{kind=link}
Our website FoodiePal is a “local yelp” website that provides information about Restaurants located at Urbana-Champaign. Users can perform search by restaurant name or category name, review restaurants and get personalized recommendations based on past reviews. By viewing ratings and reviews as well as giving their preferences, people will be able to find just the business that they are looking for powered by our intelligent recommandation system.
- Note the recommandation feature requires the R script to be running on a server to process the user request. We used our own vm to run as server for demo purpose but the recommand button does not respond now since we cannot keep the vm open at all time. To see what the recommandation system looks like, check out our youtube demo:
[ youtube demo ] : ( https://www.youtube.com/watch?v=TcmCx8wilck)


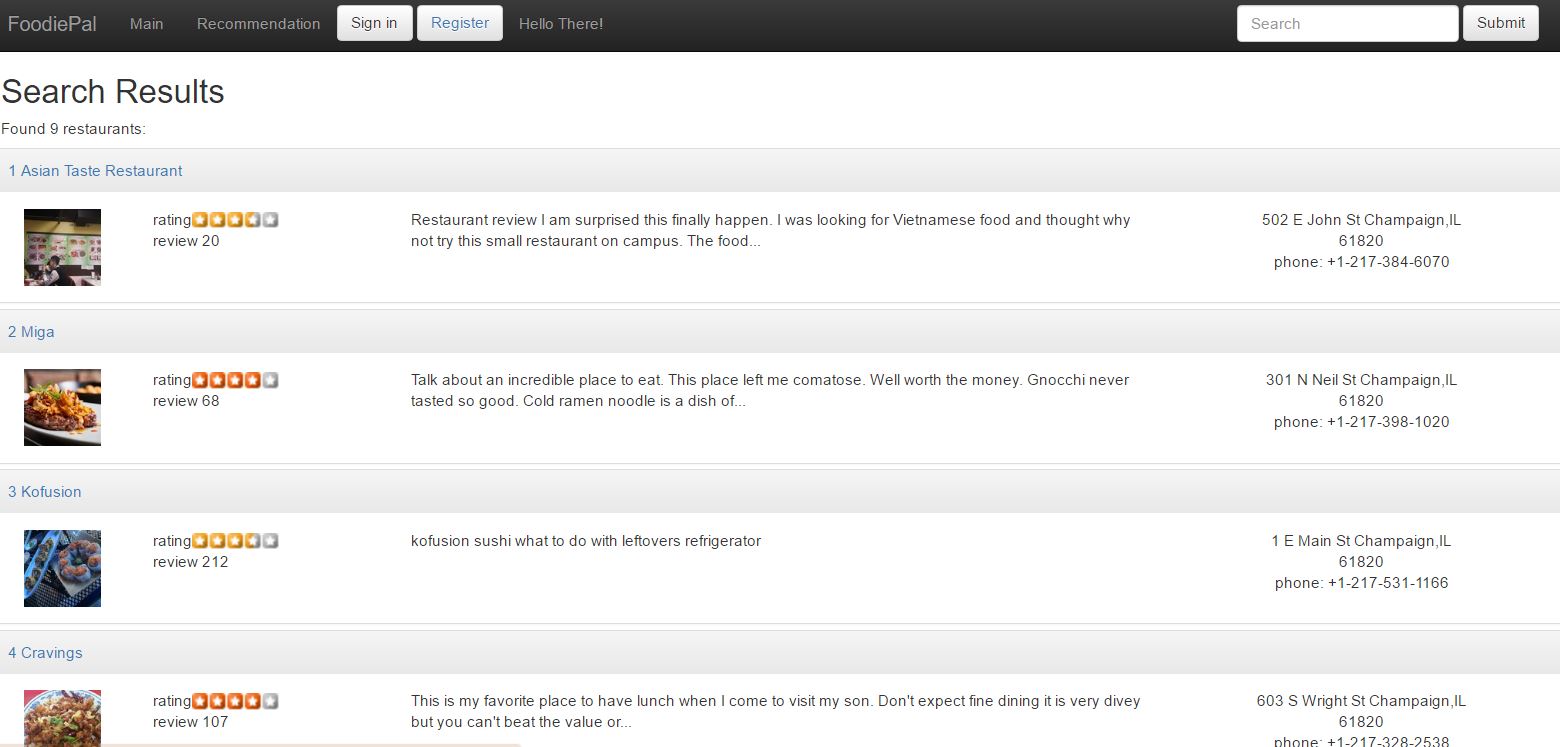


FoodiePal not only provides quick and easy restaurant information look-up (such as location on map, short description, average rating), but also recommends eatery choices based on past reviews through trained machine learning model.
We accessed Yelp’s API (https://www.yelp.com/developers/) using code in python and filtered out informations of 200+ local restaurants and their reviews. For the purpose of machine learning, I found larger datasets released by Yelp. There are three json files for this part: businesses, reviews and users. We also get the info from the user register page. When the user registers for an account on our website, we will store the user’s personal information, such as name, gender and etc.
We then added necessary tables that enable mapping of keys between tables. For more information, see our ER diagram below.
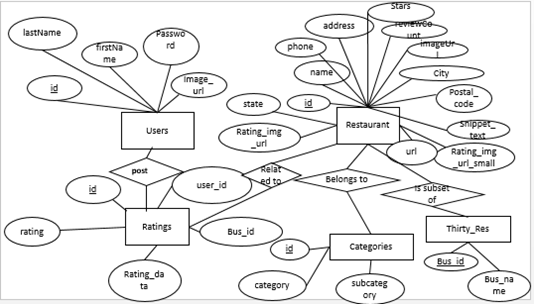
Categories(id,category,subcategory,class_tag,class_tag2) Ratings(id,user_id,bus_id,rating,rating_date) Restaurant(id,name,phone,address,stars,reviewCount,imageUrl,city,postal_code,snippet_text,state,rating_img_url,rating_img_url_small,url) Restaurant_Categories(rid,cid) thirty_Rest(bus_id,bus_name) Users(id,firstName,lastName,password,image_url)
A smart recommendation feature collects and makes use of our website user’s review history. Because our website only holds information on local restaurants and Yelp’s API only provides one review per business, we are unable to train our model on local restaurants. We found good datasets about a few cities released by Yelp. We wanted to identify a fair way of predicting user’s preference for a restaurant. Finally we decided to analyze and predict user’s preference for each categories since the Yelp’s categories are almost shared by the machine learning dataset and API’s dataset. With this information in mind and as well as what categories each restaurant has, we can calculate the preference users would have for all 200+ restaurants. Finally, we output the top 20 ones as our recommendation.
- 11537 businesses with 500 + categories, reduced to 5400 restaurants with 109 categories related to restaurants, restaurants have star ratings
- 171296 reviews with ratings by 43876 users
Firstly, we want to study the distance between categories and cluster them in order to reduce dimensions of data we are dealing with. Our motivation of clustering categories is as below:
Basically as mentioned in the summary, we want a way to represent some User u’s preference on categories. We can easily figure out a way to obtain from past ratings a 109 dimension vector V for each User u, each dimension representing u’s preference on one category (recall there are 109 categories). For example, we can increment one count for category n, if User u rated a Restaurant B who has tag/category n. We can add weight to the count according to (this review’s rating – this B’s average rating). But with such big dimension along with few reviews, we will get very sparse vector which isn’t informing nor desirable.
