This repository contains source code for Weakly supervised 3D Reconstruction with Adversarial Constraint. This is a fork project of our previous work, 3D-R2N2: 3D Recurrent Reconstruction Neural Network. Inspired by visual hull algorithm, we propose to learn 3D reconstruct from 2D silhouettes using backpropable raytrace pooling operation. Additionally, in order to overcome the limitation of visual hull such as concavity, we propose to constrain the reconstruction on unlabeled 3D shapes with adversarial constraint. [Paper][Code][Poster][Slides][Bibtex][Website]
Neural network-based 3D reconstruction requires a large scale annotation of ground-truth 3D model for every 2D image, which is infeasible for real-world application. In this paper, we explore relatively inexpensive 2D supervision as an alternative for expensive 3D CAD annotation.

We propose to learn 3D reconstruction from 2D supervision as following:
- Raytrace Pooling: Inspired by visual hull algorithm, we enforce foreground masks as weak supervision through a raytrace pooling layer that enables perspective projection and backpropagation ((c) in the figure above)
- Adversarial Constraint: Since the 3D reconstruction from masks is an ill posed problem, we propose to constrain the 3D reconstruction to the manifold of unlabeled realistic 3D shapes that match mask observations ((d) in the figure above)
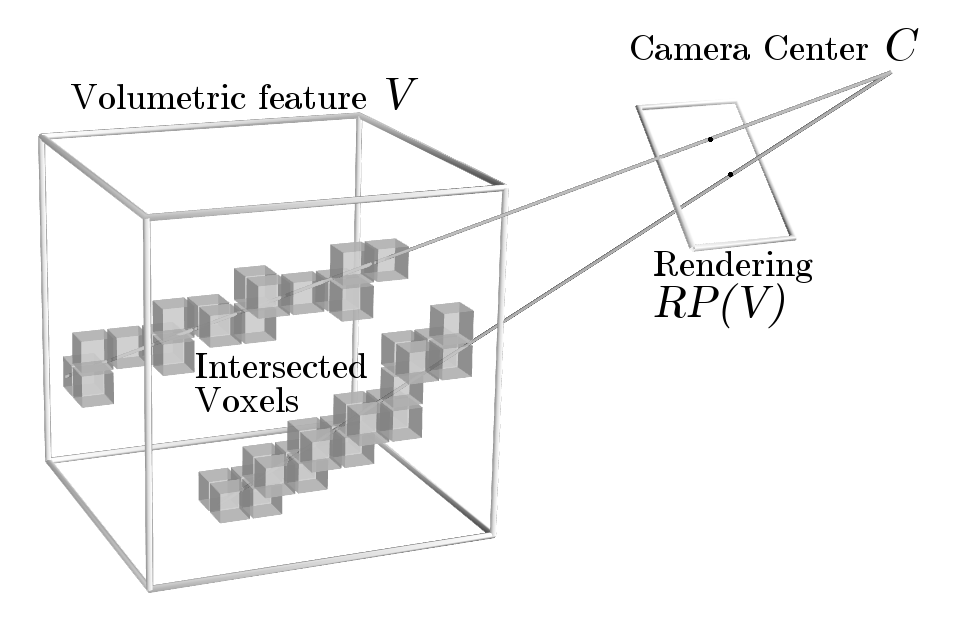
In order to learn 3D shapes from 2D masks, we propose a backpropable raytrace pooling layer. Raytrace pooling layer takes viewpoint and 3D shape as an input and renders a corresponding 2D image, maxpooled across voxels hit through each ray of the pixel, as shown in figure above. This layer efficiently bridges the gap between 2D masks and 3D shapes, allowing us to apply loss inspired by visual hull. Moreover, this is an efficient implementation of true raytracing using voxel-ray hit test. Unlike sampling-based approaches, our implementation does not suffer from aliasing artifacts or sampling hyperparameter tuning.


