This projects utilzies Keras to make predictions on movie genre based on the movie's plot.
There are two notebooks present in the repository:
- Model training/testing done in NLP_Test_Train
- Predictions on holdout set done in Predicting_Holdout_Set

Repository structure:
- All csv's can be found in the /data folder
- All images can be found in the /images folder
Note:
- Pickled data not available in repository due to exceeding github file size limit
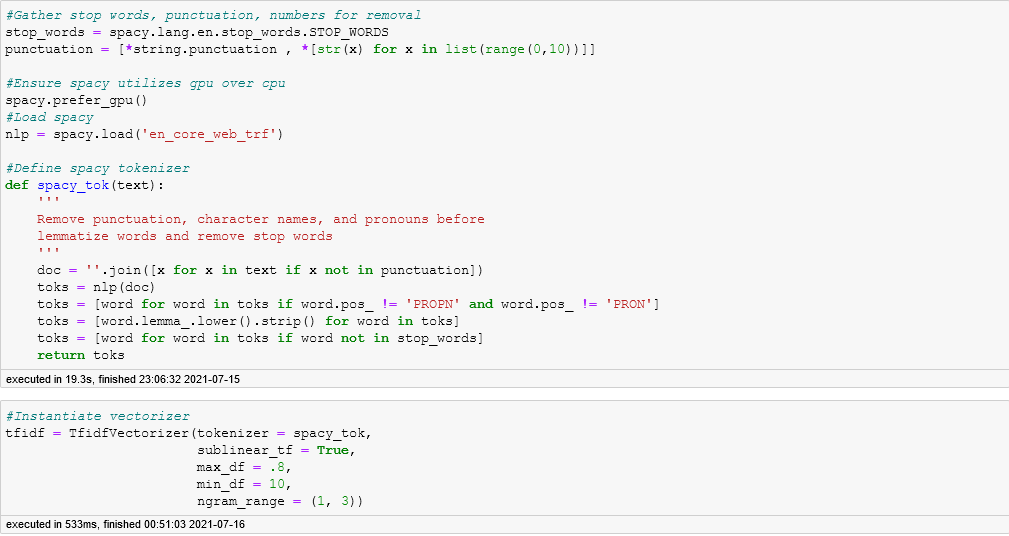
After reading in the data and performing a train/test split I utilize the spacy library to tokenize the documents before utilizing TfidfVectorizer to vectorize the tokens.
The tokenizer function works in the following order:
- Remove punctuations and numbers
- Plot webscraped from Wikipedia, in-text citations in plot
- Turn document into spacy doc
- Remove character names and pronouns
- Lemmatize, lowercase, remove spaces in words
- Remove stop words from document
Following this, I ran a Multinomial Naive Bayes model to serve as the baseline metric.

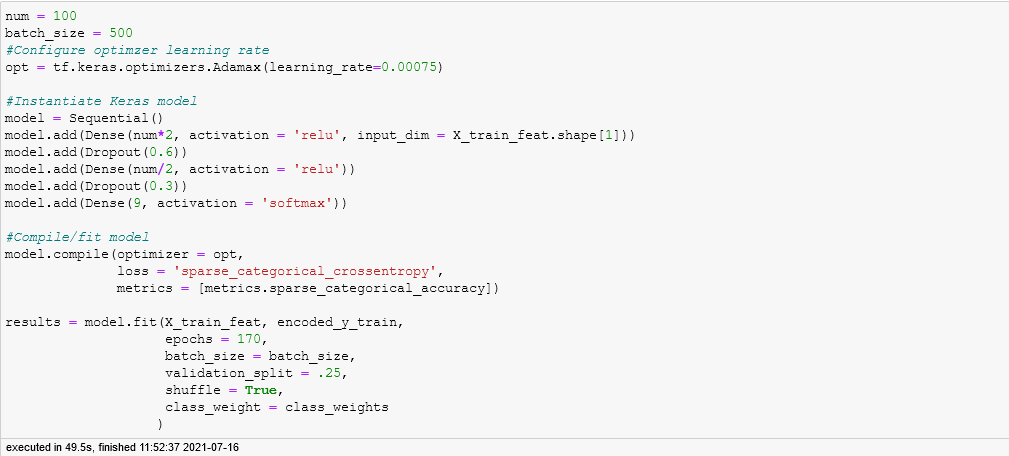
After creating class weights to account for class imbalance, I did minor configurations to tensorflow's internal configurations for gpu usage.
With that, I configured the keras model.
The following configuration was selected to account for:
- Addressing class imbalance between movie genres
- For example: Crime movies accounted for only 3% of the data
- Accounting for overfitting
- Validation accuracy would fall as training set accuracy rose
- Training set metrics lowered in exchange for higher validation score
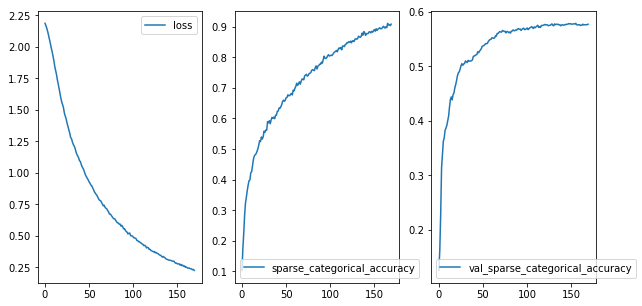
I graphed the loss as well as the sparse categorical accuracy for the training and validation sets with the goal of reducing the training set's accuracy while preventing the validation set's accuracy from dipping.
Following this, I make a prediction on the testing set as well as test its f1 score.

Finally, I take a look at the confusion matrix. Overall, what I am looking for is a defined diagonal going through the middle. The more defined the band, the more accurately the model correctly identified genres.
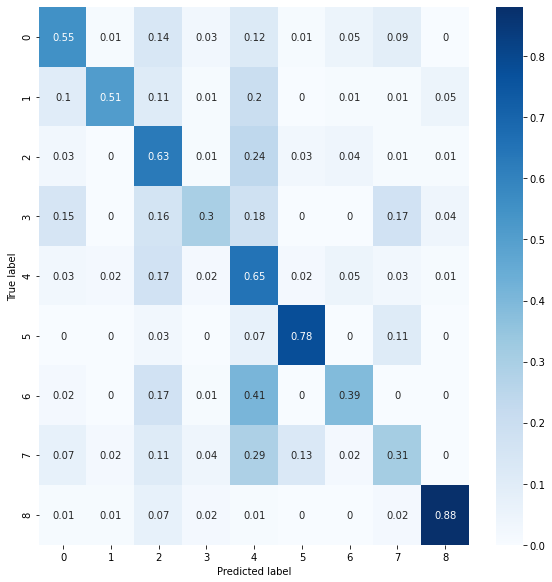
After reviewing the f1 score and confusion matrix, I repeatedly configured the keras settings until satisfied with the results.
Once completed, I made predictions on the holdout set which can be found in the /data folder with the process being within the Predicting_Holdout_set notebook.