We constructed a 109 * 109 “covariance” matrix X, with entry X[i, j] = X[j, i] denoting the correlation between category i and j, i.e. more positive value means higher likelihood of users who prefers one of the two categories also prefers the other category.
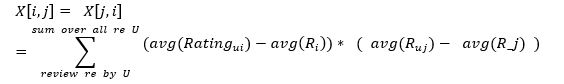 Divided by total # of users whose reviews involved both categories i& j
Divided by total # of users whose reviews involved both categories i& j
*we adopt the term covariance and correlation loosely here because we didn’t standardize it
Below is a visual representation of the distance matrix,

Convert this covariance matrix into distance matrix: each entry = (9 - each entry)/2. We then can perform k-median (more suitable than k-mean in this case) to cluster categories into 9 classes. Just for fun, we attached the hierarchy clustering result using the distance matrix. We used result from k-median because it’s hard to pick k for hierarchy clustering and it is ambiguous where the cluster broader is.

We mapped categories in our database to 109 categories in above dataset. Then given a new user’s review history, based on it we can initialize 109-D vector, each entry representing user’s rating bias comparing to all users’ reviews for this category. We perform regression referring to distance matrix X to get full vector of it (since the original one is sparse based on few reviews). We can then calculate the scores based on category ratings for each of 200 + restaurants and output the top 20 ones.
One technical challenge is how to integrate our R code that trains machine learning code into our website. We processed relatively large datasets locally using R code and we’re able to save the R environment that contains the trained model so we don’t have to repeat training each time a new user asks for recommendations. However, we had trouble integrating it into PHP while using Cpanel, which doesn’t seem to support R. We thought of using Microsoft Azure Machine Learning Api, where we can save our model and employ it as a web service. But Azure’s Api has many restrictions and specific formats that we need to follow when transporting data to and from it. Moreover, R is picky about its input data type also. We finally gave up on that when Azure seems to be having bugs within that is causing it to have extremely long responding time. We ended up using a VM provided by school as a “server” and our recommand.php sends request to the server using TCP protocol. The general idea is that when server receives recommendation request from us using TCP, it parses the received buffer which contains the user’s past ratings and the corresponding business ids. It then runs the R code, and using the csv files exported from our database to get the necessary information about our restaurants. The server calculates the top 20 restaurant ids of restaurants most likely to be liked by the user and then send back the ids as a comma separated string back to the PHP. However, this leads to a problem that our website can only performs this process when the TCP server python script written on the VM is run. Once we log out, we cannot access to the server. We are looking for free server service online, and hopefully we’ll transport our code there soon.
- Front End: Xinyao Huang, Jingjing Huang
- Back End: Jiayu Chen, Chenying He
- Back End and Front End Connection: Jiayu Chen, Xinyao Huang
- Advanced functions:
- Machine Learning: Jiayu Chen, Chenying He
- Fuzzy Search: Xinyao Huang, Jingjing Huang