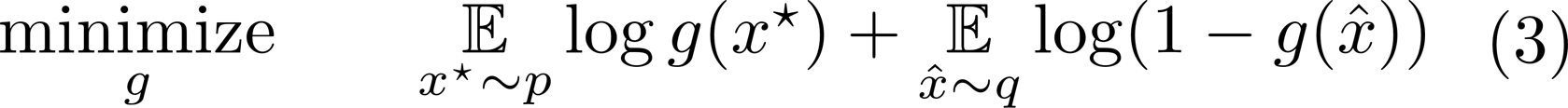
2D mask constraint, unlike full 3D shape constraint, cannot enforce concavity or symmetry, which may be crucial for 3D reconstruction. Therefore, we apply additional constraint so that the network will generate a "valid shape" as in equation (1) above. In order to solve equation (1), in this paper, we demonstrated that a constrained optimization problem can be tackled using GAN-like network structure and loss. Equation (1) can be re-written as equation (2) using log barrier method where g(x)=1 iff reconstruction x is realistic and 0 otherwise. We observed that the ideal discriminator of GAN g*(x), which outputs g*(x)=1 iff reconstruction x is realistic, is analogous to the penalty function g(x). Therefore, we train the constraint using GAN-like adversarial loss, as in equation (3).
This project requires python3. You can follow the direction below to install virtual environment within the repository or install anaconda for python 3.
- Download the repository
git clone https://github.com/jgwak/McRecon.git- Setup virtual environment and install requirements and copy the theanorc file to the
$HOMEdirectory
cd McRecon
pip install virtualenv
virtualenv -p python3 --system-site-packages py3
source py3/bin/activate
pip install -r requirements.txt
cp .theanorc ~/.theanorccuDNN may significantly accelerate Theano and is highly recommended for training. To use cuDNN library, you have to download cuDNN from the nvidia website. Then, extract the files to any directory and append the directory to the environment variables like the following. Please replace the /path/to/cuDNN/ to the directory that you extracted cuDNN.
export LD_LIBRARY_PATH=/path/to/cuDNN/lib64:$LD_LIBRARY_PATH
export CPATH=/path/to/cuDNN/include:$CPATH
export LIBRARY_PATH=/path/to/cuDNN/lib64:$LD_LIBRARY_PATHFor more details, please refer to http://deeplearning.net/software/theano/library/sandbox/cuda/dnn.html
- Install meshlab (skip if you have another mesh viewer). If you skip this step, demo code will not visualize the final prediction.
sudo apt-get install meshlab
- Run the demo code and save the final 3D reconstruction to a mesh file named
prediction.obj
python demo.py prediction.obj
The demo code takes 3 images of the same chair and generates the following reconstruction.
| Image 1 | Image 2 | Image 3 | Reconstruction |
|---|---|---|---|
 |
 |
 |
 |
Please note that our network successfully reconstructed concavity, which cannot be learned from mask consistency loss.
- Deactivate your environment when you are done
deactivate
- Activate the virtual environment before you run the experiments.
source py3/bin/activate
- Download datasets and place them in a folder named
ShapeNet
mkdir ShapeNet/
wget ftp://cs.stanford.edu/cs/cvgl/ShapeNetRendering.tgz
wget ftp://cs.stanford.edu/cs/cvgl/ShapeNetVox32.tgz
tar -xzf ShapeNetRendering.tgz -C ShapeNet/
tar -xzf ShapeNetVox32.tgz -C ShapeNet/
- Train and test the network using the training shell script
./experiments/script/gan_mask_net.sh
Note: It takes a long time (up to 30 minutes) for the network model to compile and start running.
If you find our work helpful, please cite it with the following bibtex.
@inproceedings{gwak2017weakly,
title={Weakly supervised 3D Reconstruction with Adversarial Constraint},
author={Gwak, JunYoung and Choy, Christopher B and Chandraker, Manmohan and Garg, Animesh and Savarese, Silvio},
booktitle = {3D Vision (3DV), 2017 Fifth International Conference on 3D Vision},
year={2017}
}
MIT License
Original work by Christopher B. Choy
Modified work by JunYoung Gwak