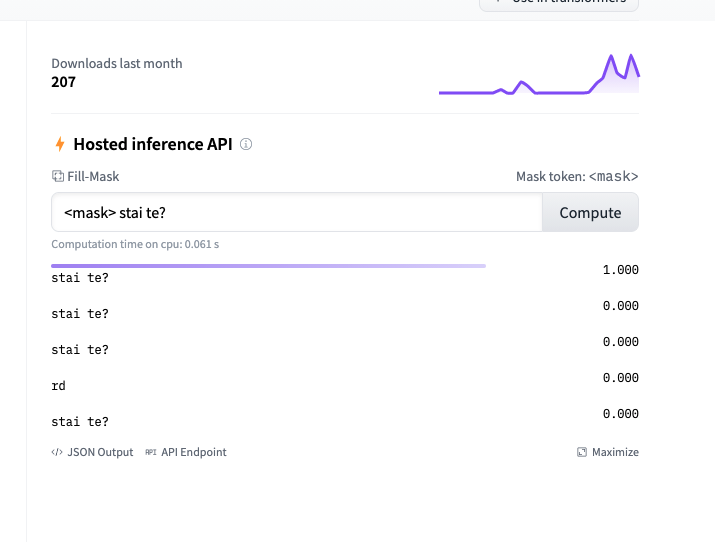

|
@Narsil Ok, but is it possible to force output that would be |
- There is only 1 test currently (tokenizers + slow) that used the modified path and it's reformer, which does not contain any ids modification so the bug was silent for now. - The real issue is that vocab variable was overloaded by SentencePieceExtractor, leading to Slow specific vocab oddities to be completely ignored - The bug was reported here huggingface#9518 - Ran the complete tokenization test suite with slow without error (`RUN_SLOW=1 pytest -sv tests/test_tokenization_*`)
|
Hi @simonefrancia.
As for the widget, a fix is coming (it's really a display issue, if you look at the raw results it should make more sense). |
|
I opened a new issue to keep track of the lowercasing issue as this is something that would probably be helpful for many tokenizers. (cf #10121) I believe everything else has been fixed, has it? |
|
I think so but I'll let @simonefrancia confirm. |
|
for umberto-wikipedia I think that's all, guys. Thanks |
|
Yes it's the same problem. Do you want me to fix it in the same way ? (Hopefully this time it works right off the bat.) Are there any other models that could be under the same flag ? (I detected only this one during my full sweep for your organization) |
|
For our organization, we have only two models, umberto-wikipedia ( the one you fixed) and umberto-commoncrawl ( the one to be fixed). |
…10120) * Conversion from slow to fast for BPE spm vocabs contained an error. - There is only 1 test currently (tokenizers + slow) that used the modified path and it's reformer, which does not contain any ids modification so the bug was silent for now. - The real issue is that vocab variable was overloaded by SentencePieceExtractor, leading to Slow specific vocab oddities to be completely ignored - The bug was reported here #9518 - Ran the complete tokenization test suite with slow without error (`RUN_SLOW=1 pytest -sv tests/test_tokenization_*`) * Remove rebase error. * Adding the fixture.
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
@Narsil when loading some models, the loading hangs at 80-90%.
In this case it's this one.
The text was updated successfully, but these errors were encountered: